 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Inference-time Scaling and Steering of Diffusion Models
Jan 16, 2025



Diffusion models produce impressive results in modalities ranging from images and video to protein design and text. However, generating samples with user-specified properties remains a challenge. Recent research proposes fine-tuning models to maximize rewards that capture desired properties, but these methods require expensive training and are prone to mode collapse. In this work, we propose Feynman Kac (FK) steering, an inference-time framework for steering diffusion models with reward functions. FK steering works by sampling a system of multiple interacting diffusion processes, called particles, and resampling particles at intermediate steps based on scores computed using functions called potentials. Potentials are defined using rewards for intermediate states and are selected such that a high value indicates that the particle will yield a high-reward sample. We explore various choices of potentials, intermediate rewards, and samplers. We evaluate FK steering on text-to-image and text diffusion models. For steering text-to-image models with a human preference reward, we find that FK steering a 0.8B parameter model outperforms a 2.6B parameter fine-tuned model on prompt fidelity, with faster sampling and no training. For steering text diffusion models with rewards for text quality and specific text attributes, we find that FK steering generates lower perplexity, more linguistically acceptable outputs and enables gradient-free control of attributes like toxicity. Our results demonstrate that inference-time scaling and steering of diffusion models, even with off-the-shelf rewards, can provide significant sample quality gains and controllability benefits. Code is available at https://github.com/zacharyhorvitz/Fk-Diffusion-Steering .
Are LLMs Prescient? A Continuous Evaluation using Daily News as the Oracle
Nov 13, 2024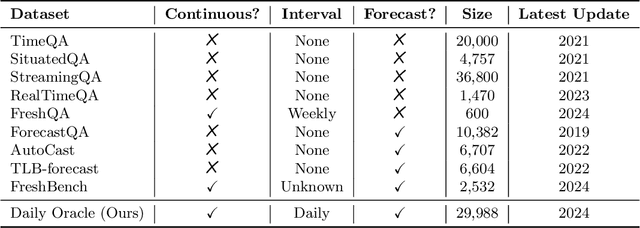
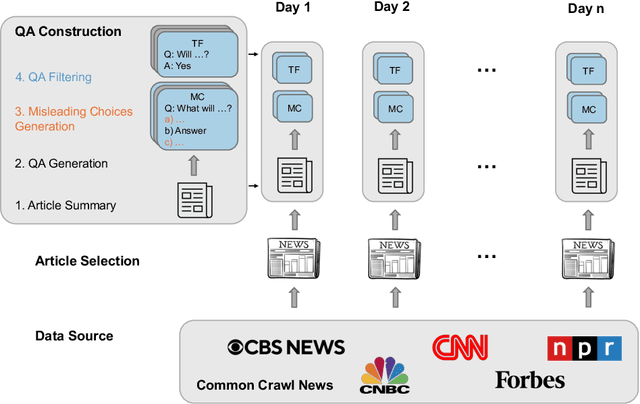
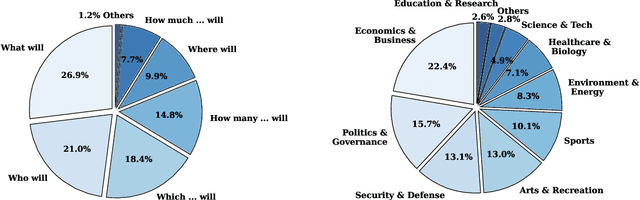
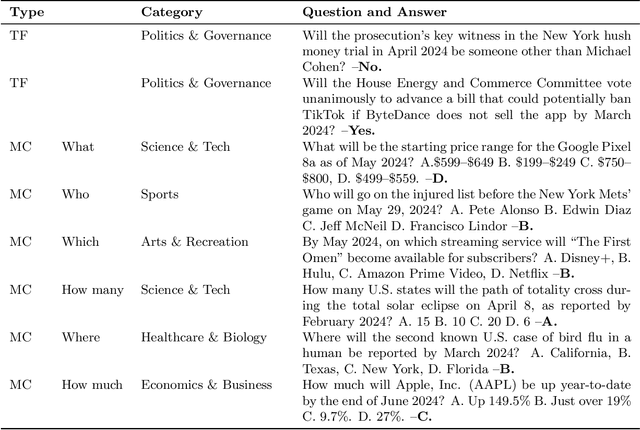
Many existing evaluation benchmarks for Large Language Models (LLMs) quickly become outdated due to the emergence of new models and training data. These benchmarks also fall short in assessing how LLM performance changes over time, as they consist of static questions without a temporal dimension. To address these limitations, we propose using future event prediction as a continuous evaluation method to assess LLMs' temporal generalization and forecasting abilities. Our benchmark, Daily Oracle, automatically generates question-answer (QA) pairs from daily news, challenging LLMs to predict "future" event outcomes. Our findings reveal that as pre-training data becomes outdated, LLM performance degrades over time. While Retrieval Augmented Generation (RAG) has the potential to enhance prediction accuracy, the performance degradation pattern persists, highlighting the need for continuous model updates.
ProCreate, Don't Reproduce! Propulsive Energy Diffusion for Creative Generation
Aug 06, 2024
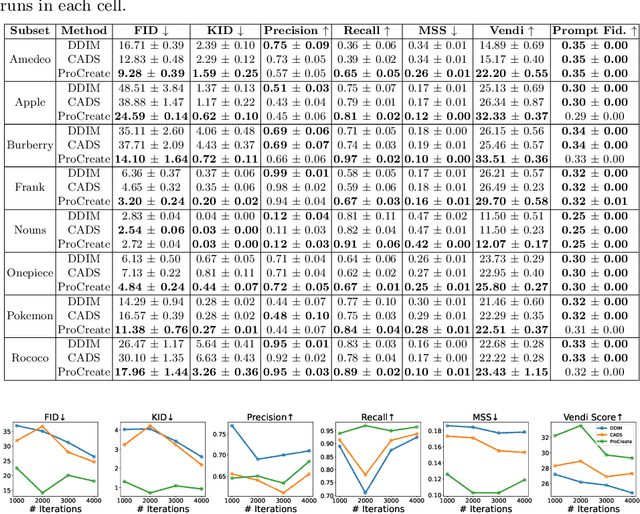
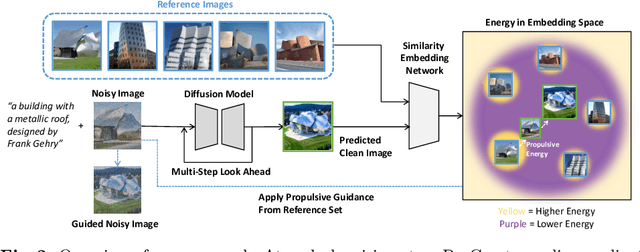
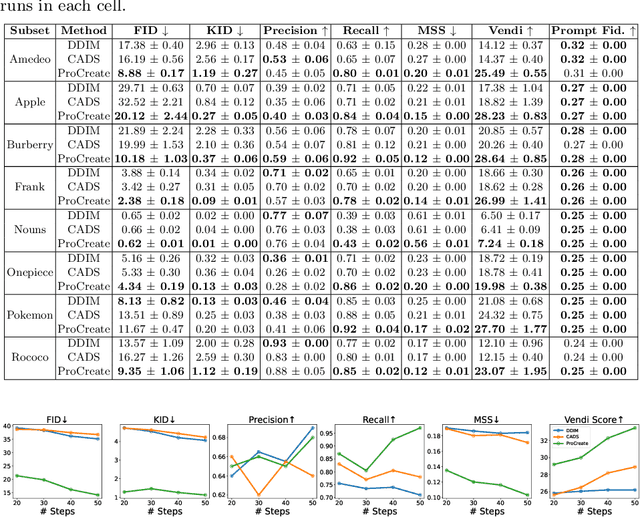
In this paper, we propose ProCreate, a simple and easy-to-implement method to improve sample diversity and creativity of diffusion-based image generative models and to prevent training data reproduction. ProCreate operates on a set of reference images and actively propels the generated image embedding away from the reference embeddings during the generation process. We propose FSCG-8 (Few-Shot Creative Generation 8), a few-shot creative generation dataset on eight different categories -- encompassing different concepts, styles, and settings -- in which ProCreate achieves the highest sample diversity and fidelity. Furthermore, we show that ProCreate is effective at preventing replicating training data in a large-scale evaluation using training text prompts. Code and FSCG-8 are available at https://github.com/Agentic-Learning-AI-Lab/procreate-diffusion-public. The project page is available at https://procreate-diffusion.github.io.
CoLLEGe: Concept Embedding Generation for Large Language Models
Mar 22, 2024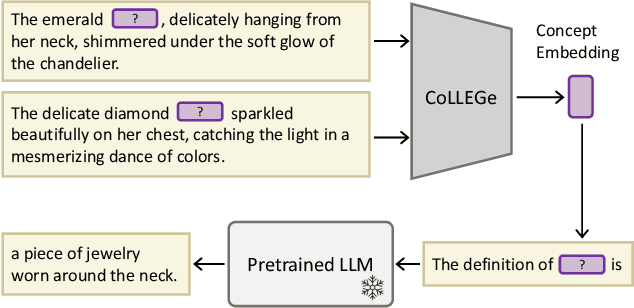

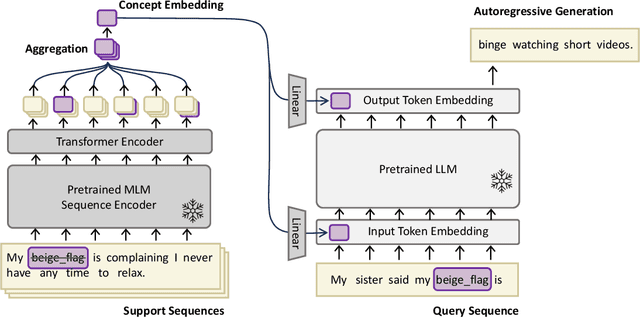

Current language models are unable to quickly learn new concepts on the fly, often requiring a more involved finetuning process to learn robustly. Prompting in-context is not robust to context distractions, and often fails to confer much information about the new concepts. Classic methods for few-shot word learning in NLP, relying on global word vectors, are less applicable to large language models. In this paper, we introduce a novel approach named CoLLEGe (Concept Learning with Language Embedding Generation) to modernize few-shot concept learning. CoLLEGe is a meta-learning framework capable of generating flexible embeddings for new concepts using a small number of example sentences or definitions. Our primary meta-learning objective is simply to facilitate a language model to make next word predictions in forthcoming sentences, making it compatible with language model pretraining. We design a series of tasks to test new concept learning in challenging real-world scenarios, including new word acquisition, definition inference, and verbal reasoning, and demonstrate that our method succeeds in each setting without task-specific training.
Can Language Models Employ the Socratic Method? Experiments with Code Debugging
Oct 04, 2023When employing the Socratic method of teaching, instructors guide students toward solving a problem on their own rather than providing the solution directly. While this strategy can substantially improve learning outcomes, it is usually time-consuming and cognitively demanding. Automated Socratic conversational agents can augment human instruction and provide the necessary scale, however their development is hampered by the lack of suitable data for training and evaluation. In this paper, we introduce a manually created dataset of multi-turn Socratic advice that is aimed at helping a novice programmer fix buggy solutions to simple computational problems. The dataset is then used for benchmarking the Socratic debugging abilities of a number of language models, ranging from fine-tuning the instruction-based text-to-text transformer Flan-T5 to zero-shot and chain of thought prompting of the much larger GPT-4. The code and datasets are made freely available for research at the link below. https://github.com/taisazero/socratic-debugging-benchmark
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Multitask Prompted Training Enables Zero-Shot Task Generalization
Oct 15, 2021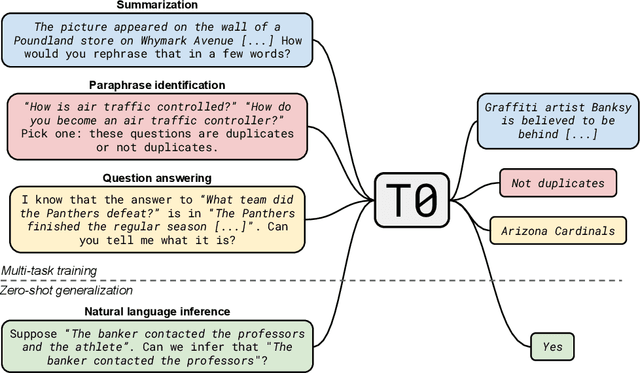

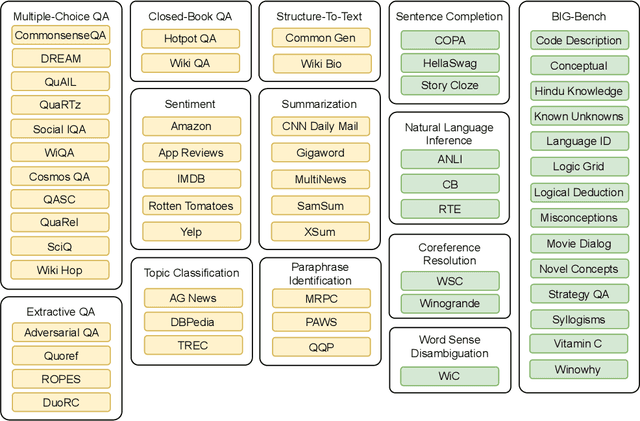

Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at github.com/bigscience-workshop/promptsource/.
Cut the CARP: Fishing for zero-shot story evaluation
Oct 08, 2021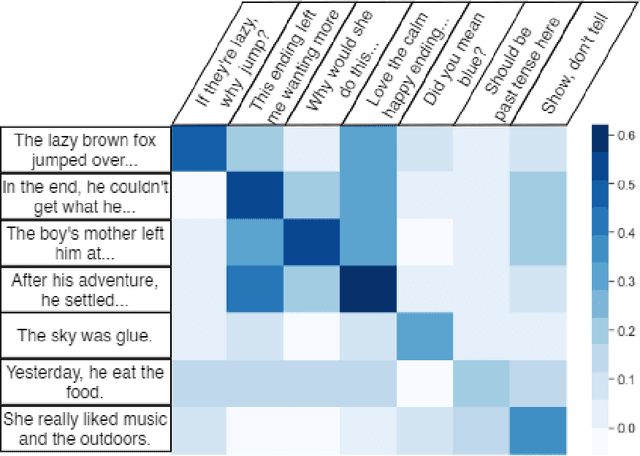

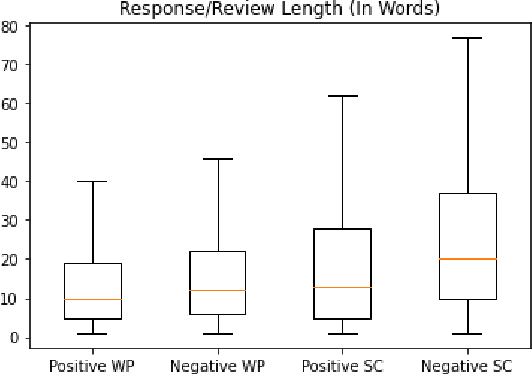

Recent advances in large-scale language models (Raffel et al., 2019; Brown et al., 2020) have brought significant qualitative and quantitative improvements in machine-driven text generation. Despite this, generation and evaluation of machine-generated narrative text remains a challenging problem. Objective evaluation of computationally-generated stories may be prohibitively expensive, require meticulously annotated datasets, or may not adequately measure the logical coherence of a generated story's narratological structure. Informed by recent advances in contrastive learning (Radford et al., 2021), we present Contrastive Authoring and Reviewing Pairing (CARP): a scalable, efficient method for performing qualitatively superior, zero-shot evaluation of stories. We show a strong correlation between human evaluation of stories and those of CARP. Model outputs more significantly correlate with corresponding human input than those language-model based methods which utilize finetuning or prompt engineering approaches. We also present and analyze the Story-Critique Dataset, a new corpora composed of 1.3 million aligned story-critique pairs derived from over 80,000 stories. We expect this corpus to be of interest to NLP researchers.