 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Controllable Co-Creative Agent for Game System Design
Aug 04, 2023



Many advancements have been made in procedural content generation for games, and with mixed-initiative co-creativity, have the potential for great benefits to human designers. However, co-creative systems for game generation are typically limited to specific genres, rules, or games, limiting the creativity of the designer. We seek to model games abstractly enough to apply to any genre, focusing on designing game systems and mechanics, and create a controllable, co-creative agent that can collaborate on these designs. We present a model of games using state-machine-like components and resource flows, a set of controllable metrics, a design evaluator simulating playthroughs with these metrics, and an evolutionary design balancer and generator. We find this system to be both able to express a wide range of games and able to be human-controllable for future co-creative applications.
Beyond Prompts: Exploring the Design Space of Mixed-Initiative Co-Creativity Systems
May 03, 2023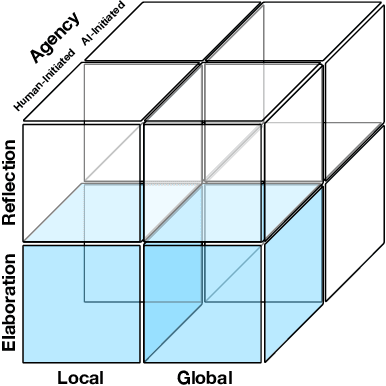
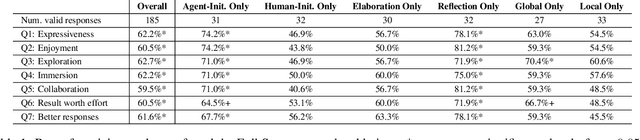
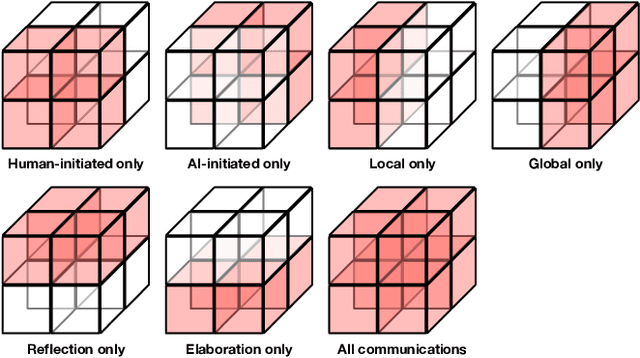

Generative Artificial Intelligence systems have been developed for image, code, story, and game generation with the goal of facilitating human creativity. Recent work on neural generative systems has emphasized one particular means of interacting with AI systems: the user provides a specification, usually in the form of prompts, and the AI system generates the content. However, there are other configurations of human and AI coordination, such as co-creativity (CC) in which both human and AI systems can contribute to content creation, and mixed-initiative (MI) in which both human and AI systems can initiate content changes. In this paper, we define a hypothetical human-AI configuration design space consisting of different means for humans and AI systems to communicate creative intent to each other. We conduct a human participant study with 185 participants to understand how users want to interact with differently configured MI-CC systems. We find out that MI-CC systems with more extensive coverage of the design space are rated higher or on par on a variety of creative and goal-completion metrics, demonstrating that wider coverage of the design space can improve user experience and achievement when using the system; Preference varies greatly between expertise groups, suggesting the development of adaptive, personalized MI-CC systems; Participants identified new design space dimensions including scrutability -- the ability to poke and prod at models -- and explainability.
Efficient 3D Object Reconstruction using Visual Transformers
Feb 16, 2023Reconstructing a 3D object from a 2D image is a well-researched vision problem, with many kinds of deep learning techniques having been tried. Most commonly, 3D convolutional approaches are used, though previous work has shown state-of-the-art methods using 2D convolutions that are also significantly more efficient to train. With the recent rise of transformers for vision tasks, often outperforming convolutional methods, along with some earlier attempts to use transformers for 3D object reconstruction, we set out to use visual transformers in place of convolutions in existing efficient, high-performing techniques for 3D object reconstruction in order to achieve superior results on the task. Using a transformer-based encoder and decoder to predict 3D structure from 2D images, we achieve accuracy similar or superior to the baseline approach. This study serves as evidence for the potential of visual transformers in the task of 3D object reconstruction.
Content-Based Search for Deep Generative Models
Oct 06, 2022
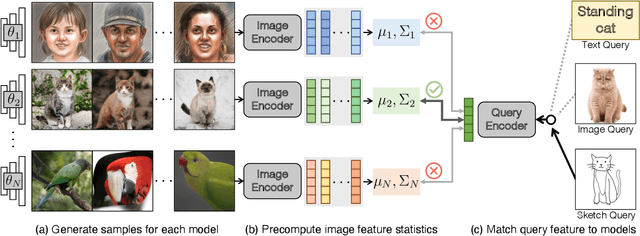
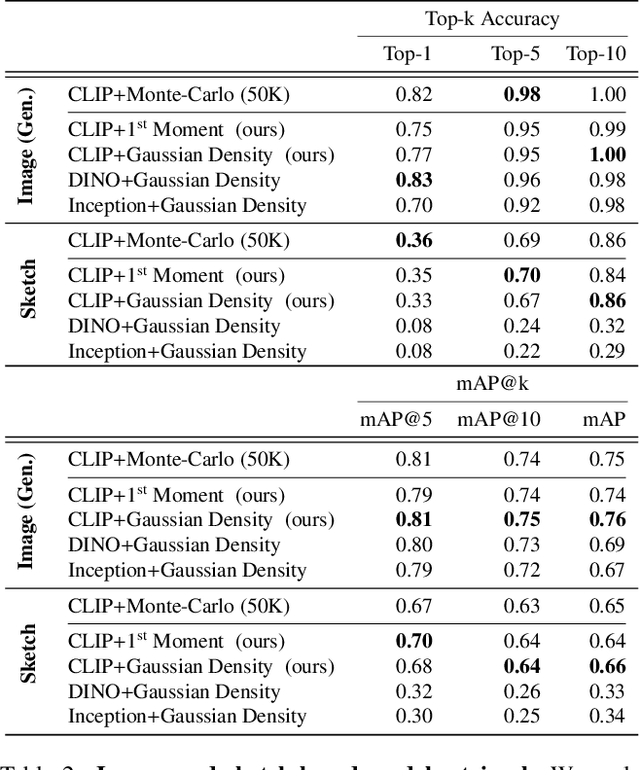

The growing proliferation of pretrained generative models has made it infeasible for a user to be fully cognizant of every model in existence. To address this need, we introduce the task of content-based model search: given a query and a large set of generative models, find the models that best match the query. Because each generative model produces a distribution of images, we formulate the search problem as an optimization to maximize the probability of generating a query match given a model. We develop approximations to make this problem tractable when the query is an image, a sketch, a text description, another generative model, or a combination of the above. We benchmark our method in both accuracy and speed over a set of generative models. We demonstrate that our model search retrieves suitable models for image editing and reconstruction, few-shot transfer learning, and latent space interpolation. Finally, we deploy our search algorithm to our online generative model-sharing platform at https://modelverse.cs.cmu.edu.
Creative Wand: A System to Study Effects of Communications in Co-Creative Settings
Aug 04, 2022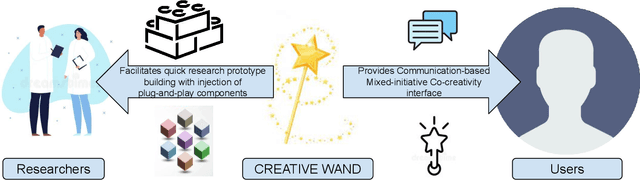
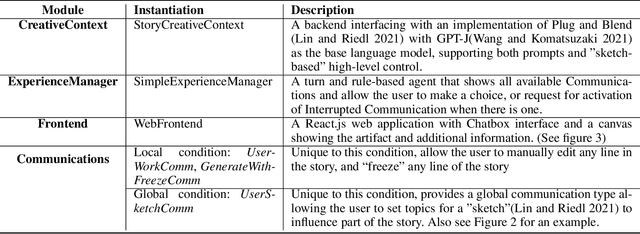


Recent neural generation systems have demonstrated the potential for procedurally generating game content, images, stories, and more. However, most neural generation algorithms are "uncontrolled" in the sense that the user has little say in creative decisions beyond the initial prompt specification. Co-creative, mixed-initiative systems require user-centric means of influencing the algorithm, especially when users are unlikely to have machine learning expertise. The key to co-creative systems is the ability to communicate ideas and intent from the user to the agent, as well as from the agent to the user. Key questions in co-creative AI include: How can users express their creative intentions? How can creative AI systems communicate their beliefs, explain their moves, or instruct users to act on their behalf? When should creative AI systems take initiative? The answer to such questions and more will enable us to develop better co-creative systems that make humans more capable of expressing their creative intents. We introduce CREATIVE-WAND, a customizable framework for investigating co-creative mixed-initiative generation. CREATIVE-WAND enables plug-and-play injection of generative models and human-agent communication channels into a chat-based interface. It provides a number of dimensions along which an AI generator and humans can communicate during the co-creative process. We illustrate the CREATIVE-WAND framework by using it to study one dimension of co-creative communication-global versus local creative intent specification by the user-in the context of storytelling.
ESW Edge-Weights : Ensemble Stochastic Watershed Edge-Weights for Hyperspectral Image Classification
Feb 28, 2022
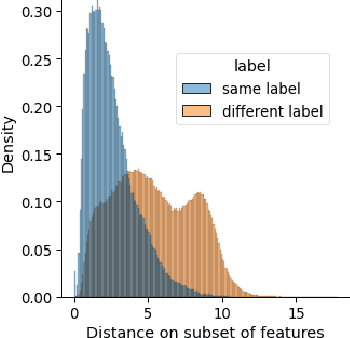
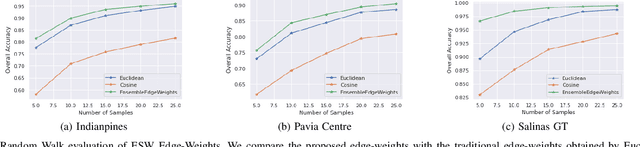
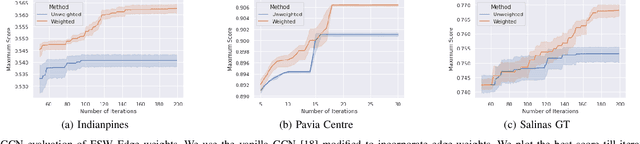
Hyperspectral image (HSI) classification is a topic of active research. One of the main challenges of HSI classification is the lack of reliable labelled samples. Various semi-supervised and unsupervised classification methods are proposed to handle the low number of labelled samples. Chief among them are graph convolution networks (GCN) and their variants. These approaches exploit the graph structure for semi-supervised and unsupervised classification. While several of these methods implicitly construct edge-weights, to our knowledge, not much work has been done to estimate the edge-weights explicitly. In this article, we estimate the edge-weights explicitly and use them for the downstream classification tasks - both semi-supervised and unsupervised. The proposed edge-weights are based on two key insights - (a) Ensembles reduce the variance and (b) Classes in HSI datasets and feature similarity have only one-sided implications. That is, while same classes would have similar features, similar features do not necessarily imply the same classes. Exploiting these, we estimate the edge-weights using an aggregate of ensembles of watersheds over subsamples of features. These edge weights are evaluated for both semi-supervised and unsupervised classification tasks. The evaluation for semi-supervised tasks uses Random-Walk based approach. For the unsupervised case, we use a simple filter using a graph convolution network (GCN). In both these cases, the proposed edge weights outperform the traditional approaches to compute edge-weights - Euclidean distances and cosine similarities. Fascinatingly, with the proposed edge-weights, the simplest GCN obtained results comparable to the recent state-of-the-art.