 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Baselines with Representation Autoencoders
May 18, 2026Representation Autoencoders (RAE) replace traditional VAE with pretrained vision encoders. In this paper, we systematically investigate several design choices and find three insights which simplify and improve RAE. First, we study a generalized formulation where the representation is defined as sum of the last k encoder layers rather than solely the final layer. This simple change greatly improves reconstruction without encoder finetuning or specialized data (e.g., text, faces). Second, we study the prevalent assumption that RAE (using pretrained representation as encoder) replaces representation alignment (REPA), which distills the same representation to intermediate layers instead. Through large-scale empirical analysis, we uncover a surprising finding: RAE and REPA exhibit complementary working mechanisms, allowing the same representation to be used as both encoder and target for intermediate diffusion layers. Finally, the original RAE struggles with classifier-free guidance (CFG) and requires training a second, weaker diffusion model for AutoGuidance (AG). We show that REPA itself can be viewed as x-prediction in RAE latent space. By simply re-parameterizing the output of the DiT model, it can provide guidance for "free". Overall, RAEv2 leads to more than 10x faster convergence over the original RAE, achieving a state-of-the-art gFID of 1.06 in just 80 epochs on ImageNet-256. On FDr^k, RAEv2 achieves a state-of-the-art 2.17 at just 80 epochs compared to the previous best 3.26 (800 epochs) without any post-training. This motivates EP_FID@k (epochs to reach unguided gFID <= k) as a measure of training efficiency. RAEv2 attains an EP_FID@2 of 35 epochs, versus 177 for the original RAE. We also validate our approach across diverse settings for text-to-image generation and navigation world models, showing consistent improvements. Code is available at https://raev2.github.io.
End-to-End Training for Unified Tokenization and Latent Denoising
Mar 23, 2026Latent diffusion models (LDMs) enable high-fidelity synthesis by operating in learned latent spaces. However, training state-of-the-art LDMs requires complex staging: a tokenizer must be trained first, before the diffusion model can be trained in the frozen latent space. We propose UNITE - an autoencoder architecture for unified tokenization and latent diffusion. UNITE consists of a Generative Encoder that serves as both image tokenizer and latent generator via weight sharing. Our key insight is that tokenization and generation can be viewed as the same latent inference problem under different conditioning regimes: tokenization infers latents from fully observed images, whereas generation infers them from noise together with text or class conditioning. Motivated by this, we introduce a single-stage training procedure that jointly optimizes both tasks via two forward passes through the same Generative Encoder. The shared parameters enable gradients to jointly shape the latent space, encouraging a "common latent language". Across image and molecule modalities, UNITE achieves near state of the art performance without adversarial losses or pretrained encoders (e.g., DINO), reaching FID 2.12 and 1.73 for Base and Large models on ImageNet 256 x 256. We further analyze the Generative Encoder through the lenses of representation alignment and compression. These results show that single stage joint training of tokenization & generation from scratch is feasible.
Causality in Video Diffusers is Separable from Denoising
Feb 10, 2026Causality -- referring to temporal, uni-directional cause-effect relationships between components -- underlies many complex generative processes, including videos, language, and robot trajectories. Current causal diffusion models entangle temporal reasoning with iterative denoising, applying causal attention across all layers, at every denoising step, and over the entire context. In this paper, we show that the causal reasoning in these models is separable from the multi-step denoising process. Through systematic probing of autoregressive video diffusers, we uncover two key regularities: (1) early layers produce highly similar features across denoising steps, indicating redundant computation along the diffusion trajectory; and (2) deeper layers exhibit sparse cross-frame attention and primarily perform intra-frame rendering. Motivated by these findings, we introduce Separable Causal Diffusion (SCD), a new architecture that explicitly decouples once-per-frame temporal reasoning, via a causal transformer encoder, from multi-step frame-wise rendering, via a lightweight diffusion decoder. Extensive experiments on both pretraining and post-training tasks across synthetic and real benchmarks show that SCD significantly improves throughput and per-frame latency while matching or surpassing the generation quality of strong causal diffusion baselines.
Self-Evaluation Unlocks Any-Step Text-to-Image Generation
Dec 26, 2025We introduce the Self-Evaluating Model (Self-E), a novel, from-scratch training approach for text-to-image generation that supports any-step inference. Self-E learns from data similarly to a Flow Matching model, while simultaneously employing a novel self-evaluation mechanism: it evaluates its own generated samples using its current score estimates, effectively serving as a dynamic self-teacher. Unlike traditional diffusion or flow models, it does not rely solely on local supervision, which typically necessitates many inference steps. Unlike distillation-based approaches, it does not require a pretrained teacher. This combination of instantaneous local learning and self-driven global matching bridges the gap between the two paradigms, enabling the training of a high-quality text-to-image model from scratch that excels even at very low step counts. Extensive experiments on large-scale text-to-image benchmarks show that Self-E not only excels in few-step generation, but is also competitive with state-of-the-art Flow Matching models at 50 steps. We further find that its performance improves monotonically as inference steps increase, enabling both ultra-fast few-step generation and high-quality long-trajectory sampling within a single unified model. To our knowledge, Self-E is the first from-scratch, any-step text-to-image model, offering a unified framework for efficient and scalable generation.
Group Diffusion: Enhancing Image Generation by Unlocking Cross-Sample Collaboration
Dec 11, 2025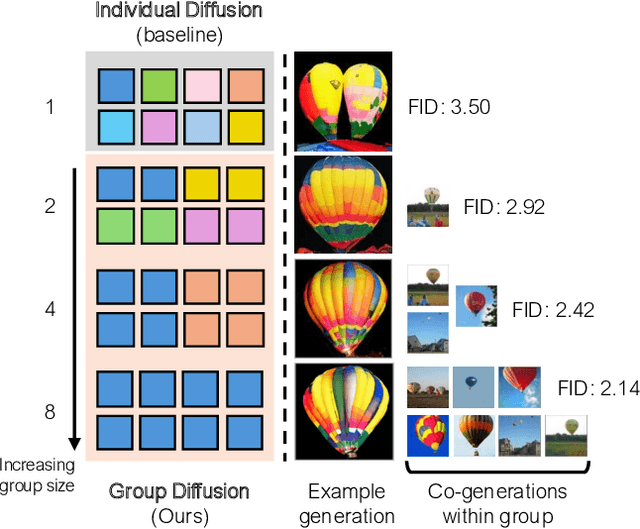
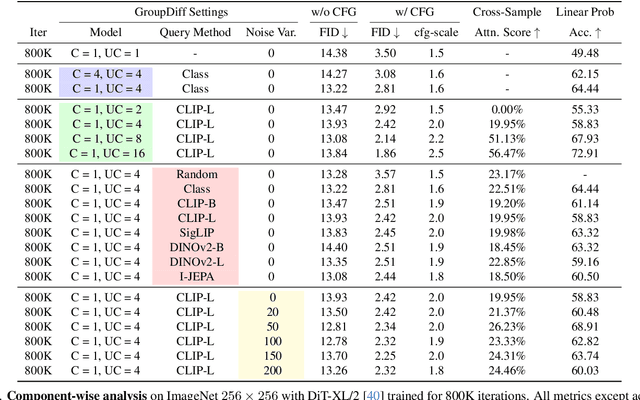

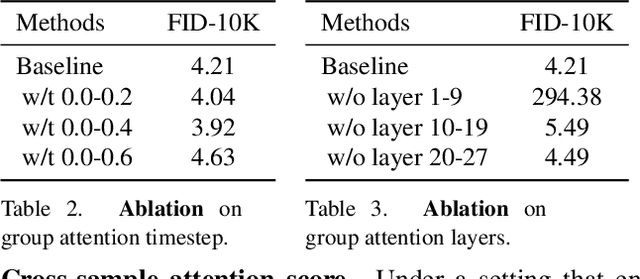
In this work, we explore an untapped signal in diffusion model inference. While all previous methods generate images independently at inference, we instead ask if samples can be generated collaboratively. We propose Group Diffusion, unlocking the attention mechanism to be shared across images, rather than limited to just the patches within an image. This enables images to be jointly denoised at inference time, learning both intra and inter-image correspondence. We observe a clear scaling effect - larger group sizes yield stronger cross-sample attention and better generation quality. Furthermore, we introduce a qualitative measure to capture this behavior and show that its strength closely correlates with FID. Built on standard diffusion transformers, our GroupDiff achieves up to 32.2% FID improvement on ImageNet-256x256. Our work reveals cross-sample inference as an effective, previously unexplored mechanism for generative modeling.
What matters for Representation Alignment: Global Information or Spatial Structure?
Dec 11, 2025Representation alignment (REPA) guides generative training by distilling representations from a strong, pretrained vision encoder to intermediate diffusion features. We investigate a fundamental question: what aspect of the target representation matters for generation, its \textit{global} \revision{semantic} information (e.g., measured by ImageNet-1K accuracy) or its spatial structure (i.e. pairwise cosine similarity between patch tokens)? Prevalent wisdom holds that stronger global semantic performance leads to better generation as a target representation. To study this, we first perform a large-scale empirical analysis across 27 different vision encoders and different model scales. The results are surprising; spatial structure, rather than global performance, drives the generation performance of a target representation. To further study this, we introduce two straightforward modifications, which specifically accentuate the transfer of \emph{spatial} information. We replace the standard MLP projection layer in REPA with a simple convolution layer and introduce a spatial normalization layer for the external representation. Surprisingly, our simple method (implemented in $<$4 lines of code), termed iREPA, consistently improves convergence speed of REPA, across a diverse set of vision encoders, model sizes, and training variants (such as REPA, REPA-E, Meanflow, JiT etc). %, etc. Our work motivates revisiting the fundamental working mechanism of representational alignment and how it can be leveraged for improved training of generative models. The code and project page are available at https://end2end-diffusion.github.io/irepa
Relational Visual Similarity
Dec 08, 2025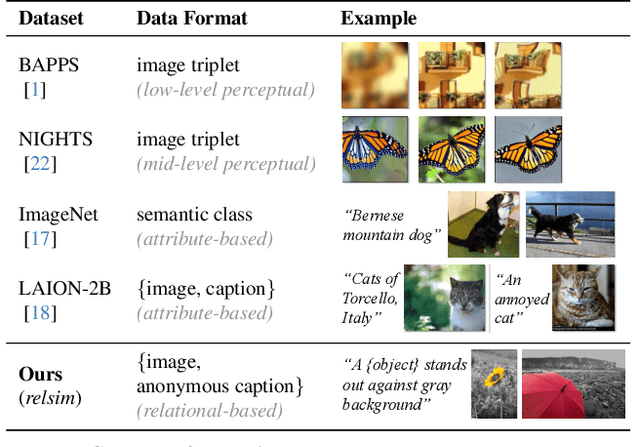
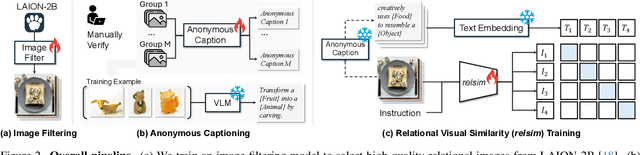
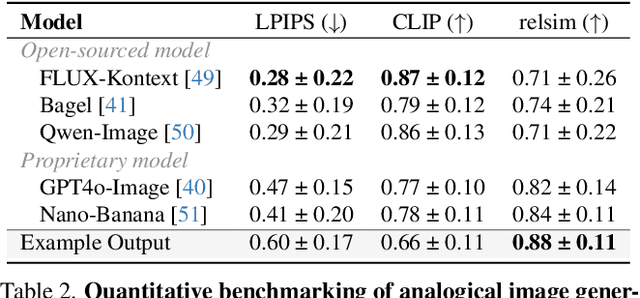

Humans do not just see attribute similarity -- we also see relational similarity. An apple is like a peach because both are reddish fruit, but the Earth is also like a peach: its crust, mantle, and core correspond to the peach's skin, flesh, and pit. This ability to perceive and recognize relational similarity, is arguable by cognitive scientist to be what distinguishes humans from other species. Yet, all widely used visual similarity metrics today (e.g., LPIPS, CLIP, DINO) focus solely on perceptual attribute similarity and fail to capture the rich, often surprising relational similarities that humans perceive. How can we go beyond the visible content of an image to capture its relational properties? How can we bring images with the same relational logic closer together in representation space? To answer these questions, we first formulate relational image similarity as a measurable problem: two images are relationally similar when their internal relations or functions among visual elements correspond, even if their visual attributes differ. We then curate 114k image-caption dataset in which the captions are anonymized -- describing the underlying relational logic of the scene rather than its surface content. Using this dataset, we finetune a Vision-Language model to measure the relational similarity between images. This model serves as the first step toward connecting images by their underlying relational structure rather than their visible appearance. Our study shows that while relational similarity has a lot of real-world applications, existing image similarity models fail to capture it -- revealing a critical gap in visual computing.
UniSER: A Foundation Model for Unified Soft Effects Removal
Nov 18, 2025Digital images are often degraded by soft effects such as lens flare, haze, shadows, and reflections, which reduce aesthetics even though the underlying pixels remain partially visible. The prevailing works address these degradations in isolation, developing highly specialized, specialist models that lack scalability and fail to exploit the shared underlying essences of these restoration problems. While specialist models are limited, recent large-scale pretrained generalist models offer powerful, text-driven image editing capabilities. while recent general-purpose systems (e.g., GPT-4o, Flux Kontext, Nano Banana) require detailed prompts and often fail to achieve robust removal on these fine-grained tasks or preserve identity of the scene. Leveraging the common essence of soft effects, i.e., semi-transparent occlusions, we introduce a foundational versatile model UniSER, capable of addressing diverse degradations caused by soft effects within a single framework. Our methodology centers on curating a massive 3.8M-pair dataset to ensure robustness and generalization, which includes novel, physically-plausible data to fill critical gaps in public benchmarks, and a tailored training pipeline that fine-tunes a Diffusion Transformer to learn robust restoration priors from this diverse data, integrating fine-grained mask and strength controls. This synergistic approach allows UniSER to significantly outperform both specialist and generalist models, achieving robust, high-fidelity restoration in the wild.
Learning an Image Editing Model without Image Editing Pairs
Oct 16, 2025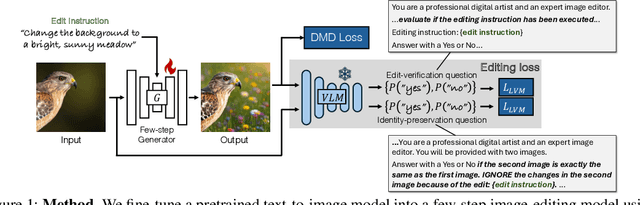
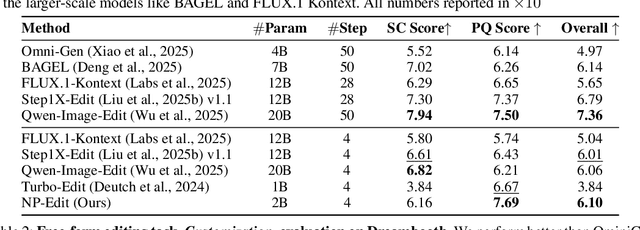

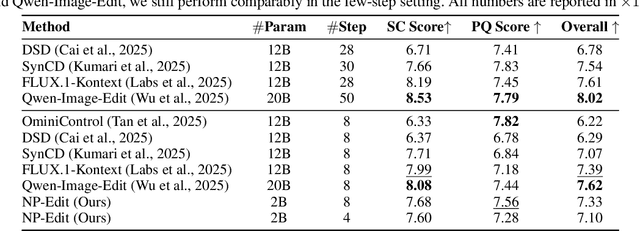
Recent image editing models have achieved impressive results while following natural language editing instructions, but they rely on supervised fine-tuning with large datasets of input-target pairs. This is a critical bottleneck, as such naturally occurring pairs are hard to curate at scale. Current workarounds use synthetic training pairs that leverage the zero-shot capabilities of existing models. However, this can propagate and magnify the artifacts of the pretrained model into the final trained model. In this work, we present a new training paradigm that eliminates the need for paired data entirely. Our approach directly optimizes a few-step diffusion model by unrolling it during training and leveraging feedback from vision-language models (VLMs). For each input and editing instruction, the VLM evaluates if an edit follows the instruction and preserves unchanged content, providing direct gradients for end-to-end optimization. To ensure visual fidelity, we incorporate distribution matching loss (DMD), which constrains generated images to remain within the image manifold learned by pretrained models. We evaluate our method on standard benchmarks and include an extensive ablation study. Without any paired data, our method performs on par with various image editing diffusion models trained on extensive supervised paired data, under the few-step setting. Given the same VLM as the reward model, we also outperform RL-based techniques like Flow-GRPO.
Identifying Prompted Artist Names from Generated Images
Jul 24, 2025A common and controversial use of text-to-image models is to generate pictures by explicitly naming artists, such as "in the style of Greg Rutkowski". We introduce a benchmark for prompted-artist recognition: predicting which artist names were invoked in the prompt from the image alone. The dataset contains 1.95M images covering 110 artists and spans four generalization settings: held-out artists, increasing prompt complexity, multiple-artist prompts, and different text-to-image models. We evaluate feature similarity baselines, contrastive style descriptors, data attribution methods, supervised classifiers, and few-shot prototypical networks. Generalization patterns vary: supervised and few-shot models excel on seen artists and complex prompts, whereas style descriptors transfer better when the artist's style is pronounced; multi-artist prompts remain the most challenging. Our benchmark reveals substantial headroom and provides a public testbed to advance the responsible moderation of text-to-image models. We release the dataset and benchmark to foster further research: https://graceduansu.github.io/IdentifyingPromptedArtists/