 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTeP: A General and Scalable Framework for Solving Video Inverse Problems with Spatiotemporal Diffusion Priors
Apr 10, 2025We study how to solve general Bayesian inverse problems involving videos using diffusion model priors. While it is desirable to use a video diffusion prior to effectively capture complex temporal relationships, due to the computational and data requirements of training such a model, prior work has instead relied on image diffusion priors on single frames combined with heuristics to enforce temporal consistency. However, these approaches struggle with faithfully recovering the underlying temporal relationships, particularly for tasks with high temporal uncertainty. In this paper, we demonstrate the feasibility of practical and accessible spatiotemporal diffusion priors by fine-tuning latent video diffusion models from pretrained image diffusion models using limited videos in specific domains. Leveraging this plug-and-play spatiotemporal diffusion prior, we introduce a general and scalable framework for solving video inverse problems. We then apply our framework to two challenging scientific video inverse problems--black hole imaging and dynamic MRI. Our framework enables the generation of diverse, high-fidelity video reconstructions that not only fit observations but also recover multi-modal solutions. By incorporating a spatiotemporal diffusion prior, we significantly improve our ability to capture complex temporal relationships in the data while also enhancing spatial fidelity.
InverseBench: Benchmarking Plug-and-Play Diffusion Priors for Inverse Problems in Physical Sciences
Mar 14, 2025



Plug-and-play diffusion priors (PnPDP) have emerged as a promising research direction for solving inverse problems. However, current studies primarily focus on natural image restoration, leaving the performance of these algorithms in scientific inverse problems largely unexplored. To address this gap, we introduce \textsc{InverseBench}, a framework that evaluates diffusion models across five distinct scientific inverse problems. These problems present unique structural challenges that differ from existing benchmarks, arising from critical scientific applications such as optical tomography, medical imaging, black hole imaging, seismology, and fluid dynamics. With \textsc{InverseBench}, we benchmark 14 inverse problem algorithms that use plug-and-play diffusion priors against strong, domain-specific baselines, offering valuable new insights into the strengths and weaknesses of existing algorithms. To facilitate further research and development, we open-source the codebase, along with datasets and pre-trained models, at https://devzhk.github.io/InverseBench/.
Improving Diffusion Inverse Problem Solving with Decoupled Noise Annealing
Jul 01, 2024Diffusion models have recently achieved success in solving Bayesian inverse problems with learned data priors. Current methods build on top of the diffusion sampling process, where each denoising step makes small modifications to samples from the previous step. However, this process struggles to correct errors from earlier sampling steps, leading to worse performance in complicated nonlinear inverse problems, such as phase retrieval. To address this challenge, we propose a new method called Decoupled Annealing Posterior Sampling (DAPS) that relies on a novel noise annealing process. Specifically, we decouple consecutive steps in a diffusion sampling trajectory, allowing them to vary considerably from one another while ensuring their time-marginals anneal to the true posterior as we reduce noise levels. This approach enables the exploration of a larger solution space, improving the success rate for accurate reconstructions. We demonstrate that DAPS significantly improves sample quality and stability across multiple image restoration tasks, particularly in complicated nonlinear inverse problems. For example, we achieve a PSNR of 30.72dB on the FFHQ 256 dataset for phase retrieval, which is an improvement of 9.12dB compared to existing methods.
Principled Probabilistic Imaging using Diffusion Models as Plug-and-Play Priors
May 29, 2024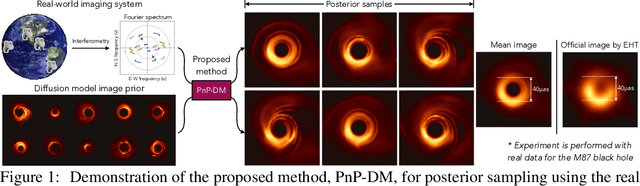
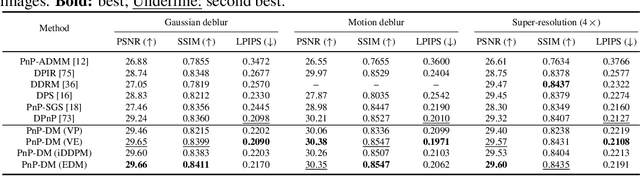
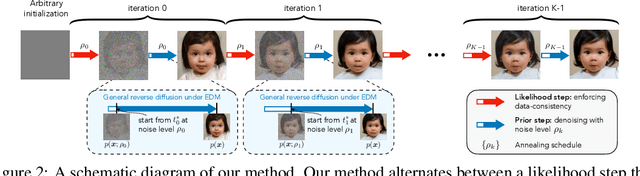

Diffusion models (DMs) have recently shown outstanding capability in modeling complex image distributions, making them expressive image priors for solving Bayesian inverse problems. However, most existing DM-based methods rely on approximations in the generative process to be generic to different inverse problems, leading to inaccurate sample distributions that deviate from the target posterior defined within the Bayesian framework. To harness the generative power of DMs while avoiding such approximations, we propose a Markov chain Monte Carlo algorithm that performs posterior sampling for general inverse problems by reducing it to sampling the posterior of a Gaussian denoising problem. Crucially, we leverage a general DM formulation as a unified interface that allows for rigorously solving the denoising problem with a range of state-of-the-art DMs. We demonstrate the effectiveness of the proposed method on six inverse problems (three linear and three nonlinear), including a real-world black hole imaging problem. Experimental results indicate that our proposed method offers more accurate reconstructions and posterior estimation compared to existing DM-based imaging inverse methods.
Ablating Concepts in Text-to-Image Diffusion Models
Mar 23, 2023

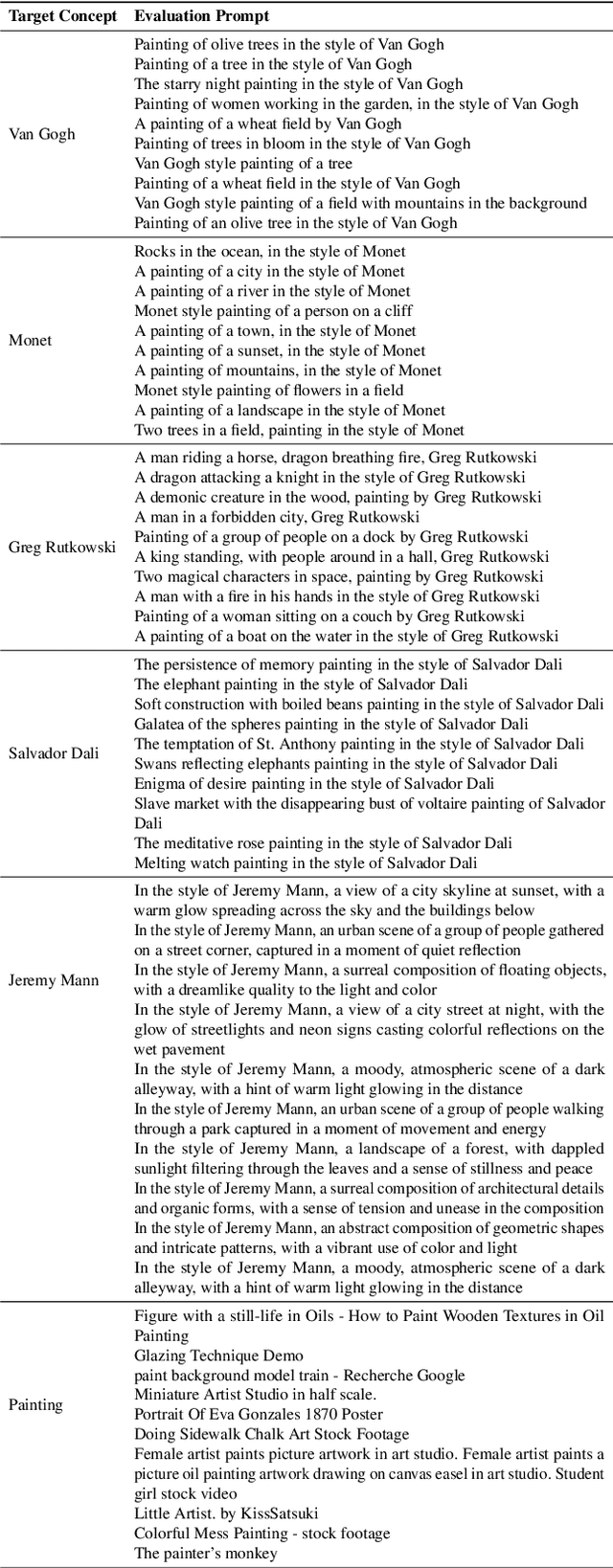

Large-scale text-to-image diffusion models can generate high-fidelity images with powerful compositional ability. However, these models are typically trained on an enormous amount of Internet data, often containing copyrighted material, licensed images, and personal photos. Furthermore, they have been found to replicate the style of various living artists or memorize exact training samples. How can we remove such copyrighted concepts or images without retraining the model from scratch? To achieve this goal, we propose an efficient method of ablating concepts in the pretrained model, i.e., preventing the generation of a target concept. Our algorithm learns to match the image distribution for a target style, instance, or text prompt we wish to ablate to the distribution corresponding to an anchor concept. This prevents the model from generating target concepts given its text condition. Extensive experiments show that our method can successfully prevent the generation of the ablated concept while preserving closely related concepts in the model.
Multi-Concept Customization of Text-to-Image Diffusion
Dec 08, 2022
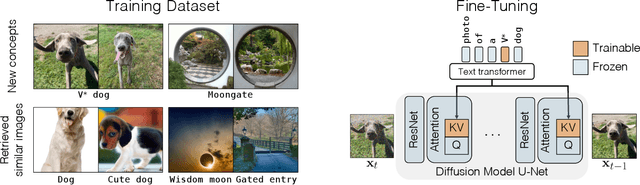
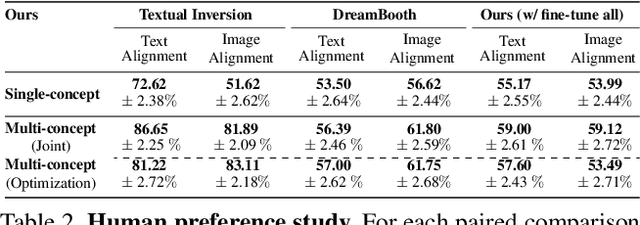
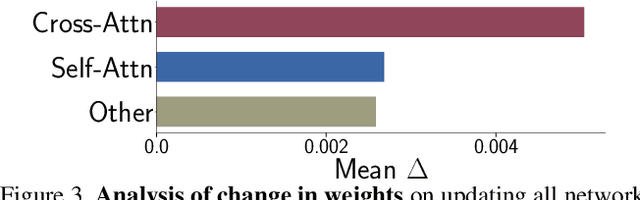
While generative models produce high-quality images of concepts learned from a large-scale database, a user often wishes to synthesize instantiations of their own concepts (for example, their family, pets, or items). Can we teach a model to quickly acquire a new concept, given a few examples? Furthermore, can we compose multiple new concepts together? We propose Custom Diffusion, an efficient method for augmenting existing text-to-image models. We find that only optimizing a few parameters in the text-to-image conditioning mechanism is sufficiently powerful to represent new concepts while enabling fast tuning (~6 minutes). Additionally, we can jointly train for multiple concepts or combine multiple fine-tuned models into one via closed-form constrained optimization. Our fine-tuned model generates variations of multiple, new concepts and seamlessly composes them with existing concepts in novel settings. Our method outperforms several baselines and concurrent works, regarding both qualitative and quantitative evaluations, while being memory and computationally efficient.
Continuously Discovering Novel Strategies via Reward-Switching Policy Optimization
Apr 04, 2022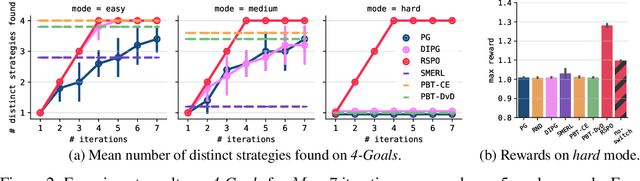

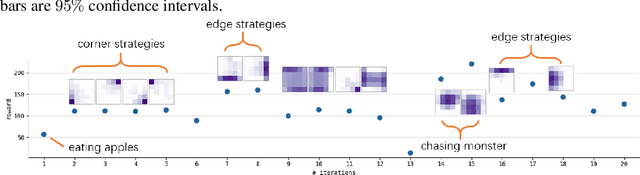

We present Reward-Switching Policy Optimization (RSPO), a paradigm to discover diverse strategies in complex RL environments by iteratively finding novel policies that are both locally optimal and sufficiently different from existing ones. To encourage the learning policy to consistently converge towards a previously undiscovered local optimum, RSPO switches between extrinsic and intrinsic rewards via a trajectory-based novelty measurement during the optimization process. When a sampled trajectory is sufficiently distinct, RSPO performs standard policy optimization with extrinsic rewards. For trajectories with high likelihood under existing policies, RSPO utilizes an intrinsic diversity reward to promote exploration. Experiments show that RSPO is able to discover a wide spectrum of strategies in a variety of domains, ranging from single-agent particle-world tasks and MuJoCo continuous control to multi-agent stag-hunt games and StarCraftII challenges.