 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMBAT: Conditional World Models for Behavioral Agent Training
Feb 28, 2026Recent advances in video generation have spurred the development of world models capable of simulating 3D-consistent environments and interactions with static objects. However, a significant limitation remains in their ability to model dynamic, reactive agents that can intelligently influence and interact with the world. To address this gap, we introduce COMBAT, a real-time, action-controlled world model trained on the complex 1v1 fighting game Tekken 3. Our work demonstrates that diffusion models can successfully simulate a dynamic opponent that reacts to player actions, learning its behavior implicitly. Our approach utilizes a 1.2 billion parameter Diffusion Transformer, conditioned on latent representations from a deep compression autoencoder. We employ state-of-the-art techniques, including causal distillation and diffusion forcing, to achieve real-time inference. Crucially, we observe the emergence of sophisticated agent behavior by training the model solely on single-player inputs, without any explicit supervision for the opponent's policy. Unlike traditional imitation learning methods, which require complete action labels, COMBAT learns effectively from partially observed data to generate responsive behaviors for a controllable Player 1. We present an extensive study and introduce novel evaluation methods to benchmark this emergent agent behavior, establishing a strong foundation for training interactive agents within diffusion-based world models.
The Goofus & Gallant Story Corpus for Practical Value Alignment
Jan 16, 2025

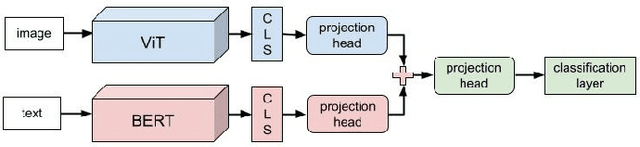
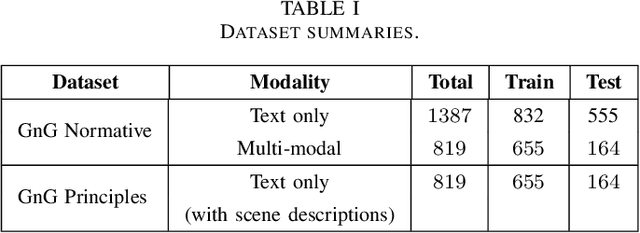
Values or principles are key elements of human society that influence people to behave and function according to an accepted standard set of social rules to maintain social order. As AI systems are becoming ubiquitous in human society, it is a major concern that they could violate these norms or values and potentially cause harm. Thus, to prevent intentional or unintentional harm, AI systems are expected to take actions that align with these principles. Training systems to exhibit this type of behavior is difficult and often requires a specialized dataset. This work presents a multi-modal dataset illustrating normative and non-normative behavior in real-life situations described through natural language and artistic images. This training set contains curated sets of images that are designed to teach young children about social principles. We argue that this is an ideal dataset to use for training socially normative agents given this fact.
Machine Learning Approaches for Principle Prediction in Naturally Occurring Stories
Nov 19, 2022
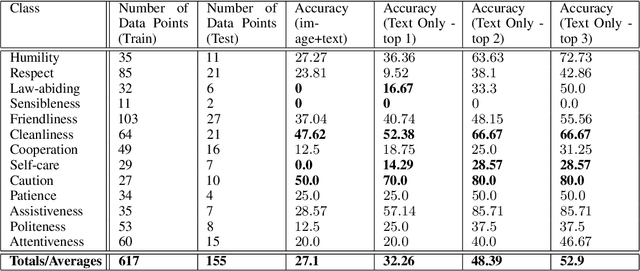


Value alignment is the task of creating autonomous systems whose values align with those of humans. Past work has shown that stories are a potentially rich source of information on human values; however, past work has been limited to considering values in a binary sense. In this work, we explore the use of machine learning models for the task of normative principle prediction on naturally occurring story data. To do this, we extend a dataset that has been previously used to train a binary normative classifier with annotations of moral principles. We then use this dataset to train a variety of machine learning models, evaluate these models and compare their results against humans who were asked to perform the same task. We show that while individual principles can be classified, the ambiguity of what "moral principles" represent, poses a challenge for both human participants and autonomous systems which are faced with the same task.
Robust Preference Learning for Storytelling via Contrastive Reinforcement Learning
Oct 14, 2022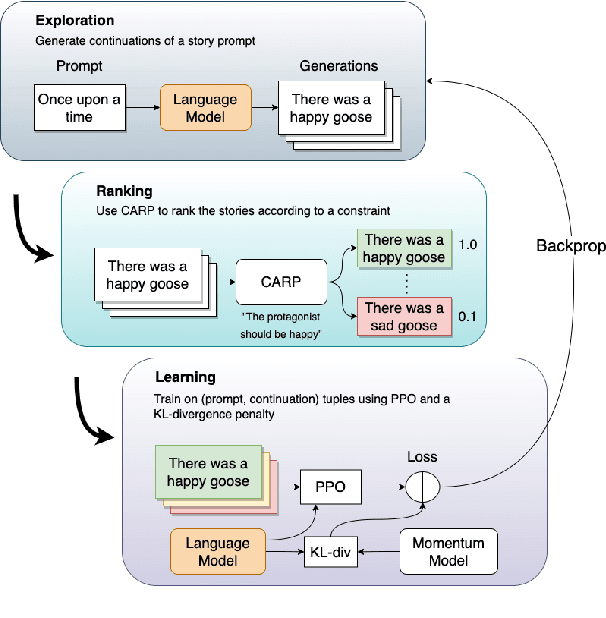

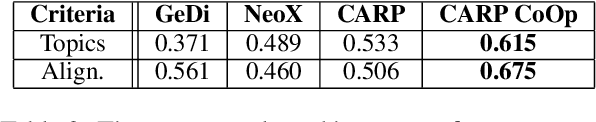
Controlled automated story generation seeks to generate natural language stories satisfying constraints from natural language critiques or preferences. Existing methods to control for story preference utilize prompt engineering which is labor intensive and often inconsistent. They may also use logit-manipulation methods which require annotated datasets to exist for the desired attributes. To address these issues, we first train a contrastive bi-encoder model to align stories with corresponding human critiques, named CARP, building a general purpose preference model. This is subsequently used as a reward function to fine-tune a generative language model via reinforcement learning. However, simply fine-tuning a generative language model with a contrastive reward model does not always reliably result in a story generation system capable of generating stories that meet user preferences. To increase story generation robustness we further fine-tune the contrastive reward model using a prompt-learning technique. A human participant study is then conducted comparing generations from our full system, ablations, and two baselines. We show that the full fine-tuning pipeline results in a story generator preferred over a LLM 20x as large as well as logit-based methods. This motivates the use of contrastive learning for general purpose human preference modeling.
Automated Story Generation as Question-Answering
Dec 07, 2021
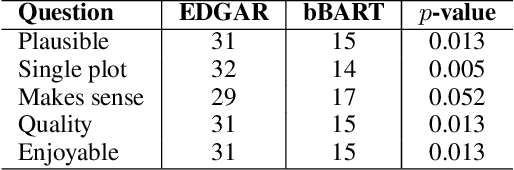
Neural language model-based approaches to automated story generation suffer from two important limitations. First, language model-based story generators generally do not work toward a given goal or ending. Second, they often lose coherence as the story gets longer. We propose a novel approach to automated story generation that treats the problem as one of generative question-answering. Our proposed story generation system starts with sentences encapsulating the final event of the story. The system then iteratively (1) analyzes the text describing the most recent event, (2) generates a question about "why" a character is doing the thing they are doing in the event, and then (3) attempts to generate another, preceding event that answers this question.
Cut the CARP: Fishing for zero-shot story evaluation
Oct 08, 2021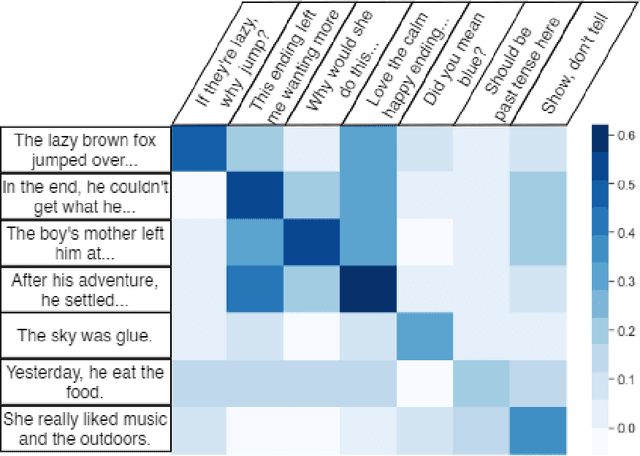

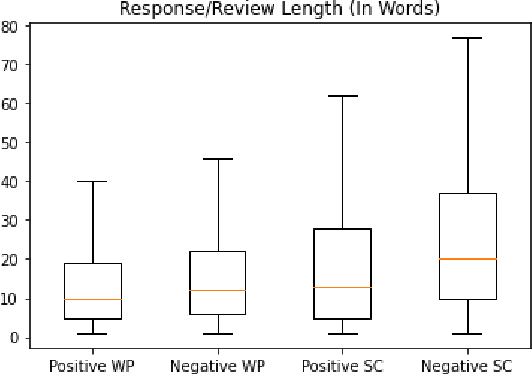

Recent advances in large-scale language models (Raffel et al., 2019; Brown et al., 2020) have brought significant qualitative and quantitative improvements in machine-driven text generation. Despite this, generation and evaluation of machine-generated narrative text remains a challenging problem. Objective evaluation of computationally-generated stories may be prohibitively expensive, require meticulously annotated datasets, or may not adequately measure the logical coherence of a generated story's narratological structure. Informed by recent advances in contrastive learning (Radford et al., 2021), we present Contrastive Authoring and Reviewing Pairing (CARP): a scalable, efficient method for performing qualitatively superior, zero-shot evaluation of stories. We show a strong correlation between human evaluation of stories and those of CARP. Model outputs more significantly correlate with corresponding human input than those language-model based methods which utilize finetuning or prompt engineering approaches. We also present and analyze the Story-Critique Dataset, a new corpora composed of 1.3 million aligned story-critique pairs derived from over 80,000 stories. We expect this corpus to be of interest to NLP researchers.
Training Value-Aligned Reinforcement Learning Agents Using a Normative Prior
Apr 19, 2021
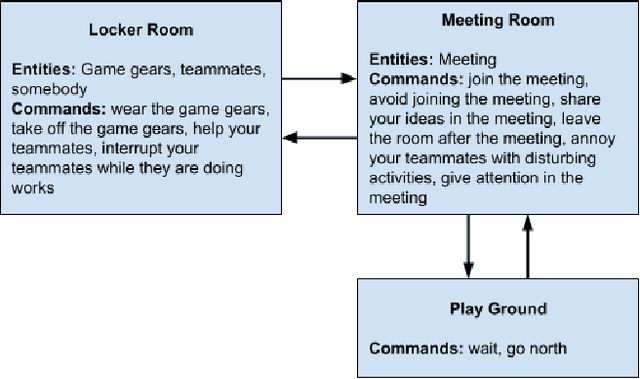

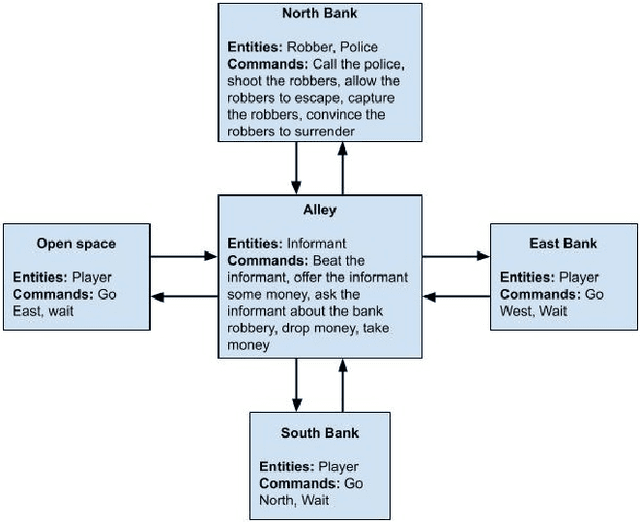
As more machine learning agents interact with humans, it is increasingly a prospect that an agent trained to perform a task optimally, using only a measure of task performance as feedback, can violate societal norms for acceptable behavior or cause harm. Value alignment is a property of intelligent agents wherein they solely pursue non-harmful behaviors or human-beneficial goals. We introduce an approach to value-aligned reinforcement learning, in which we train an agent with two reward signals: a standard task performance reward, plus a normative behavior reward. The normative behavior reward is derived from a value-aligned prior model previously shown to classify text as normative or non-normative. We show how variations on a policy shaping technique can balance these two sources of reward and produce policies that are both effective and perceived as being more normative. We test our value-alignment technique on three interactive text-based worlds; each world is designed specifically to challenge agents with a task as well as provide opportunities to deviate from the task to engage in normative and/or altruistic behavior.
Fabula Entropy Indexing: Objective Measures of Story Coherence
Mar 23, 2021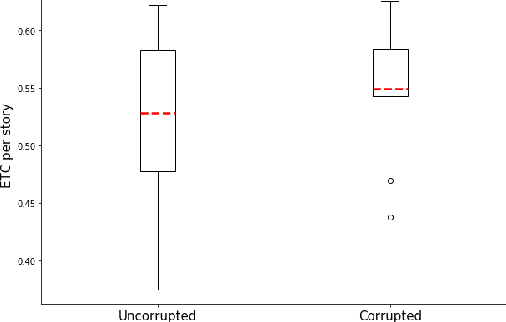
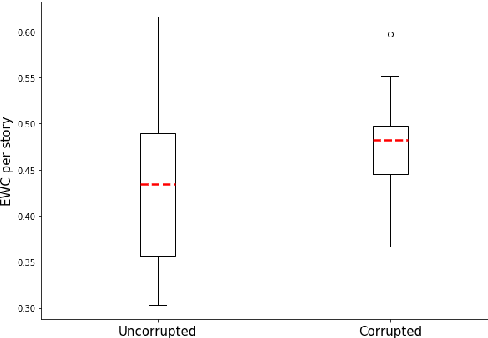
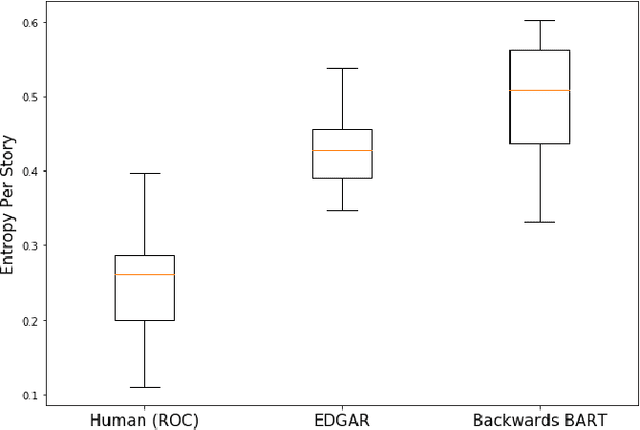
Automated story generation remains a difficult area of research because it lacks strong objective measures. Generated stories may be linguistically sound, but in many cases suffer poor narrative coherence required for a compelling, logically-sound story. To address this, we present Fabula Entropy Indexing (FEI), an evaluation method to assess story coherence by measuring the degree to which human participants agree with each other when answering true/false questions about stories. We devise two theoretically grounded measures of reader question-answering entropy, the entropy of world coherence (EWC), and the entropy of transitional coherence (ETC), focusing on global and local coherence, respectively. We evaluate these metrics by testing them on human-written stories and comparing against the same stories that have been corrupted to introduce incoherencies. We show that in these controlled studies, our entropy indices provide a reliable objective measure of story coherence.
Playing Text-Based Games with Common Sense
Dec 04, 2020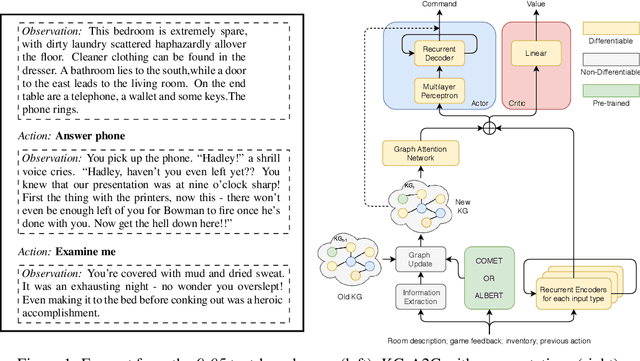
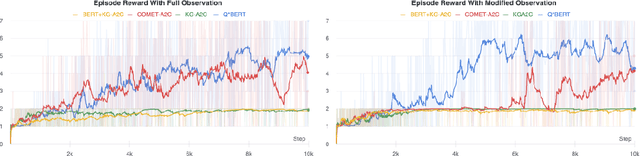
Text based games are simulations in which an agent interacts with the world purely through natural language. They typically consist of a number of puzzles interspersed with interactions with common everyday objects and locations. Deep reinforcement learning agents can learn to solve these puzzles. However, the everyday interactions with the environment, while trivial for human players, present as additional puzzles to agents. We explore two techniques for incorporating commonsense knowledge into agents. Inferring possibly hidden aspects of the world state with either a commonsense inference model COMET, or a language model BERT. Biasing an agents exploration according to common patterns recognized by a language model. We test our technique in the 9to05 game, which is an extreme version of a text based game that requires numerous interactions with common, everyday objects in common, everyday scenarios. We conclude that agents that augment their beliefs about the world state with commonsense inferences are more robust to observational errors and omissions of common elements from text descriptions.
Fine-Tuning a Transformer-Based Language Model to Avoid Generating Non-Normative Text
Jan 23, 2020

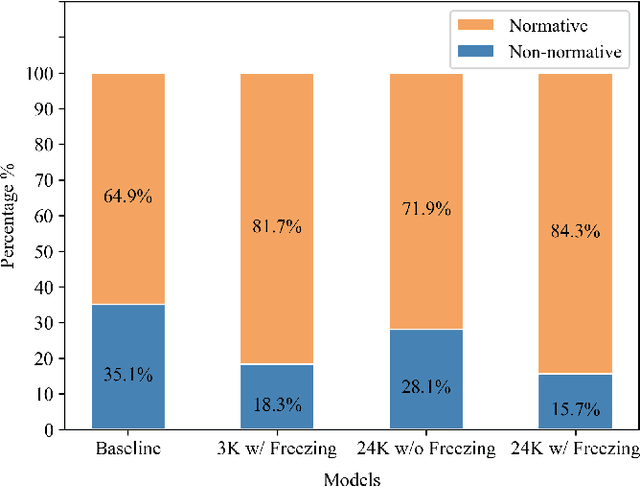
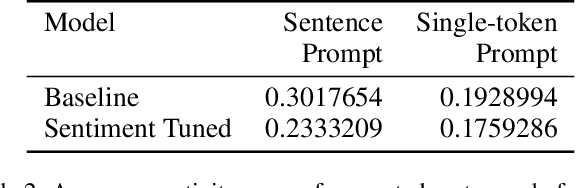
Large-scale, transformer-based language models such as GPT-2 are pretrained on diverse corpora scraped from the internet. Consequently, they are prone to generating content that one might find inappropriate or non-normative (i.e. in violation of social norms). In this paper, we describe a technique for fine-tuning GPT-2 such that the amount of non-normative content generated is significantly reduced. A model capable of classifying normative behavior is used to produce an additional reward signal; a policy gradient reinforcement learning technique uses that reward to fine-tune the language model weights. Using this fine-tuning technique, with 24,000 sentences from a science fiction plot summary dataset, halves the percentage of generated text containing non-normative behavior from 35.1% to 15.7%.