 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptRL: Prompt Matters in RL for Flow-Based Image Generation
Feb 01, 2026Flow matching models (FMs) have revolutionized text-to-image (T2I) generation, with reinforcement learning (RL) serving as a critical post-training strategy for alignment with reward objectives. In this research, we show that current RL pipelines for FMs suffer from two underappreciated yet important limitations: sample inefficiency due to insufficient generation diversity, and pronounced prompt overfitting, where models memorize specific training formulations and exhibit dramatic performance collapse when evaluated on semantically equivalent but stylistically varied prompts. We present PromptRL (Prompt Matters in RL for Flow-Based Image Generation), a framework that incorporates language models (LMs) as trainable prompt refinement agents directly within the flow-based RL optimization loop. This design yields two complementary benefits: rapid development of sophisticated prompt rewriting capabilities and, critically, a synergistic training regime that reshapes the optimization dynamics. PromptRL achieves state-of-the-art performance across multiple benchmarks, obtaining scores of 0.97 on GenEval, 0.98 on OCR accuracy, and 24.05 on PickScore. Furthermore, we validate the effectiveness of our RL approach on large-scale image editing models, improving the EditReward of FLUX.1-Kontext from 1.19 to 1.43 with only 0.06 million rollouts, surpassing Gemini 2.5 Flash Image (also known as Nano Banana), which scores 1.37, and achieving comparable performance with ReasonNet (1.44), which relied on fine-grained data annotations along with a complex multi-stage training. Our extensive experiments empirically demonstrate that PromptRL consistently achieves higher performance ceilings while requiring over 2$\times$ fewer rollouts compared to naive flow-only RL. Our code is available at https://github.com/G-U-N/UniRL.
Improved Distribution Matching Distillation for Fast Image Synthesis
May 23, 2024
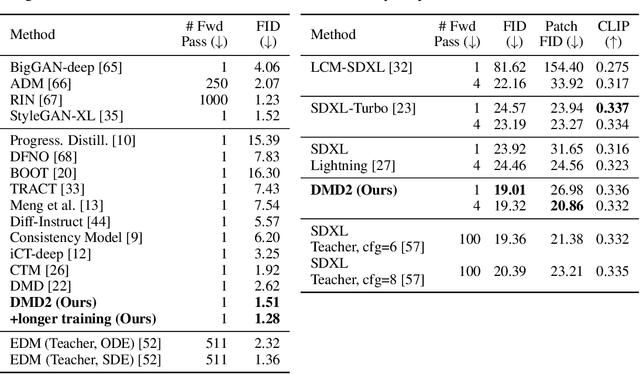

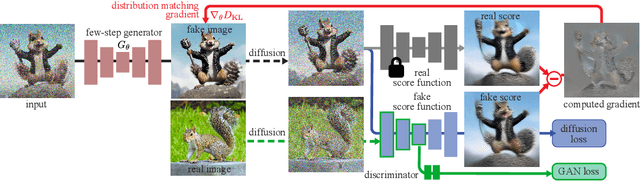
Recent approaches have shown promises distilling diffusion models into efficient one-step generators. Among them, Distribution Matching Distillation (DMD) produces one-step generators that match their teacher in distribution, without enforcing a one-to-one correspondence with the sampling trajectories of their teachers. However, to ensure stable training, DMD requires an additional regression loss computed using a large set of noise-image pairs generated by the teacher with many steps of a deterministic sampler. This is costly for large-scale text-to-image synthesis and limits the student's quality, tying it too closely to the teacher's original sampling paths. We introduce DMD2, a set of techniques that lift this limitation and improve DMD training. First, we eliminate the regression loss and the need for expensive dataset construction. We show that the resulting instability is due to the fake critic not estimating the distribution of generated samples accurately and propose a two time-scale update rule as a remedy. Second, we integrate a GAN loss into the distillation procedure, discriminating between generated samples and real images. This lets us train the student model on real data, mitigating the imperfect real score estimation from the teacher model, and enhancing quality. Lastly, we modify the training procedure to enable multi-step sampling. We identify and address the training-inference input mismatch problem in this setting, by simulating inference-time generator samples during training time. Taken together, our improvements set new benchmarks in one-step image generation, with FID scores of 1.28 on ImageNet-64x64 and 8.35 on zero-shot COCO 2014, surpassing the original teacher despite a 500X reduction in inference cost. Further, we show our approach can generate megapixel images by distilling SDXL, demonstrating exceptional visual quality among few-step methods.
Distilling Diffusion Models into Conditional GANs
May 09, 2024


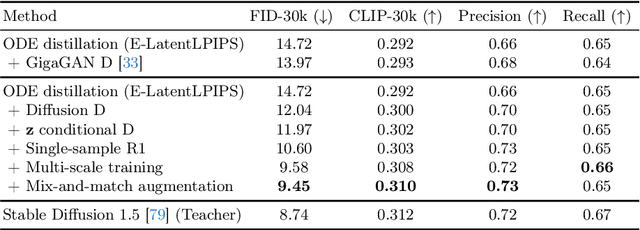
We propose a method to distill a complex multistep diffusion model into a single-step conditional GAN student model, dramatically accelerating inference, while preserving image quality. Our approach interprets diffusion distillation as a paired image-to-image translation task, using noise-to-image pairs of the diffusion model's ODE trajectory. For efficient regression loss computation, we propose E-LatentLPIPS, a perceptual loss operating directly in diffusion model's latent space, utilizing an ensemble of augmentations. Furthermore, we adapt a diffusion model to construct a multi-scale discriminator with a text alignment loss to build an effective conditional GAN-based formulation. E-LatentLPIPS converges more efficiently than many existing distillation methods, even accounting for dataset construction costs. We demonstrate that our one-step generator outperforms cutting-edge one-step diffusion distillation models - DMD, SDXL-Turbo, and SDXL-Lightning - on the zero-shot COCO benchmark.
Editable Image Elements for Controllable Synthesis
Apr 24, 2024
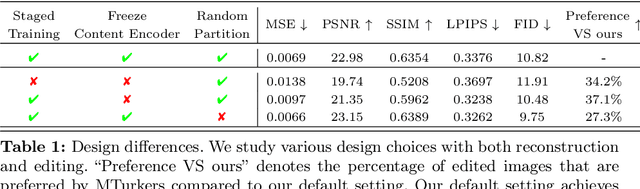
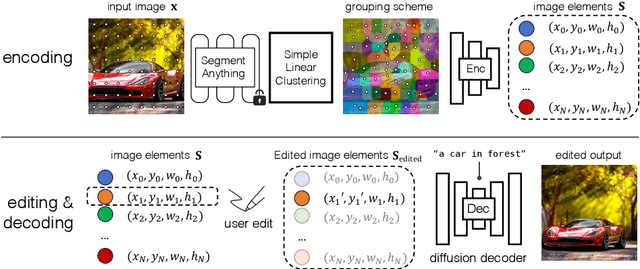
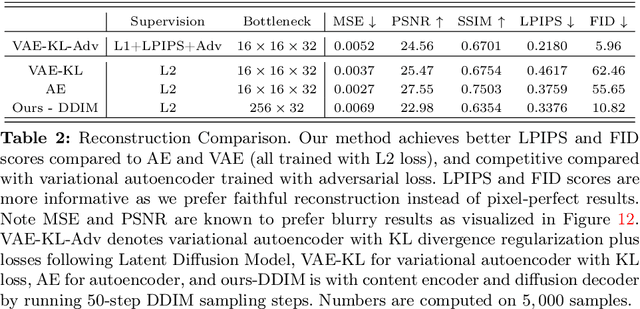
Diffusion models have made significant advances in text-guided synthesis tasks. However, editing user-provided images remains challenging, as the high dimensional noise input space of diffusion models is not naturally suited for image inversion or spatial editing. In this work, we propose an image representation that promotes spatial editing of input images using a diffusion model. Concretely, we learn to encode an input into "image elements" that can faithfully reconstruct an input image. These elements can be intuitively edited by a user, and are decoded by a diffusion model into realistic images. We show the effectiveness of our representation on various image editing tasks, such as object resizing, rearrangement, dragging, de-occlusion, removal, variation, and image composition. Project page: https://jitengmu.github.io/Editable_Image_Elements/
Customizing Text-to-Image Diffusion with Camera Viewpoint Control
Apr 18, 2024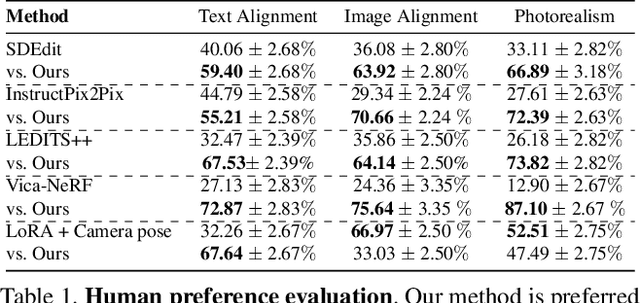


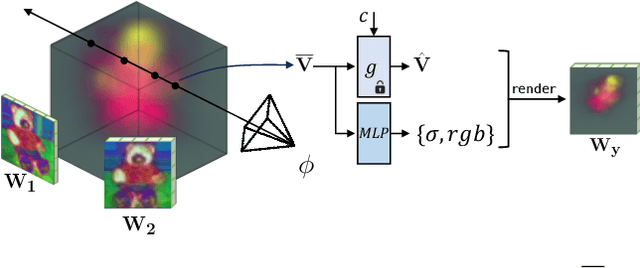
Model customization introduces new concepts to existing text-to-image models, enabling the generation of the new concept in novel contexts. However, such methods lack accurate camera view control w.r.t the object, and users must resort to prompt engineering (e.g., adding "top-view") to achieve coarse view control. In this work, we introduce a new task -- enabling explicit control of camera viewpoint for model customization. This allows us to modify object properties amongst various background scenes via text prompts, all while incorporating the target camera pose as additional control. This new task presents significant challenges in merging a 3D representation from the multi-view images of the new concept with a general, 2D text-to-image model. To bridge this gap, we propose to condition the 2D diffusion process on rendered, view-dependent features of the new object. During training, we jointly adapt the 2D diffusion modules and 3D feature predictions to reconstruct the object's appearance and geometry while reducing overfitting to the input multi-view images. Our method outperforms existing image editing and model personalization baselines in preserving the custom object's identity while following the input text prompt and the object's camera pose.
Lazy Diffusion Transformer for Interactive Image Editing
Apr 18, 2024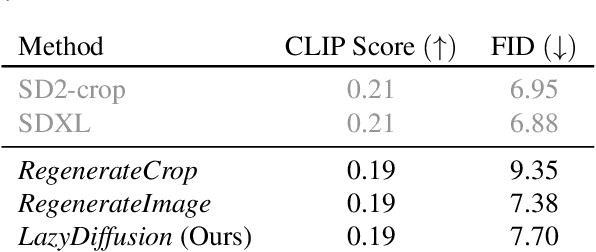

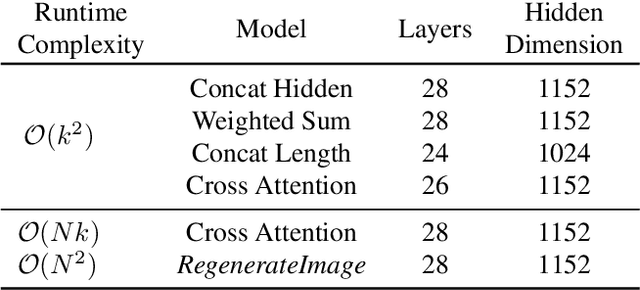

We introduce a novel diffusion transformer, LazyDiffusion, that generates partial image updates efficiently. Our approach targets interactive image editing applications in which, starting from a blank canvas or an image, a user specifies a sequence of localized image modifications using binary masks and text prompts. Our generator operates in two phases. First, a context encoder processes the current canvas and user mask to produce a compact global context tailored to the region to generate. Second, conditioned on this context, a diffusion-based transformer decoder synthesizes the masked pixels in a "lazy" fashion, i.e., it only generates the masked region. This contrasts with previous works that either regenerate the full canvas, wasting time and computation, or confine processing to a tight rectangular crop around the mask, ignoring the global image context altogether. Our decoder's runtime scales with the mask size, which is typically small, while our encoder introduces negligible overhead. We demonstrate that our approach is competitive with state-of-the-art inpainting methods in terms of quality and fidelity while providing a 10x speedup for typical user interactions, where the editing mask represents 10% of the image.
VideoGigaGAN: Towards Detail-rich Video Super-Resolution
Apr 18, 2024

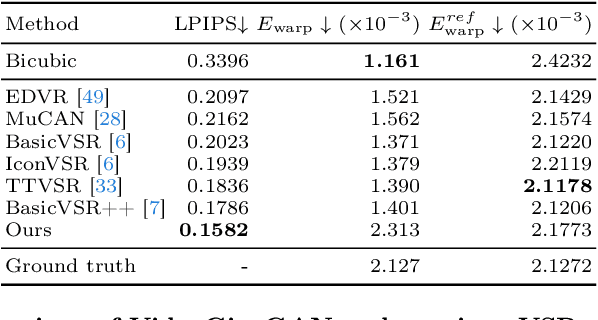

Video super-resolution (VSR) approaches have shown impressive temporal consistency in upsampled videos. However, these approaches tend to generate blurrier results than their image counterparts as they are limited in their generative capability. This raises a fundamental question: can we extend the success of a generative image upsampler to the VSR task while preserving the temporal consistency? We introduce VideoGigaGAN, a new generative VSR model that can produce videos with high-frequency details and temporal consistency. VideoGigaGAN builds upon a large-scale image upsampler -- GigaGAN. Simply inflating GigaGAN to a video model by adding temporal modules produces severe temporal flickering. We identify several key issues and propose techniques that significantly improve the temporal consistency of upsampled videos. Our experiments show that, unlike previous VSR methods, VideoGigaGAN generates temporally consistent videos with more fine-grained appearance details. We validate the effectiveness of VideoGigaGAN by comparing it with state-of-the-art VSR models on public datasets and showcasing video results with $8\times$ super-resolution.
One-Step Image Translation with Text-to-Image Models
Mar 18, 2024



In this work, we address two limitations of existing conditional diffusion models: their slow inference speed due to the iterative denoising process and their reliance on paired data for model fine-tuning. To tackle these issues, we introduce a general method for adapting a single-step diffusion model to new tasks and domains through adversarial learning objectives. Specifically, we consolidate various modules of the vanilla latent diffusion model into a single end-to-end generator network with small trainable weights, enhancing its ability to preserve the input image structure while reducing overfitting. We demonstrate that, for unpaired settings, our model CycleGAN-Turbo outperforms existing GAN-based and diffusion-based methods for various scene translation tasks, such as day-to-night conversion and adding/removing weather effects like fog, snow, and rain. We extend our method to paired settings, where our model pix2pix-Turbo is on par with recent works like Control-Net for Sketch2Photo and Edge2Image, but with a single-step inference. This work suggests that single-step diffusion models can serve as strong backbones for a range of GAN learning objectives. Our code and models are available at https://github.com/GaParmar/img2img-turbo.
Multi-Scale Semantic Segmentation with Modified MBConv Blocks
Feb 07, 2024Recently, MBConv blocks, initially designed for efficiency in resource-limited settings and later adapted for cutting-edge image classification performances, have demonstrated significant potential in image classification tasks. Despite their success, their application in semantic segmentation has remained relatively unexplored. This paper introduces a novel adaptation of MBConv blocks specifically tailored for semantic segmentation. Our modification stems from the insight that semantic segmentation requires the extraction of more detailed spatial information than image classification. We argue that to effectively perform multi-scale semantic segmentation, each branch of a U-Net architecture, regardless of its resolution, should possess equivalent segmentation capabilities. By implementing these changes, our approach achieves impressive mean Intersection over Union (IoU) scores of 84.5% and 84.0% on the Cityscapes test and validation datasets, respectively, demonstrating the efficacy of our proposed modifications in enhancing semantic segmentation performance.
Jump Cut Smoothing for Talking Heads
Jan 11, 2024



A jump cut offers an abrupt, sometimes unwanted change in the viewing experience. We present a novel framework for smoothing these jump cuts, in the context of talking head videos. We leverage the appearance of the subject from the other source frames in the video, fusing it with a mid-level representation driven by DensePose keypoints and face landmarks. To achieve motion, we interpolate the keypoints and landmarks between the end frames around the cut. We then use an image translation network from the keypoints and source frames, to synthesize pixels. Because keypoints can contain errors, we propose a cross-modal attention scheme to select and pick the most appropriate source amongst multiple options for each key point. By leveraging this mid-level representation, our method can achieve stronger results than a strong video interpolation baseline. We demonstrate our method on various jump cuts in the talking head videos, such as cutting filler words, pauses, and even random cuts. Our experiments show that we can achieve seamless transitions, even in the challenging cases where the talking head rotates or moves drastically in the jump cut.