 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Model Routing for Agentic Workflows
Apr 04, 2026Modern agentic workflows decompose complex tasks into specialized subtasks and route them to diverse models to minimize cost without sacrificing quality. However, current routing architectures focus exclusively on performance optimization, leaving underlying trade-offs between model capability and cost unrecorded. Without clear rationale, developers cannot distinguish between intelligent efficiency -- using specialized models for appropriate tasks -- and latent failures caused by budget-driven model selection. We present Topaz, a framework that introduces formal auditability to agentic routing. Topaz replaces silent model assignments with an inherently interpretable router that incorporates three components: (i) skill-based profiling that synthesizes performance across diverse benchmarks into granular capability profiles (ii) fully traceable routing algorithms that utilize budget-based and multi-objective optimization to produce clear traces of how skill-match scores were weighed against costs, and (iii) developer-facing explanations that translate these traces into natural language, allowing users to audit system logic and iteratively tune the cost-quality tradeoff. By making routing decisions interpretable, Topaz enables users to understand, trust, and meaningfully steer routed agentic systems.
The Goofus & Gallant Story Corpus for Practical Value Alignment
Jan 16, 2025

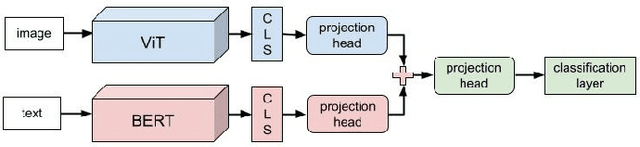
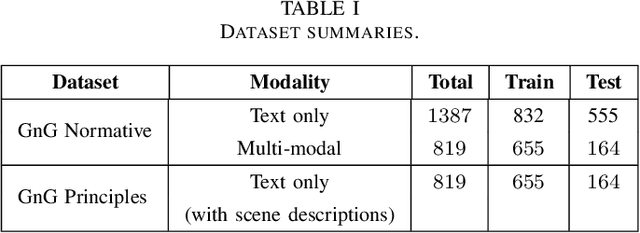
Values or principles are key elements of human society that influence people to behave and function according to an accepted standard set of social rules to maintain social order. As AI systems are becoming ubiquitous in human society, it is a major concern that they could violate these norms or values and potentially cause harm. Thus, to prevent intentional or unintentional harm, AI systems are expected to take actions that align with these principles. Training systems to exhibit this type of behavior is difficult and often requires a specialized dataset. This work presents a multi-modal dataset illustrating normative and non-normative behavior in real-life situations described through natural language and artistic images. This training set contains curated sets of images that are designed to teach young children about social principles. We argue that this is an ideal dataset to use for training socially normative agents given this fact.
Multi-Attribute Constraint Satisfaction via Language Model Rewriting
Dec 26, 2024



Obeying precise constraints on top of multiple external attributes is a common computational problem underlying seemingly different domains, from controlled text generation to protein engineering. Existing language model (LM) controllability methods for multi-attribute constraint satisfaction often rely on specialized architectures or gradient-based classifiers, limiting their flexibility to work with arbitrary black-box evaluators and pretrained models. Current general-purpose large language models, while capable, cannot achieve fine-grained multi-attribute control over external attributes. Thus, we create Multi-Attribute Constraint Satisfaction (MACS), a generalized method capable of finetuning language models on any sequential domain to satisfy user-specified constraints on multiple external real-value attributes. Our method trains LMs as editors by sampling diverse multi-attribute edit pairs from an initial set of paraphrased outputs. During inference, LM iteratively improves upon its previous solution to satisfy constraints for all attributes by leveraging our designed constraint satisfaction reward. We additionally experiment with reward-weighted behavior cloning to further improve the constraint satisfaction rate of LMs. To evaluate our approach, we present a new Fine-grained Constraint Satisfaction (FineCS) benchmark, featuring two challenging tasks: (1) Text Style Transfer, where the goal is to simultaneously modify the sentiment and complexity of reviews, and (2) Protein Design, focusing on modulating fluorescence and stability of Green Fluorescent Proteins (GFP). Our empirical results show that MACS achieves the highest threshold satisfaction in both FineCS tasks, outperforming strong domain-specific baselines. Our work opens new avenues for generalized and real-value multi-attribute control, with implications for diverse applications spanning NLP and bioinformatics.
The Interpretability of Codebooks in Model-Based Reinforcement Learning is Limited
Jul 28, 2024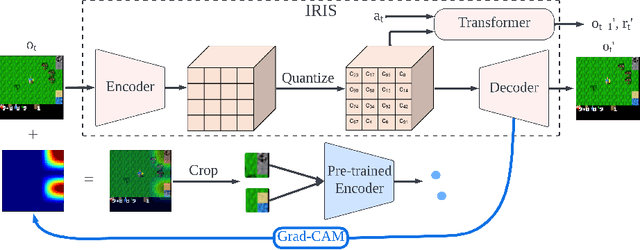
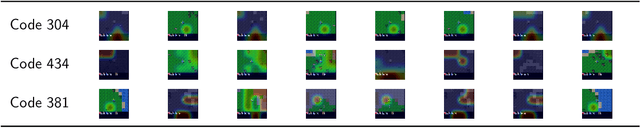
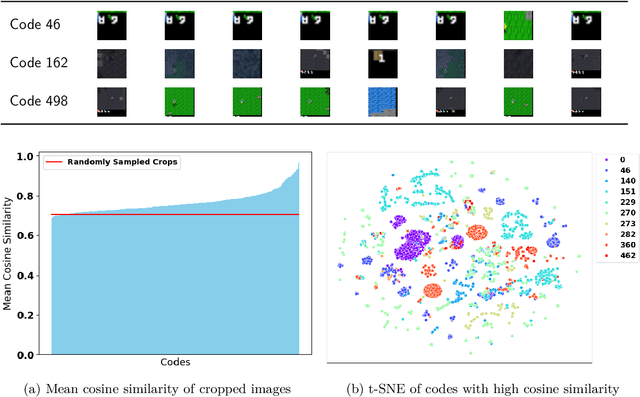
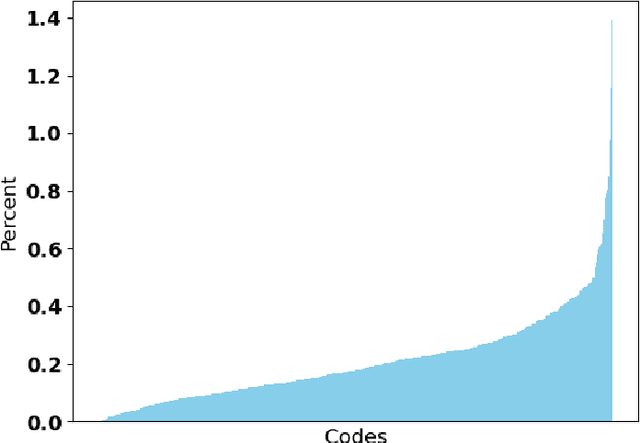
Interpretability of deep reinforcement learning systems could assist operators with understanding how they interact with their environment. Vector quantization methods -- also called codebook methods -- discretize a neural network's latent space that is often suggested to yield emergent interpretability. We investigate whether vector quantization in fact provides interpretability in model-based reinforcement learning. Our experiments, conducted in the reinforcement learning environment Crafter, show that the codes of vector quantization models are inconsistent, have no guarantee of uniqueness, and have a limited impact on concept disentanglement, all of which are necessary traits for interpretability. We share insights on why vector quantization may be fundamentally insufficient for model interpretability.
External Model Motivated Agents: Reinforcement Learning for Enhanced Environment Sampling
Jun 28, 2024



Unlike reinforcement learning (RL) agents, humans remain capable multitaskers in changing environments. In spite of only experiencing the world through their own observations and interactions, people know how to balance focusing on tasks with learning about how changes may affect their understanding of the world. This is possible by choosing to solve tasks in ways that are interesting and generally informative beyond just the current task. Motivated by this, we propose an agent influence framework for RL agents to improve the adaptation efficiency of external models in changing environments without any changes to the agent's rewards. Our formulation is composed of two self-contained modules: interest fields and behavior shaping via interest fields. We implement an uncertainty-based interest field algorithm as well as a skill-sampling-based behavior-shaping algorithm to use in testing this framework. Our results show that our method outperforms the baselines in terms of external model adaptation on metrics that measure both efficiency and performance.
Creating Suspenseful Stories: Iterative Planning with Large Language Models
Feb 27, 2024



Automated story generation has been one of the long-standing challenges in NLP. Among all dimensions of stories, suspense is very common in human-written stories but relatively under-explored in AI-generated stories. While recent advances in large language models (LLMs) have greatly promoted language generation in general, state-of-the-art LLMs are still unreliable when it comes to suspenseful story generation. We propose a novel iterative-prompting-based planning method that is grounded in two theoretical foundations of story suspense from cognitive psychology and narratology. This theory-grounded method works in a fully zero-shot manner and does not rely on any supervised story corpora. To the best of our knowledge, this paper is the first attempt at suspenseful story generation with LLMs. Extensive human evaluations of the generated suspenseful stories demonstrate the effectiveness of our method.
An Ontology of Co-Creative AI Systems
Oct 11, 2023The term co-creativity has been used to describe a wide variety of human-AI assemblages in which human and AI are both involved in a creative endeavor. In order to assist with disambiguating research efforts, we present an ontology of co-creative systems, focusing on how responsibilities are divided between human and AI system and the information exchanged between them. We extend Lubart's original ontology of creativity support tools with three new categories emphasizing artificial intelligence: computer-as-subcontractor, computer-as-critic, and computer-as-teammate, some of which have sub-categorizations.
A Controllable Co-Creative Agent for Game System Design
Aug 04, 2023



Many advancements have been made in procedural content generation for games, and with mixed-initiative co-creativity, have the potential for great benefits to human designers. However, co-creative systems for game generation are typically limited to specific genres, rules, or games, limiting the creativity of the designer. We seek to model games abstractly enough to apply to any genre, focusing on designing game systems and mechanics, and create a controllable, co-creative agent that can collaborate on these designs. We present a model of games using state-machine-like components and resource flows, a set of controllable metrics, a design evaluator simulating playthroughs with these metrics, and an evolutionary design balancer and generator. We find this system to be both able to express a wide range of games and able to be human-controllable for future co-creative applications.
Ambient Adventures: Teaching ChatGPT on Developing Complex Stories
Aug 03, 2023

Imaginative play is an area of creativity that could allow robots to engage with the world around them in a much more personified way. Imaginary play can be seen as taking real objects and locations and using them as imaginary objects and locations in virtual scenarios. We adopted the story generation capability of large language models (LLMs) to obtain the stories used for imaginary play with human-written prompts. Those generated stories will be simplified and mapped into action sequences that can guide the agent in imaginary play. To evaluate whether the agent can successfully finish the imaginary play, we also designed a text adventure game to simulate a house as the playground for the agent to interact.
Thespian: Multi-Character Text Role-Playing Game Agents
Aug 03, 2023



Text-adventure games and text role-playing games are grand challenges for reinforcement learning game playing agents. Text role-playing games are open-ended environments where an agent must faithfully play a particular character. We consider the distinction between characters and actors, where an actor agent has the ability to play multiple characters. We present a framework we call a thespian agent that can learn to emulate multiple characters along with a soft prompt that can be used to direct it as to which character to play at any time. We further describe an attention mechanism that allows the agent to learn new characters that are based on previously learned characters in a few-shot fashion. We show that our agent outperforms the state of the art agent framework in multi-character learning and few-shot learning.