 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bottom-Up Approach to Class-Agnostic Image Segmentation
Sep 20, 2024


Class-agnostic image segmentation is a crucial component in automating image editing workflows, especially in contexts where object selection traditionally involves interactive tools. Existing methods in the literature often adhere to top-down formulations, following the paradigm of class-based approaches, where object detection precedes per-object segmentation. In this work, we present a novel bottom-up formulation for addressing the class-agnostic segmentation problem. We supervise our network directly on the projective sphere of its feature space, employing losses inspired by metric learning literature as well as losses defined in a novel segmentation-space representation. The segmentation results are obtained through a straightforward mean-shift clustering of the estimated features. Our bottom-up formulation exhibits exceptional generalization capability, even when trained on datasets designed for class-based segmentation. We further showcase the effectiveness of our generic approach by addressing the challenging task of cell and nucleus segmentation. We believe that our bottom-up formulation will offer valuable insights into diverse segmentation challenges in the literature.
Distilling Diffusion Models into Conditional GANs
May 09, 2024


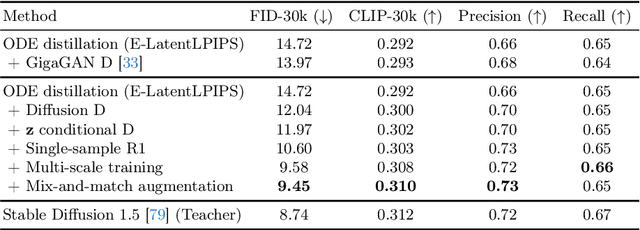
We propose a method to distill a complex multistep diffusion model into a single-step conditional GAN student model, dramatically accelerating inference, while preserving image quality. Our approach interprets diffusion distillation as a paired image-to-image translation task, using noise-to-image pairs of the diffusion model's ODE trajectory. For efficient regression loss computation, we propose E-LatentLPIPS, a perceptual loss operating directly in diffusion model's latent space, utilizing an ensemble of augmentations. Furthermore, we adapt a diffusion model to construct a multi-scale discriminator with a text alignment loss to build an effective conditional GAN-based formulation. E-LatentLPIPS converges more efficiently than many existing distillation methods, even accounting for dataset construction costs. We demonstrate that our one-step generator outperforms cutting-edge one-step diffusion distillation models - DMD, SDXL-Turbo, and SDXL-Lightning - on the zero-shot COCO benchmark.
Scaling up GANs for Text-to-Image Synthesis
Mar 09, 2023The recent success of text-to-image synthesis has taken the world by storm and captured the general public's imagination. From a technical standpoint, it also marked a drastic change in the favored architecture to design generative image models. GANs used to be the de facto choice, with techniques like StyleGAN. With DALL-E 2, auto-regressive and diffusion models became the new standard for large-scale generative models overnight. This rapid shift raises a fundamental question: can we scale up GANs to benefit from large datasets like LAION? We find that na\"Ively increasing the capacity of the StyleGAN architecture quickly becomes unstable. We introduce GigaGAN, a new GAN architecture that far exceeds this limit, demonstrating GANs as a viable option for text-to-image synthesis. GigaGAN offers three major advantages. First, it is orders of magnitude faster at inference time, taking only 0.13 seconds to synthesize a 512px image. Second, it can synthesize high-resolution images, for example, 16-megapixel pixels in 3.66 seconds. Finally, GigaGAN supports various latent space editing applications such as latent interpolation, style mixing, and vector arithmetic operations.
Neural Neighbor Style Transfer
Mar 24, 2022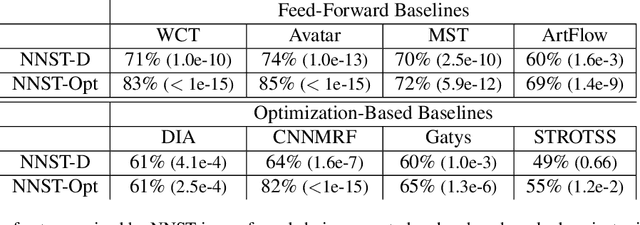
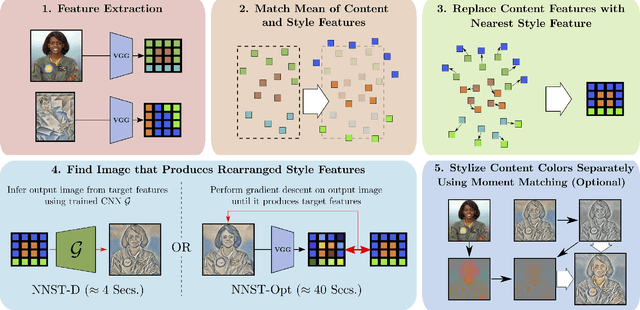


We propose Neural Neighbor Style Transfer (NNST), a pipeline that offers state-of-the-art quality, generalization, and competitive efficiency for artistic style transfer. Our approach is based on explicitly replacing neural features extracted from the content input (to be stylized) with those from a style exemplar, then synthesizing the final output based on these rearranged features. While the spirit of our approach is similar to prior work, we show that our design decisions dramatically improve the final visual quality.
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging
May 28, 2021



Neural networks have shown great abilities in estimating depth from a single image. However, the inferred depth maps are well below one-megapixel resolution and often lack fine-grained details, which limits their practicality. Our method builds on our analysis on how the input resolution and the scene structure affects depth estimation performance. We demonstrate that there is a trade-off between a consistent scene structure and the high-frequency details, and merge low- and high-resolution estimations to take advantage of this duality using a simple depth merging network. We present a double estimation method that improves the whole-image depth estimation and a patch selection method that adds local details to the final result. We demonstrate that by merging estimations at different resolutions with changing context, we can generate multi-megapixel depth maps with a high level of detail using a pre-trained model.
* For more details visit http://yaksoy.github.io/highresdepth/
Transforming and Projecting Images into Class-conditional Generative Networks
May 04, 2020
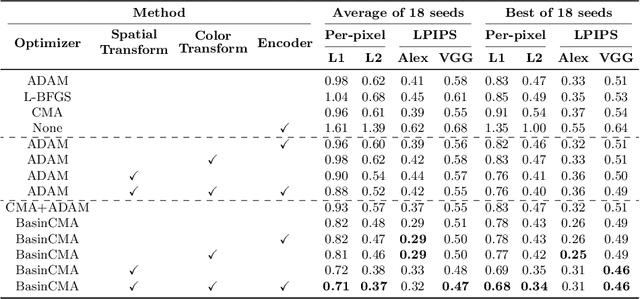
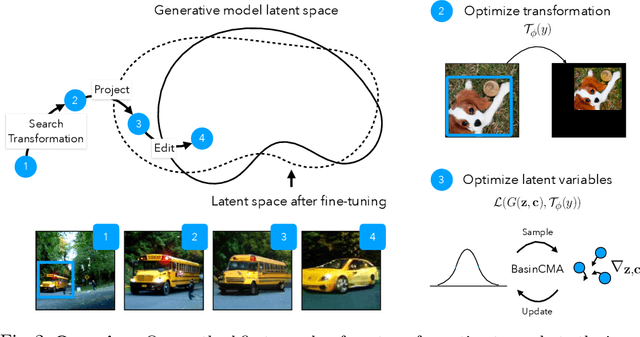

We present a method for projecting an input image into the space of a class-conditional generative neural network. We propose a method that optimizes for transformation to counteract the model biases in a generative neural networks. Specifically, we demonstrate that one can solve for image translation, scale, and global color transformation, during the projection optimization to address the object-center bias of a Generative Adversarial Network. This projection process poses a difficult optimization problem, and purely gradient-based optimizations fail to find good solutions. We describe a hybrid optimization strategy that finds good projections by estimating transformations and class parameters. We show the effectiveness of our method on real images and further demonstrate how the corresponding projections lead to better edit-ability of these images.
GANSpace: Discovering Interpretable GAN Controls
Apr 06, 2020
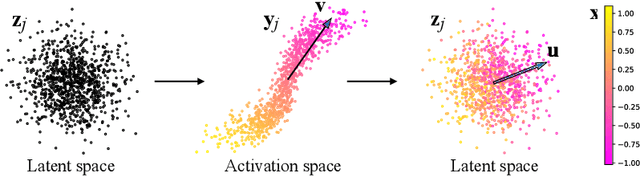


This paper describes a simple technique to analyze Generative Adversarial Networks (GANs) and create interpretable controls for image synthesis, such as change of viewpoint, aging, lighting, and time of day. We identify important latent directions based on Principal Components Analysis (PCA) applied in activation space. Then, we show that interpretable edits can be defined based on layer-wise application of these edit directions. Moreover, we show that BigGAN can be controlled with layer-wise inputs in a StyleGAN-like manner. A user may identify a large number of interpretable controls with these mechanisms. We demonstrate results on GANs from various datasets.
Deep Photo Style Transfer
Apr 11, 2017



This paper introduces a deep-learning approach to photographic style transfer that handles a large variety of image content while faithfully transferring the reference style. Our approach builds upon the recent work on painterly transfer that separates style from the content of an image by considering different layers of a neural network. However, as is, this approach is not suitable for photorealistic style transfer. Even when both the input and reference images are photographs, the output still exhibits distortions reminiscent of a painting. Our contribution is to constrain the transformation from the input to the output to be locally affine in colorspace, and to express this constraint as a custom fully differentiable energy term. We show that this approach successfully suppresses distortion and yields satisfying photorealistic style transfers in a broad variety of scenarios, including transfer of the time of day, weather, season, and artistic edits.
Automatic Photo Adjustment Using Deep Neural Networks
May 16, 2015



Photo retouching enables photographers to invoke dramatic visual impressions by artistically enhancing their photos through stylistic color and tone adjustments. However, it is also a time-consuming and challenging task that requires advanced skills beyond the abilities of casual photographers. Using an automated algorithm is an appealing alternative to manual work but such an algorithm faces many hurdles. Many photographic styles rely on subtle adjustments that depend on the image content and even its semantics. Further, these adjustments are often spatially varying. Because of these characteristics, existing automatic algorithms are still limited and cover only a subset of these challenges. Recently, deep machine learning has shown unique abilities to address hard problems that resisted machine algorithms for long. This motivated us to explore the use of deep learning in the context of photo editing. In this paper, we explain how to formulate the automatic photo adjustment problem in a way suitable for this approach. We also introduce an image descriptor that accounts for the local semantics of an image. Our experiments demonstrate that our deep learning formulation applied using these descriptors successfully capture sophisticated photographic styles. In particular and unlike previous techniques, it can model local adjustments that depend on the image semantics. We show on several examples that this yields results that are qualitatively and quantitatively better than previous work.