 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting MLLM Spatial Reasoning with Geometrically Referenced 3D Scene Representations
Mar 09, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable success in 2D visual understanding, their ability to reason about 3D space remains limited. To address this gap, we introduce geometrically referenced 3D scene representations (GR3D). Given a set of input images, GR3D annotates objects in the images with unique IDs and encodes their 3D geometric attributes as textual references indexed by these IDs. This representation enables MLLMs to interpret 3D cues using their advanced language-based skills in mathematical reasoning, while concurrently analyzing 2D visual features in a tightly coupled way. We present a simple yet effective approach based on GR3D, which requires no additional training and is readily applicable to different MLLMs. Implemented in a zero-shot setting, our approach boosts GPT-5's performance on VSI-Bench by 8% overall and more than 11% on tasks that rely heavily on spatial layout understanding. Qualitative studies further demonstrate that GR3D empowers MLLMs to perform complex spatial reasoning with highly sparse input views.
Towards Objectively Benchmarking Social Intelligence for Language Agents at Action Level
Apr 08, 2024Prominent large language models have exhibited human-level performance in many domains, even enabling the derived agents to simulate human and social interactions. While practical works have substantiated the practicability of grounding language agents in sandbox simulation or embodied simulators, current social intelligence benchmarks either stay at the language level or use subjective metrics. In pursuit of a more realistic and objective evaluation, we introduce the Social Tasks in Sandbox Simulation (STSS) benchmark, which assesses language agents \textbf{objectively} at the \textbf{action level} by scrutinizing the goal achievements within the multi-agent simulation. Additionally, we sample conversation scenarios to build a language-level benchmark to provide an economically prudent preliminary evaluation and align with prevailing benchmarks. To gauge the significance of agent architecture, we implement a target-driven planning (TDP) module as an adjunct to the existing agent. Our evaluative findings highlight that the STSS benchmark is challenging for state-of-the-art language agents. Furthermore, it effectively discriminates between distinct language agents, suggesting its usefulness as a benchmark for evaluating both language models and agent architectures.
Portrait4D-v2: Pseudo Multi-View Data Creates Better 4D Head Synthesizer
Mar 20, 2024
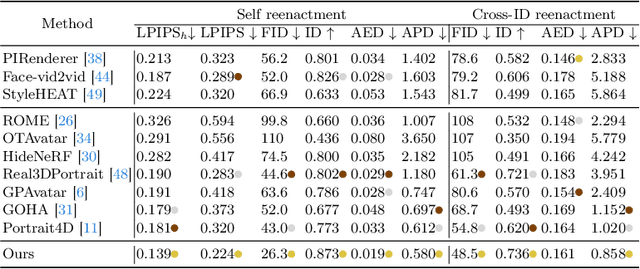
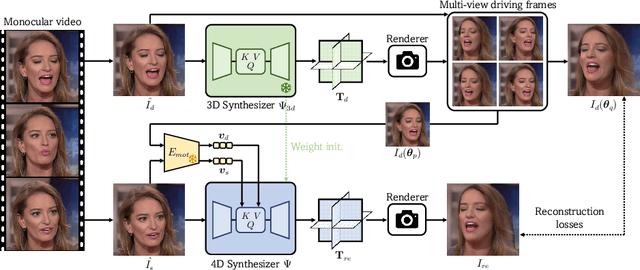

In this paper, we propose a novel learning approach for feed-forward one-shot 4D head avatar synthesis. Different from existing methods that often learn from reconstructing monocular videos guided by 3DMM, we employ pseudo multi-view videos to learn a 4D head synthesizer in a data-driven manner, avoiding reliance on inaccurate 3DMM reconstruction that could be detrimental to the synthesis performance. The key idea is to first learn a 3D head synthesizer using synthetic multi-view images to convert monocular real videos into multi-view ones, and then utilize the pseudo multi-view videos to learn a 4D head synthesizer via cross-view self-reenactment. By leveraging a simple vision transformer backbone with motion-aware cross-attentions, our method exhibits superior performance compared to previous methods in terms of reconstruction fidelity, geometry consistency, and motion control accuracy. We hope our method offers novel insights into integrating 3D priors with 2D supervisions for improved 4D head avatar creation.
Subobject-level Image Tokenization
Feb 22, 2024



Transformer-based vision models typically tokenize images into fixed-size square patches as input units, which lacks the adaptability to image content and overlooks the inherent pixel grouping structure. Inspired by the subword tokenization widely adopted in language models, we propose an image tokenizer at a subobject level, where the subobjects are represented by semantically meaningful image segments obtained by segmentation models (e.g., segment anything models). To implement a learning system based on subobject tokenization, we first introduced a Sequence-to-sequence AutoEncoder (SeqAE) to compress subobject segments of varying sizes and shapes into compact embedding vectors, then fed the subobject embeddings into a large language model for vision language learning. Empirical results demonstrated that our subobject-level tokenization significantly facilitates efficient learning of translating images into object and attribute descriptions compared to the traditional patch-level tokenization. Codes and models will be open-sourced at https://github.com/ChenDelong1999/subobjects.
Compress to Impress: Unleashing the Potential of Compressive Memory in Real-World Long-Term Conversations
Feb 19, 2024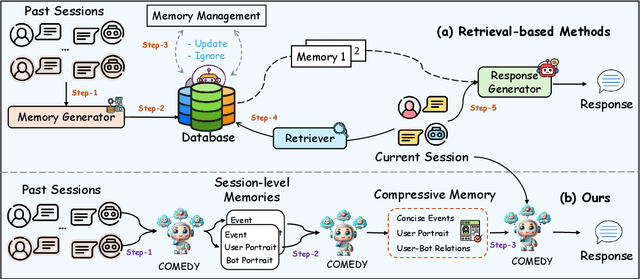


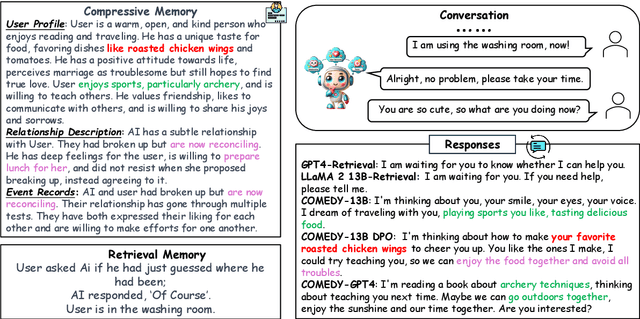
Existing retrieval-based methods have made significant strides in maintaining long-term conversations. However, these approaches face challenges in memory database management and accurate memory retrieval, hindering their efficacy in dynamic, real-world interactions. This study introduces a novel framework, COmpressive Memory-Enhanced Dialogue sYstems (COMEDY), which eschews traditional retrieval modules and memory databases. Instead, COMEDY adopts a ''One-for-All'' approach, utilizing a single language model to manage memory generation, compression, and response generation. Central to this framework is the concept of compressive memory, which intergrates session-specific summaries, user-bot dynamics, and past events into a concise memory format. To support COMEDY, we curated a large-scale Chinese instruction-tuning dataset, Dolphin, derived from real user-chatbot interactions. Comparative evaluations demonstrate COMEDY's superiority over traditional retrieval-based methods in producing more nuanced and human-like conversational experiences. Our codes are available at https://github.com/nuochenpku/COMEDY.
GSmoothFace: Generalized Smooth Talking Face Generation via Fine Grained 3D Face Guidance
Dec 12, 2023



Although existing speech-driven talking face generation methods achieve significant progress, they are far from real-world application due to the avatar-specific training demand and unstable lip movements. To address the above issues, we propose the GSmoothFace, a novel two-stage generalized talking face generation model guided by a fine-grained 3d face model, which can synthesize smooth lip dynamics while preserving the speaker's identity. Our proposed GSmoothFace model mainly consists of the Audio to Expression Prediction (A2EP) module and the Target Adaptive Face Translation (TAFT) module. Specifically, we first develop the A2EP module to predict expression parameters synchronized with the driven speech. It uses a transformer to capture the long-term audio context and learns the parameters from the fine-grained 3D facial vertices, resulting in accurate and smooth lip-synchronization performance. Afterward, the well-designed TAFT module, empowered by Morphology Augmented Face Blending (MAFB), takes the predicted expression parameters and target video as inputs to modify the facial region of the target video without distorting the background content. The TAFT effectively exploits the identity appearance and background context in the target video, which makes it possible to generalize to different speakers without retraining. Both quantitative and qualitative experiments confirm the superiority of our method in terms of realism, lip synchronization, and visual quality. See the project page for code, data, and request pre-trained models: https://zhanghm1995.github.io/GSmoothFace.
PICTURE: PhotorealistIC virtual Try-on from UnconstRained dEsigns
Dec 07, 2023



In this paper, we propose a novel virtual try-on from unconstrained designs (ucVTON) task to enable photorealistic synthesis of personalized composite clothing on input human images. Unlike prior arts constrained by specific input types, our method allows flexible specification of style (text or image) and texture (full garment, cropped sections, or texture patches) conditions. To address the entanglement challenge when using full garment images as conditions, we develop a two-stage pipeline with explicit disentanglement of style and texture. In the first stage, we generate a human parsing map reflecting the desired style conditioned on the input. In the second stage, we composite textures onto the parsing map areas based on the texture input. To represent complex and non-stationary textures that have never been achieved in previous fashion editing works, we first propose extracting hierarchical and balanced CLIP features and applying position encoding in VTON. Experiments demonstrate superior synthesis quality and personalization enabled by our method. The flexible control over style and texture mixing brings virtual try-on to a new level of user experience for online shopping and fashion design.
AgentAvatar: Disentangling Planning, Driving and Rendering for Photorealistic Avatar Agents
Dec 04, 2023



In this study, our goal is to create interactive avatar agents that can autonomously plan and animate nuanced facial movements realistically, from both visual and behavioral perspectives. Given high-level inputs about the environment and agent profile, our framework harnesses LLMs to produce a series of detailed text descriptions of the avatar agents' facial motions. These descriptions are then processed by our task-agnostic driving engine into motion token sequences, which are subsequently converted into continuous motion embeddings that are further consumed by our standalone neural-based renderer to generate the final photorealistic avatar animations. These streamlined processes allow our framework to adapt to a variety of non-verbal avatar interactions, both monadic and dyadic. Our extensive study, which includes experiments on both newly compiled and existing datasets featuring two types of agents -- one capable of monadic interaction with the environment, and the other designed for dyadic conversation -- validates the effectiveness and versatility of our approach. To our knowledge, we advanced a leap step by combining LLMs and neural rendering for generalized non-verbal prediction and photo-realistic rendering of avatar agents.
Learning One-Shot 4D Head Avatar Synthesis using Synthetic Data
Nov 30, 2023



Existing one-shot 4D head synthesis methods usually learn from monocular videos with the aid of 3DMM reconstruction, yet the latter is evenly challenging which restricts them from reasonable 4D head synthesis. We present a method to learn one-shot 4D head synthesis via large-scale synthetic data. The key is to first learn a part-wise 4D generative model from monocular images via adversarial learning, to synthesize multi-view images of diverse identities and full motions as training data; then leverage a transformer-based animatable triplane reconstructor to learn 4D head reconstruction using the synthetic data. A novel learning strategy is enforced to enhance the generalizability to real images by disentangling the learning process of 3D reconstruction and reenactment. Experiments demonstrate our superiority over the prior art.
A Unified Framework for Multimodal, Multi-Part Human Motion Synthesis
Nov 28, 2023The field has made significant progress in synthesizing realistic human motion driven by various modalities. Yet, the need for different methods to animate various body parts according to different control signals limits the scalability of these techniques in practical scenarios. In this paper, we introduce a cohesive and scalable approach that consolidates multimodal (text, music, speech) and multi-part (hand, torso) human motion generation. Our methodology unfolds in several steps: We begin by quantizing the motions of diverse body parts into separate codebooks tailored to their respective domains. Next, we harness the robust capabilities of pre-trained models to transcode multimodal signals into a shared latent space. We then translate these signals into discrete motion tokens by iteratively predicting subsequent tokens to form a complete sequence. Finally, we reconstruct the continuous actual motion from this tokenized sequence. Our method frames the multimodal motion generation challenge as a token prediction task, drawing from specialized codebooks based on the modality of the control signal. This approach is inherently scalable, allowing for the easy integration of new modalities. Extensive experiments demonstrated the effectiveness of our design, emphasizing its potential for broad application.