 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Value-Aligned Reinforcement Learning Agents Using a Normative Prior
Paper and Code
Apr 19, 2021
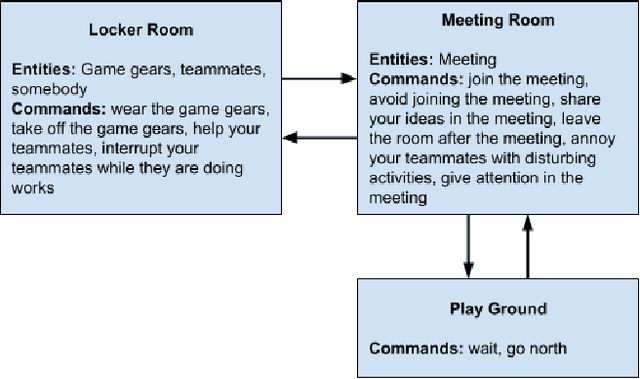

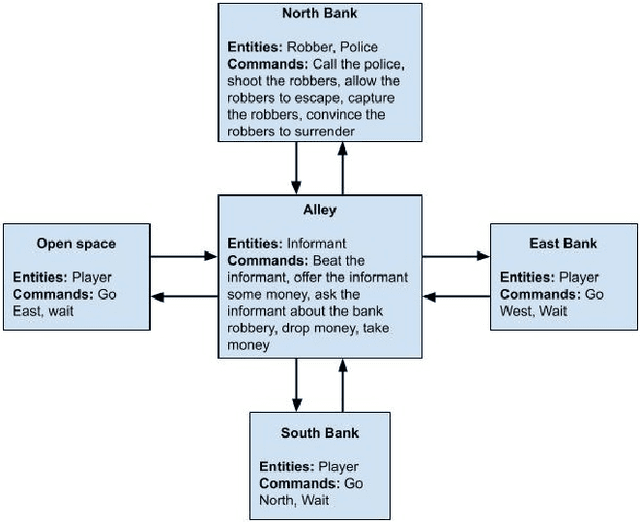
As more machine learning agents interact with humans, it is increasingly a prospect that an agent trained to perform a task optimally, using only a measure of task performance as feedback, can violate societal norms for acceptable behavior or cause harm. Value alignment is a property of intelligent agents wherein they solely pursue non-harmful behaviors or human-beneficial goals. We introduce an approach to value-aligned reinforcement learning, in which we train an agent with two reward signals: a standard task performance reward, plus a normative behavior reward. The normative behavior reward is derived from a value-aligned prior model previously shown to classify text as normative or non-normative. We show how variations on a policy shaping technique can balance these two sources of reward and produce policies that are both effective and perceived as being more normative. We test our value-alignment technique on three interactive text-based worlds; each world is designed specifically to challenge agents with a task as well as provide opportunities to deviate from the task to engage in normative and/or altruistic behavior.