 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Data Attribution for Text-to-Image Models
Nov 13, 2025Data attribution for text-to-image models aims to identify the training images that most significantly influenced a generated output. Existing attribution methods involve considerable computational resources for each query, making them impractical for real-world applications. We propose a novel approach for scalable and efficient data attribution. Our key idea is to distill a slow, unlearning-based attribution method to a feature embedding space for efficient retrieval of highly influential training images. During deployment, combined with efficient indexing and search methods, our method successfully finds highly influential images without running expensive attribution algorithms. We show extensive results on both medium-scale models trained on MSCOCO and large-scale Stable Diffusion models trained on LAION, demonstrating that our method can achieve better or competitive performance in a few seconds, faster than existing methods by 2,500x - 400,000x. Our work represents a meaningful step towards the large-scale application of data attribution methods on real-world models such as Stable Diffusion.
Learning an Image Editing Model without Image Editing Pairs
Oct 16, 2025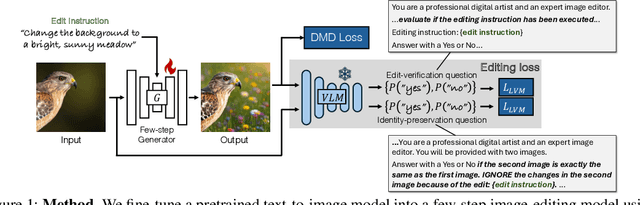
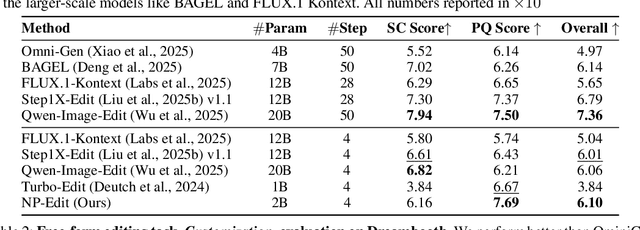

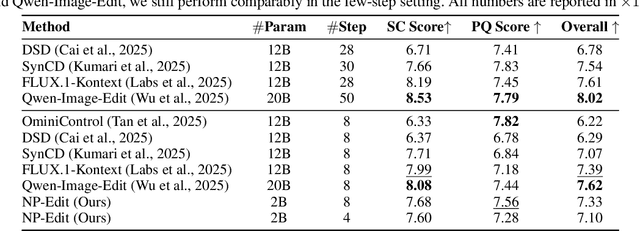
Recent image editing models have achieved impressive results while following natural language editing instructions, but they rely on supervised fine-tuning with large datasets of input-target pairs. This is a critical bottleneck, as such naturally occurring pairs are hard to curate at scale. Current workarounds use synthetic training pairs that leverage the zero-shot capabilities of existing models. However, this can propagate and magnify the artifacts of the pretrained model into the final trained model. In this work, we present a new training paradigm that eliminates the need for paired data entirely. Our approach directly optimizes a few-step diffusion model by unrolling it during training and leveraging feedback from vision-language models (VLMs). For each input and editing instruction, the VLM evaluates if an edit follows the instruction and preserves unchanged content, providing direct gradients for end-to-end optimization. To ensure visual fidelity, we incorporate distribution matching loss (DMD), which constrains generated images to remain within the image manifold learned by pretrained models. We evaluate our method on standard benchmarks and include an extensive ablation study. Without any paired data, our method performs on par with various image editing diffusion models trained on extensive supervised paired data, under the few-step setting. Given the same VLM as the reward model, we also outperform RL-based techniques like Flow-GRPO.
Identifying Prompted Artist Names from Generated Images
Jul 24, 2025A common and controversial use of text-to-image models is to generate pictures by explicitly naming artists, such as "in the style of Greg Rutkowski". We introduce a benchmark for prompted-artist recognition: predicting which artist names were invoked in the prompt from the image alone. The dataset contains 1.95M images covering 110 artists and spans four generalization settings: held-out artists, increasing prompt complexity, multiple-artist prompts, and different text-to-image models. We evaluate feature similarity baselines, contrastive style descriptors, data attribution methods, supervised classifiers, and few-shot prototypical networks. Generalization patterns vary: supervised and few-shot models excel on seen artists and complex prompts, whereas style descriptors transfer better when the artist's style is pronounced; multi-artist prompts remain the most challenging. Our benchmark reveals substantial headroom and provides a public testbed to advance the responsible moderation of text-to-image models. We release the dataset and benchmark to foster further research: https://graceduansu.github.io/IdentifyingPromptedArtists/
Data Attribution for Text-to-Image Models by Unlearning Synthesized Images
Jun 13, 2024The goal of data attribution for text-to-image models is to identify the training images that most influence the generation of a new image. We can define "influence" by saying that, for a given output, if a model is retrained from scratch without that output's most influential images, the model should then fail to generate that output image. Unfortunately, directly searching for these influential images is computationally infeasible, since it would require repeatedly retraining from scratch. We propose a new approach that efficiently identifies highly-influential images. Specifically, we simulate unlearning the synthesized image, proposing a method to increase the training loss on the output image, without catastrophic forgetting of other, unrelated concepts. Then, we find training images that are forgotten by proxy, identifying ones with significant loss deviations after the unlearning process, and label these as influential. We evaluate our method with a computationally intensive but "gold-standard" retraining from scratch and demonstrate our method's advantages over previous methods.
Customizing Text-to-Image Models with a Single Image Pair
May 02, 2024Art reinterpretation is the practice of creating a variation of a reference work, making a paired artwork that exhibits a distinct artistic style. We ask if such an image pair can be used to customize a generative model to capture the demonstrated stylistic difference. We propose Pair Customization, a new customization method that learns stylistic difference from a single image pair and then applies the acquired style to the generation process. Unlike existing methods that learn to mimic a single concept from a collection of images, our method captures the stylistic difference between paired images. This allows us to apply a stylistic change without overfitting to the specific image content in the examples. To address this new task, we employ a joint optimization method that explicitly separates the style and content into distinct LoRA weight spaces. We optimize these style and content weights to reproduce the style and content images while encouraging their orthogonality. During inference, we modify the diffusion process via a new style guidance based on our learned weights. Both qualitative and quantitative experiments show that our method can effectively learn style while avoiding overfitting to image content, highlighting the potential of modeling such stylistic differences from a single image pair.
Evaluating Data Attribution for Text-to-Image Models
Jun 15, 2023
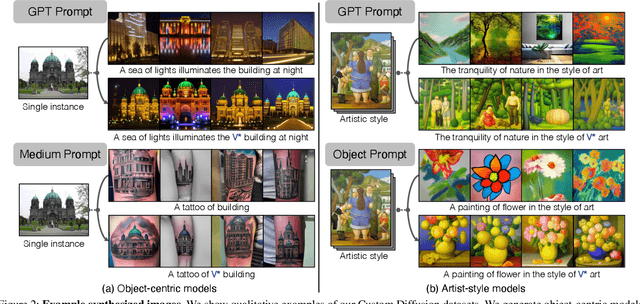

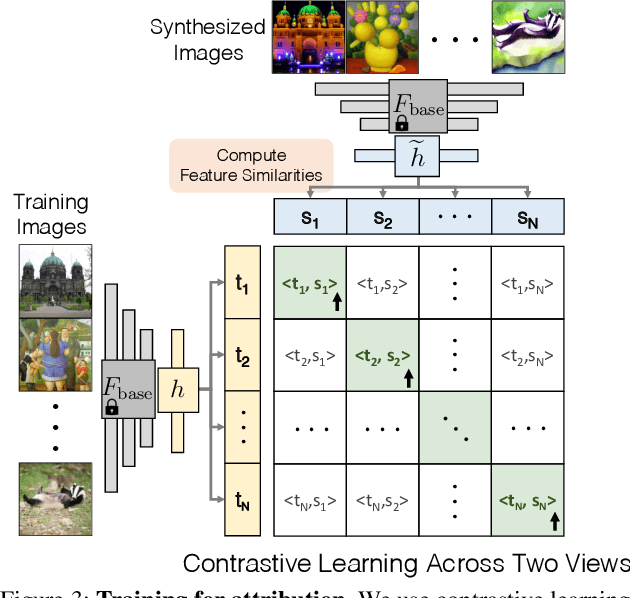
While large text-to-image models are able to synthesize "novel" images, these images are necessarily a reflection of the training data. The problem of data attribution in such models -- which of the images in the training set are most responsible for the appearance of a given generated image -- is a difficult yet important one. As an initial step toward this problem, we evaluate attribution through "customization" methods, which tune an existing large-scale model toward a given exemplar object or style. Our key insight is that this allows us to efficiently create synthetic images that are computationally influenced by the exemplar by construction. With our new dataset of such exemplar-influenced images, we are able to evaluate various data attribution algorithms and different possible feature spaces. Furthermore, by training on our dataset, we can tune standard models, such as DINO, CLIP, and ViT, toward the attribution problem. Even though the procedure is tuned towards small exemplar sets, we show generalization to larger sets. Finally, by taking into account the inherent uncertainty of the problem, we can assign soft attribution scores over a set of training images.
Ablating Concepts in Text-to-Image Diffusion Models
Mar 23, 2023

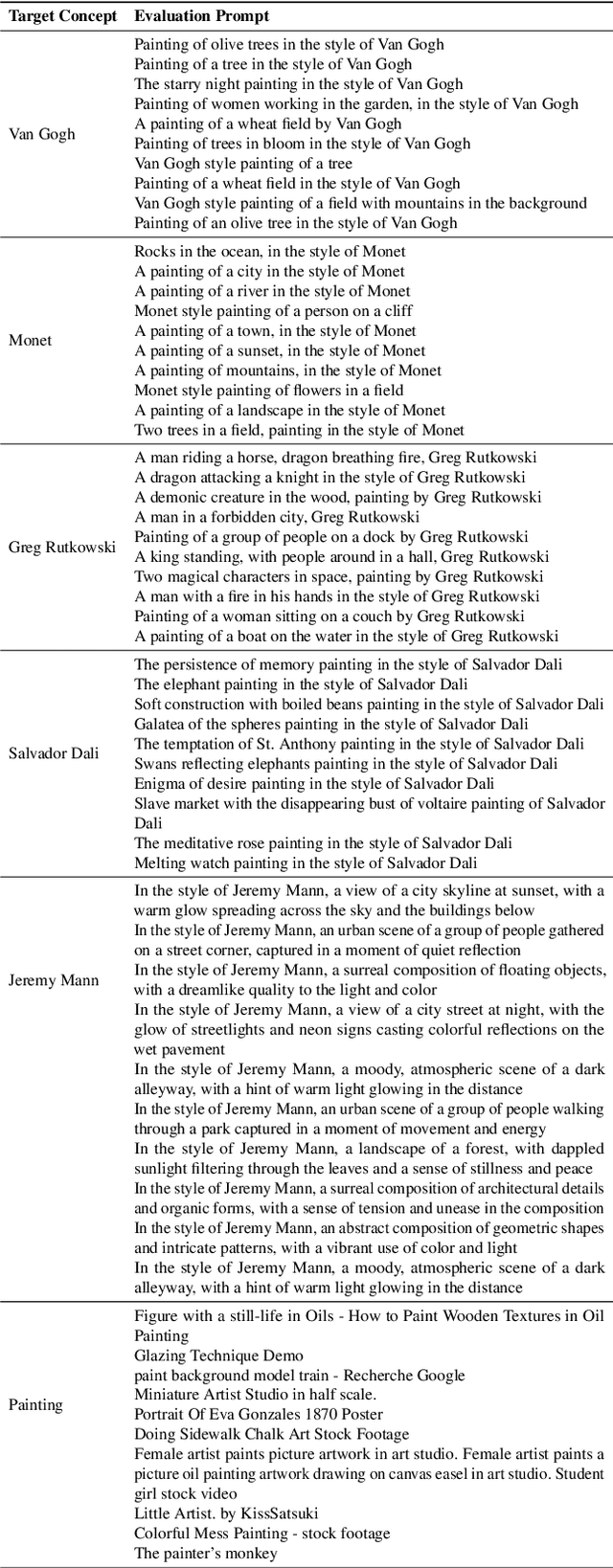

Large-scale text-to-image diffusion models can generate high-fidelity images with powerful compositional ability. However, these models are typically trained on an enormous amount of Internet data, often containing copyrighted material, licensed images, and personal photos. Furthermore, they have been found to replicate the style of various living artists or memorize exact training samples. How can we remove such copyrighted concepts or images without retraining the model from scratch? To achieve this goal, we propose an efficient method of ablating concepts in the pretrained model, i.e., preventing the generation of a target concept. Our algorithm learns to match the image distribution for a target style, instance, or text prompt we wish to ablate to the distribution corresponding to an anchor concept. This prevents the model from generating target concepts given its text condition. Extensive experiments show that our method can successfully prevent the generation of the ablated concept while preserving closely related concepts in the model.
Content-Based Search for Deep Generative Models
Oct 06, 2022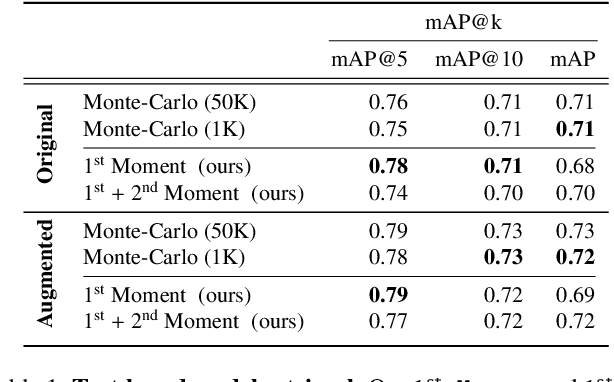
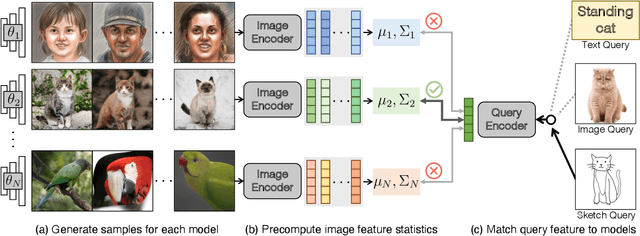
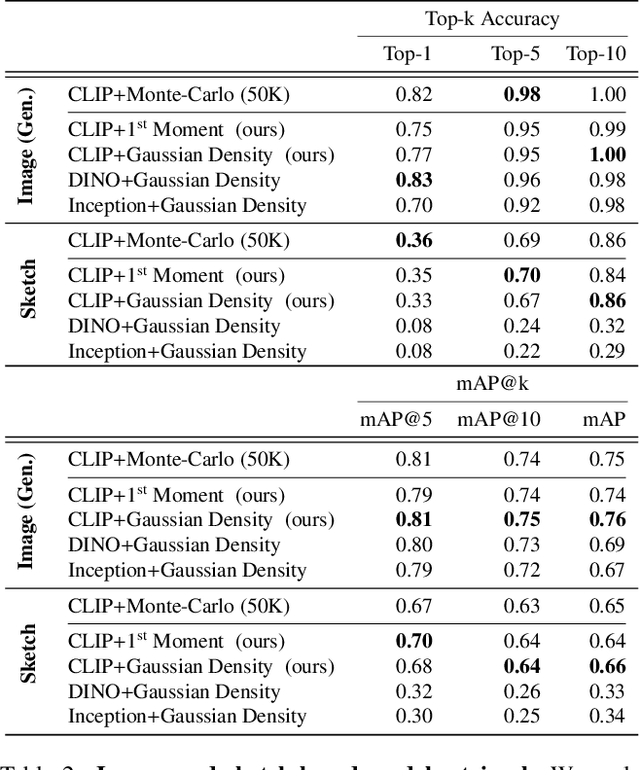

The growing proliferation of pretrained generative models has made it infeasible for a user to be fully cognizant of every model in existence. To address this need, we introduce the task of content-based model search: given a query and a large set of generative models, find the models that best match the query. Because each generative model produces a distribution of images, we formulate the search problem as an optimization to maximize the probability of generating a query match given a model. We develop approximations to make this problem tractable when the query is an image, a sketch, a text description, another generative model, or a combination of the above. We benchmark our method in both accuracy and speed over a set of generative models. We demonstrate that our model search retrieves suitable models for image editing and reconstruction, few-shot transfer learning, and latent space interpolation. Finally, we deploy our search algorithm to our online generative model-sharing platform at https://modelverse.cs.cmu.edu.
Rewriting Geometric Rules of a GAN
Jul 28, 2022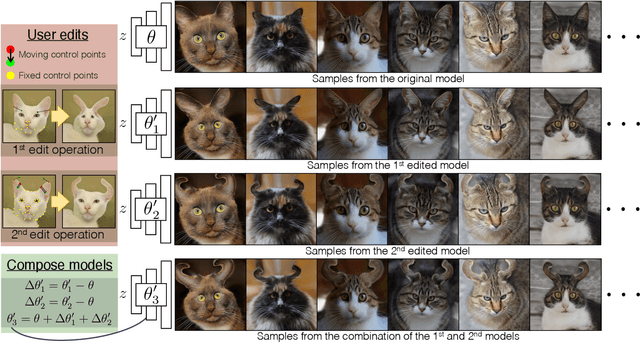
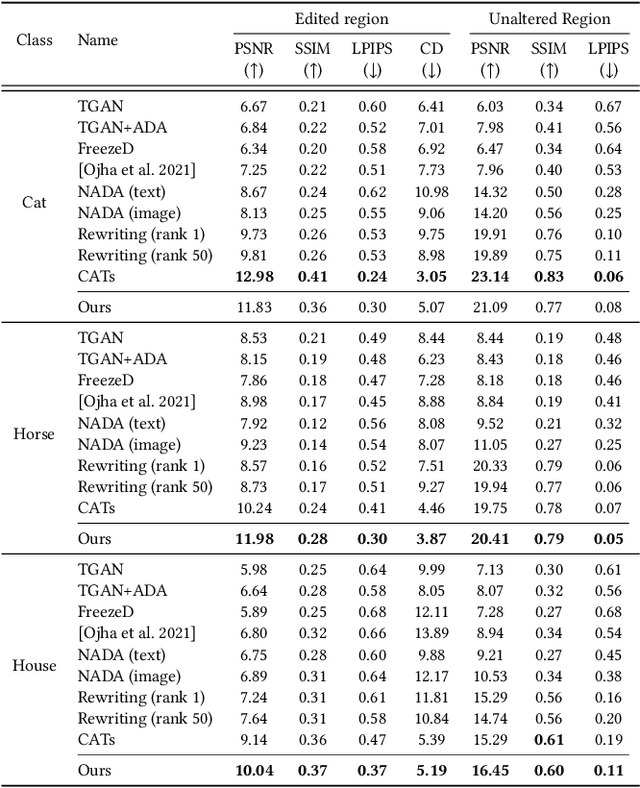
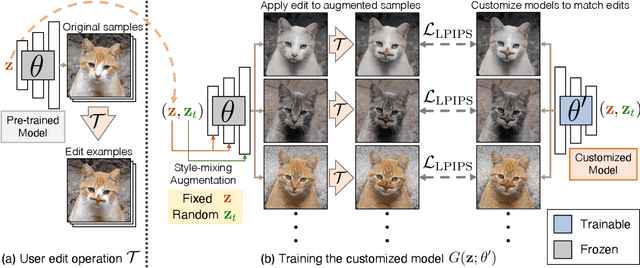
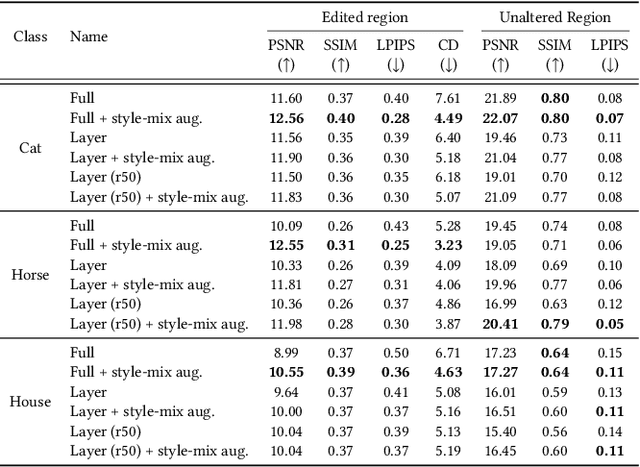
Deep generative models make visual content creation more accessible to novice users by automating the synthesis of diverse, realistic content based on a collected dataset. However, the current machine learning approaches miss a key element of the creative process -- the ability to synthesize things that go far beyond the data distribution and everyday experience. To begin to address this issue, we enable a user to "warp" a given model by editing just a handful of original model outputs with desired geometric changes. Our method applies a low-rank update to a single model layer to reconstruct edited examples. Furthermore, to combat overfitting, we propose a latent space augmentation method based on style-mixing. Our method allows a user to create a model that synthesizes endless objects with defined geometric changes, enabling the creation of a new generative model without the burden of curating a large-scale dataset. We also demonstrate that edited models can be composed to achieve aggregated effects, and we present an interactive interface to enable users to create new models through composition. Empirical measurements on multiple test cases suggest the advantage of our method against recent GAN fine-tuning methods. Finally, we showcase several applications using the edited models, including latent space interpolation and image editing.
Sketch Your Own GAN
Aug 05, 2021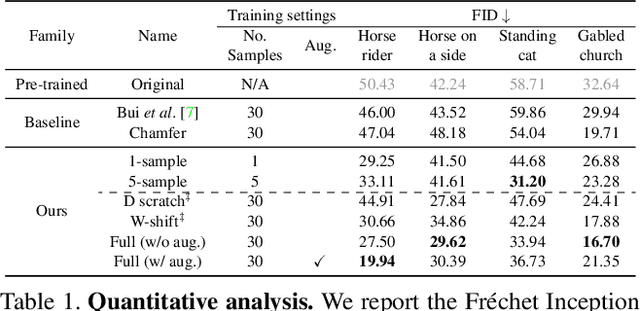
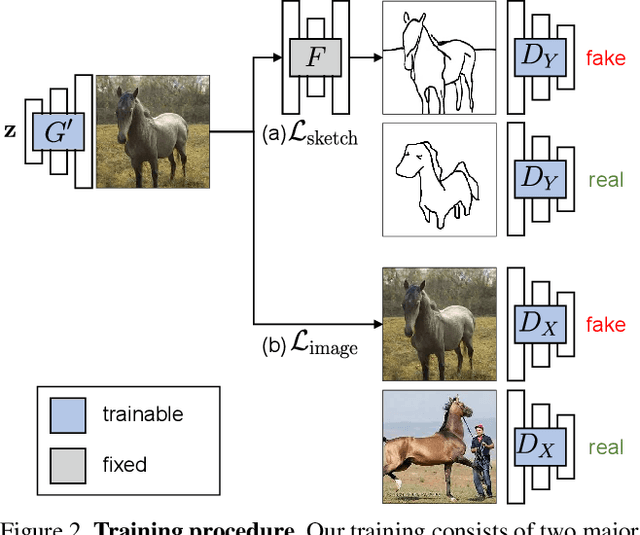
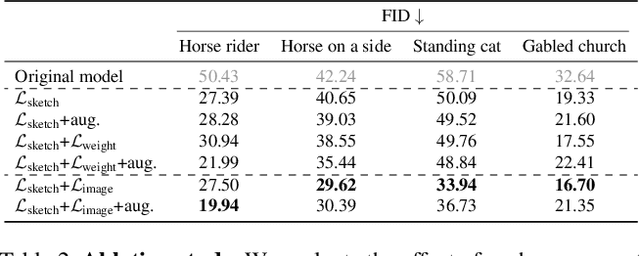

Can a user create a deep generative model by sketching a single example? Traditionally, creating a GAN model has required the collection of a large-scale dataset of exemplars and specialized knowledge in deep learning. In contrast, sketching is possibly the most universally accessible way to convey a visual concept. In this work, we present a method, GAN Sketching, for rewriting GANs with one or more sketches, to make GANs training easier for novice users. In particular, we change the weights of an original GAN model according to user sketches. We encourage the model's output to match the user sketches through a cross-domain adversarial loss. Furthermore, we explore different regularization methods to preserve the original model's diversity and image quality. Experiments have shown that our method can mold GANs to match shapes and poses specified by sketches while maintaining realism and diversity. Finally, we demonstrate a few applications of the resulting GAN, including latent space interpolation and image editing.