 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngineering Serendipity through Recommendations of Items with Atypical Aspects
May 29, 2025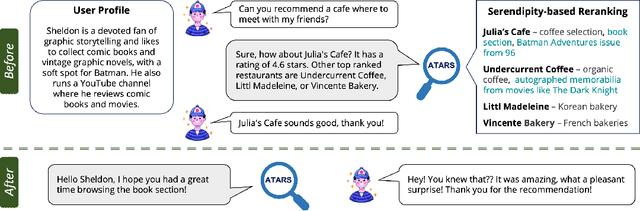
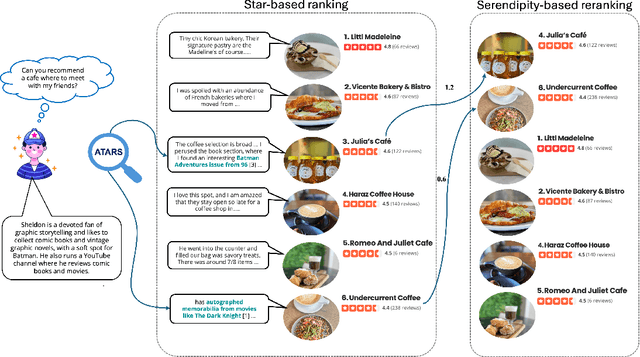

A restaurant dinner or a hotel stay may lead to memorable experiences when guests encounter unexpected aspects that also match their interests. For example, an origami-making station in the waiting area of a restaurant may be both surprising and enjoyable for a customer who is passionate about paper crafts. Similarly, an exhibit of 18th century harpsichords would be atypical for a hotel lobby and likely pique the interest of a guest who has a passion for Baroque music. Motivated by this insight, in this paper we introduce the new task of engineering serendipity through recommendations of items with atypical aspects. We describe an LLM-based system pipeline that extracts atypical aspects from item reviews, then estimates and aggregates their user-specific utility in a measure of serendipity potential that is used to rerank a list of items recommended to the user. To facilitate system development and evaluation, we introduce a dataset of Yelp reviews that are manually annotated with atypical aspects and a dataset of artificially generated user profiles, together with crowdsourced annotations of user-aspect utility values. Furthermore, we introduce a custom procedure for dynamic selection of in-context learning examples, which is shown to improve LLM-based judgments of atypicality and utility. Experimental evaluations show that serendipity-based rankings generated by the system are highly correlated with ground truth rankings for which serendipity scores are computed from manual annotations of atypical aspects and their user-dependent utility. Overall, we hope that the new recommendation task and the associated system presented in this paper catalyze further research into recommendation approaches that go beyond accuracy in their pursuit of enhanced user satisfaction. The datasets and the code are made publicly available at https://github.com/ramituncc49er/ATARS .
Extraction of Atypical Aspects from Customer Reviews: Datasets and Experiments with Language Models
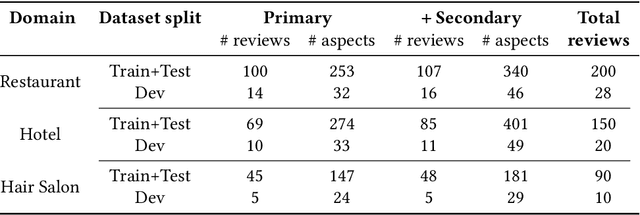
Nov 05, 2023A restaurant dinner may become a memorable experience due to an unexpected aspect enjoyed by the customer, such as an origami-making station in the waiting area. If aspects that are atypical for a restaurant experience were known in advance, they could be leveraged to make recommendations that have the potential to engender serendipitous experiences, further increasing user satisfaction. Although relatively rare, whenever encountered, atypical aspects often end up being mentioned in reviews due to their memorable quality. Correspondingly, in this paper we introduce the task of detecting atypical aspects in customer reviews. To facilitate the development of extraction models, we manually annotate benchmark datasets of reviews in three domains - restaurants, hotels, and hair salons, which we use to evaluate a number of language models, ranging from fine-tuning the instruction-based text-to-text transformer Flan-T5 to zero-shot and few-shot prompting of GPT-3.5.
Can Language Models Employ the Socratic Method? Experiments with Code Debugging
Oct 04, 2023When employing the Socratic method of teaching, instructors guide students toward solving a problem on their own rather than providing the solution directly. While this strategy can substantially improve learning outcomes, it is usually time-consuming and cognitively demanding. Automated Socratic conversational agents can augment human instruction and provide the necessary scale, however their development is hampered by the lack of suitable data for training and evaluation. In this paper, we introduce a manually created dataset of multi-turn Socratic advice that is aimed at helping a novice programmer fix buggy solutions to simple computational problems. The dataset is then used for benchmarking the Socratic debugging abilities of a number of language models, ranging from fine-tuning the instruction-based text-to-text transformer Flan-T5 to zero-shot and chain of thought prompting of the much larger GPT-4. The code and datasets are made freely available for research at the link below. https://github.com/taisazero/socratic-debugging-benchmark
A Survey on Artificial Intelligence for Source Code: A Dialogue Systems Perspective
Feb 10, 2022In this survey paper, we overview major deep learning methods used in Natural Language Processing (NLP) and source code over the last 35 years. Next, we present a survey of the applications of Artificial Intelligence (AI) for source code, also known as Code Intelligence (CI) and Programming Language Processing (PLP). We survey over 287 publications and present a software-engineering centered taxonomy for CI placing each of the works into one category describing how it best assists the software development cycle. Then, we overview the field of conversational assistants and their applications in software engineering and education. Lastly, we highlight research opportunities at the intersection of AI for code and conversational assistants and provide future directions for researching conversational assistants with CI capabilities.
Can We Generate Shellcodes via Natural Language? An Empirical Study
Feb 08, 2022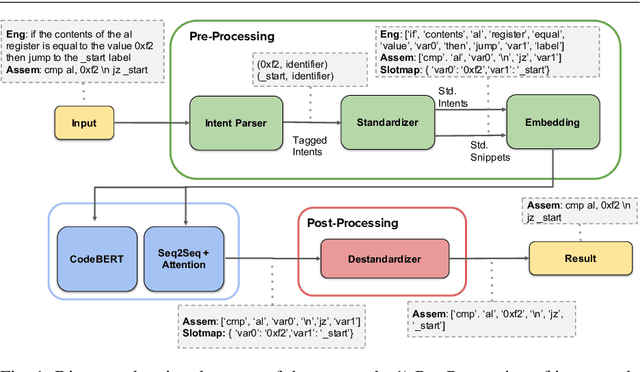


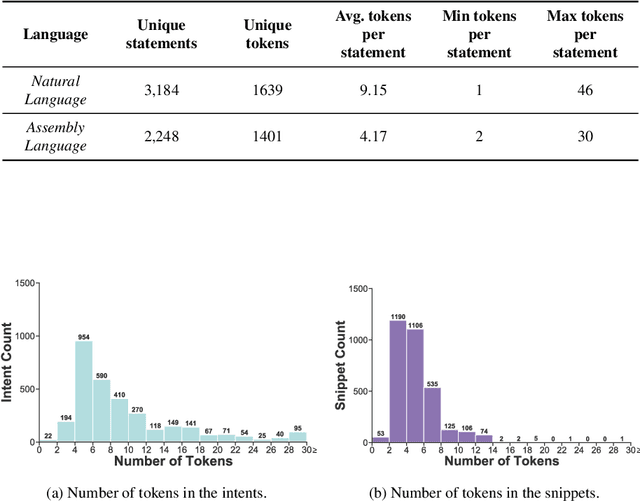
Writing software exploits is an important practice for offensive security analysts to investigate and prevent attacks. In particular, shellcodes are especially time-consuming and a technical challenge, as they are written in assembly language. In this work, we address the task of automatically generating shellcodes, starting purely from descriptions in natural language, by proposing an approach based on Neural Machine Translation (NMT). We then present an empirical study using a novel dataset (Shellcode_IA32), which consists of 3,200 assembly code snippets of real Linux/x86 shellcodes from public databases, annotated using natural language. Moreover, we propose novel metrics to evaluate the accuracy of NMT at generating shellcodes. The empirical analysis shows that NMT can generate assembly code snippets from the natural language with high accuracy and that in many cases can generate entire shellcodes with no errors.
Shellcode_IA32: A Dataset for Automatic Shellcode Generation
Apr 27, 2021

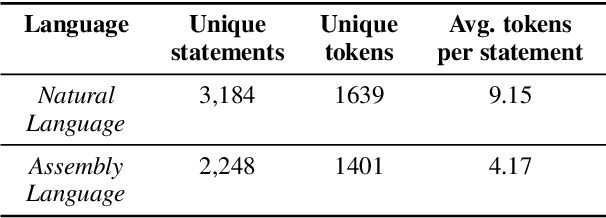
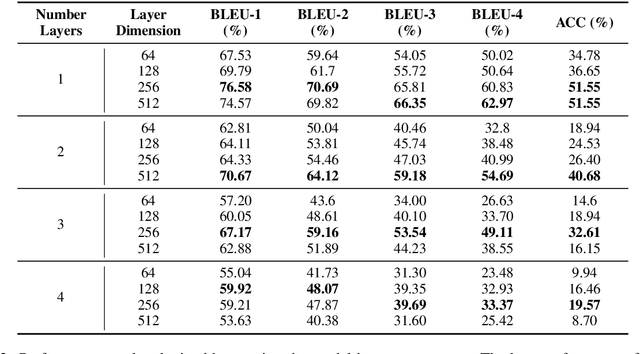
We take the first step to address the task of automatically generating shellcodes, i.e., small pieces of code used as a payload in the exploitation of a software vulnerability, starting from natural language comments. We assemble and release a novel dataset (Shellcode_IA32), consisting of challenging but common assembly instructions with their natural language descriptions. We experiment with standard methods in neural machine translation (NMT) to establish baseline performance levels on this task.