 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplicial covering dimension of extremal concept classes
Nov 14, 2025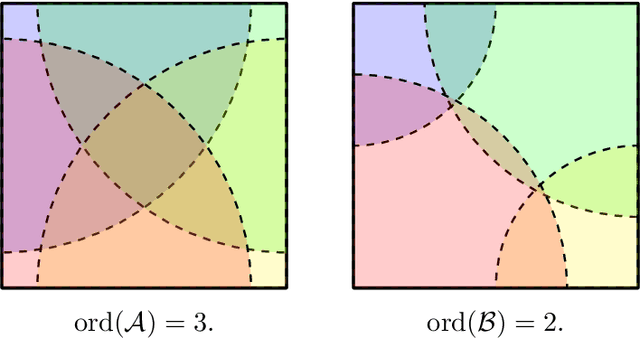



Dimension theory is a branch of topology concerned with defining and analyzing dimensions of geometric and topological spaces in purely topological terms. In this work, we adapt the classical notion of topological dimension (Lebesgue covering) to binary concept classes. The topological space naturally associated with a concept class is its space of realizable distributions. The loss function and the class itself induce a simplicial structure on this space, with respect to which we define a simplicial covering dimension. We prove that for finite concept classes, this simplicial covering dimension exactly characterizes the list replicability number (equivalently, global stability) in PAC learning. This connection allows us to apply tools from classical dimension theory to compute the exact list replicability number of the broad family of extremal concept classes.
Borsuk-Ulam and Replicable Learning of Large-Margin Halfspaces
Mar 19, 2025Recent advances in learning theory have established that, for total concepts, list replicability, global stability, differentially private (DP) learnability, and shared-randomness replicability coincide precisely with the finiteness of the Littlestone dimension. Does the same hold for partial concept classes? We answer this question by studying the large-margin half-spaces class, which has bounded Littlestone dimension and is purely DP-learnable and shared-randomness replicable even in high dimensions. We prove that the list replicability number of $\gamma$-margin half-spaces satisfies \[ \frac{d}{2} + 1 \le \mathrm{LR}(H_{\gamma}^d) \le d, \] which increases with the dimension $d$. This reveals a surprising separation for partial concepts: list replicability and global stability do not follow from bounded Littlestone dimension, DP-learnability, or shared-randomness replicability. By applying our main theorem, we also answer the following open problems. - We prove that any disambiguation of an infinite-dimensional large-margin half-space to a total concept class has unbounded Littlestone dimension, answering an open question of Alon et al. (FOCS '21). - We prove that the maximum list-replicability number of any *finite* set of points and homogeneous half-spaces in $d$-dimensional Euclidean space is $d$, resolving a problem of Chase et al. (FOCS '23). - We prove that any disambiguation of the Gap Hamming Distance problem in the large gap regime has unbounded public-coin randomized communication complexity. This answers an open problem of Fang et al. (STOC '25). We prove the lower bound via a topological argument involving the local Borsuk-Ulam theorem of Chase et al. (STOC '24). For the upper bound, we design a learning rule that relies on certain triangulations of the cross-polytope and recent results on the generalization properties of SVM.
A Bottom-Up Approach to Class-Agnostic Image Segmentation
Sep 20, 2024


Class-agnostic image segmentation is a crucial component in automating image editing workflows, especially in contexts where object selection traditionally involves interactive tools. Existing methods in the literature often adhere to top-down formulations, following the paradigm of class-based approaches, where object detection precedes per-object segmentation. In this work, we present a novel bottom-up formulation for addressing the class-agnostic segmentation problem. We supervise our network directly on the projective sphere of its feature space, employing losses inspired by metric learning literature as well as losses defined in a novel segmentation-space representation. The segmentation results are obtained through a straightforward mean-shift clustering of the estimated features. Our bottom-up formulation exhibits exceptional generalization capability, even when trained on datasets designed for class-based segmentation. We further showcase the effectiveness of our generic approach by addressing the challenging task of cell and nucleus segmentation. We believe that our bottom-up formulation will offer valuable insights into diverse segmentation challenges in the literature.