 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPG: A Repository Planning Graph for Unified and Scalable Codebase Generation
Sep 19, 2025



Large language models excel at function- and file-level code generation, yet generating complete repositories from scratch remains a fundamental challenge. This process demands coherent and reliable planning across proposal- and implementation-level stages, while natural language, due to its ambiguity and verbosity, is ill-suited for faithfully representing complex software structures. To address this, we introduce the Repository Planning Graph (RPG), a persistent representation that unifies proposal- and implementation-level planning by encoding capabilities, file structures, data flows, and functions in one graph. RPG replaces ambiguous natural language with an explicit blueprint, enabling long-horizon planning and scalable repository generation. Building on RPG, we develop ZeroRepo, a graph-driven framework for repository generation from scratch. It operates in three stages: proposal-level planning and implementation-level refinement to construct the graph, followed by graph-guided code generation with test validation. To evaluate this setting, we construct RepoCraft, a benchmark of six real-world projects with 1,052 tasks. On RepoCraft, ZeroRepo produces repositories averaging nearly 36K LOC, roughly 3.9$\times$ the strongest baseline (Claude Code) and about 64$\times$ other baselines. It attains 81.5% functional coverage and a 69.7% pass rate, exceeding Claude Code by 27.3 and 35.8 percentage points, respectively. Further analysis shows that RPG models complex dependencies, enables progressively more sophisticated planning through near-linear scaling, and enhances LLM understanding of repositories, thereby accelerating agent localization.
RePrompt: Reasoning-Augmented Reprompting for Text-to-Image Generation via Reinforcement Learning
May 23, 2025Despite recent progress in text-to-image (T2I) generation, existing models often struggle to faithfully capture user intentions from short and under-specified prompts. While prior work has attempted to enhance prompts using large language models (LLMs), these methods frequently generate stylistic or unrealistic content due to insufficient grounding in visual semantics and real-world composition. Inspired by recent advances in reasoning for language model, we propose RePrompt, a novel reprompting framework that introduces explicit reasoning into the prompt enhancement process via reinforcement learning. Instead of relying on handcrafted rules or stylistic rewrites, our method trains a language model to generate structured, self-reflective prompts by optimizing for image-level outcomes. The tailored reward models assesse the generated images in terms of human preference, semantic alignment, and visual composition, providing indirect supervision to refine prompt generation. Our approach enables end-to-end training without human-annotated data. Experiments on GenEval and T2I-Compbench show that RePrompt significantly boosts spatial layout fidelity and compositional generalization across diverse T2I backbones, establishing new state-of-the-art results.
MAIN: Mutual Alignment Is Necessary for instruction tuning
Apr 17, 2025Instruction tuning has enabled large language models (LLMs) to achieve remarkable performance, but its success heavily depends on the availability of large-scale, high-quality instruction-response pairs. However, current methods for scaling up data generation often overlook a crucial aspect: the alignment between instructions and responses. We hypothesize that high-quality instruction-response pairs are not defined by the individual quality of each component, but by the extent of their alignment with each other. To address this, we propose a Mutual Alignment Framework (MAIN) that ensures coherence between the instruction and response through mutual constraints. Experiments demonstrate that models such as LLaMA and Mistral, fine-tuned within this framework, outperform traditional methods across multiple benchmarks. This approach underscores the critical role of instruction-response alignment in enabling scalable and high-quality instruction tuning for LLMs.
GeAR: Generation Augmented Retrieval
Jan 06, 2025



Document retrieval techniques form the foundation for the development of large-scale information systems. The prevailing methodology is to construct a bi-encoder and compute the semantic similarity. However, such scalar similarity is difficult to reflect enough information and impedes our comprehension of the retrieval results. In addition, this computational process mainly emphasizes the global semantics and ignores the fine-grained semantic relationship between the query and the complex text in the document. In this paper, we propose a new method called $\textbf{Ge}$neration $\textbf{A}$ugmented $\textbf{R}$etrieval ($\textbf{GeAR}$) that incorporates well-designed fusion and decoding modules. This enables GeAR to generate the relevant text from documents based on the fused representation of the query and the document, thus learning to "focus on" the fine-grained information. Also when used as a retriever, GeAR does not add any computational burden over bi-encoders. To support the training of the new framework, we have introduced a pipeline to efficiently synthesize high-quality data by utilizing large language models. GeAR exhibits competitive retrieval and localization performance across diverse scenarios and datasets. Moreover, the qualitative analysis and the results generated by GeAR provide novel insights into the interpretation of retrieval results. The code, data, and models will be released after completing technical review to facilitate future research.
StreamAdapter: Efficient Test Time Adaptation from Contextual Streams
Nov 14, 2024



In-context learning (ICL) allows large language models (LLMs) to adapt to new tasks directly from the given demonstrations without requiring gradient updates. While recent advances have expanded context windows to accommodate more demonstrations, this approach increases inference costs without necessarily improving performance. To mitigate these issues, We propose StreamAdapter, a novel approach that directly updates model parameters from context at test time, eliminating the need for explicit in-context demonstrations. StreamAdapter employs context mapping and weight absorption mechanisms to dynamically transform ICL demonstrations into parameter updates with minimal additional parameters. By reducing reliance on numerous in-context examples, StreamAdapter significantly reduce inference costs and allows for efficient inference with constant time complexity, regardless of demonstration count. Extensive experiments across diverse tasks and model architectures demonstrate that StreamAdapter achieves comparable or superior adaptation capability to ICL while requiring significantly fewer demonstrations. The superior task adaptation and context encoding capabilities of StreamAdapter on both language understanding and generation tasks provides a new perspective for adapting LLMs at test time using context, allowing for more efficient adaptation across scenarios and more cost-effective inference
Token-level Proximal Policy Optimization for Query Generation
Nov 01, 2024Query generation is a critical task for web search engines (e.g. Google, Bing) and recommendation systems. Recently, state-of-the-art query generation methods leverage Large Language Models (LLMs) for their strong capabilities in context understanding and text generation. However, they still face challenges in generating high-quality queries in terms of inferring user intent based on their web search interaction history. In this paper, we propose Token-level Proximal Policy Optimization (TPPO), a noval approach designed to empower LLMs perform better in query generation through fine-tuning. TPPO is based on the Reinforcement Learning from AI Feedback (RLAIF) paradigm, consisting of a token-level reward model and a token-level proximal policy optimization module to address the sparse reward challenge in traditional RLAIF frameworks. To evaluate the effectiveness and robustness of TPPO, we conducted experiments on both open-source dataset and an industrial dataset that was collected from a globally-used search engine. The experimental results demonstrate that TPPO significantly improves the performance of query generation for LLMs and outperforms its existing competitors.
MTL-LoRA: Low-Rank Adaptation for Multi-Task Learning
Oct 15, 2024



Parameter-efficient fine-tuning (PEFT) has been widely employed for domain adaptation, with LoRA being one of the most prominent methods due to its simplicity and effectiveness. However, in multi-task learning (MTL) scenarios, LoRA tends to obscure the distinction between tasks by projecting sparse high-dimensional features from different tasks into the same dense low-dimensional intrinsic space. This leads to task interference and suboptimal performance for LoRA and its variants. To tackle this challenge, we propose MTL-LoRA, which retains the advantages of low-rank adaptation while significantly enhancing multi-task learning capabilities. MTL-LoRA augments LoRA by incorporating additional task-adaptive parameters that differentiate task-specific information and effectively capture shared knowledge across various tasks within low-dimensional spaces. This approach enables large language models (LLMs) pre-trained on general corpus to adapt to different target task domains with a limited number of trainable parameters. Comprehensive experimental results, including evaluations on public academic benchmarks for natural language understanding, commonsense reasoning, and image-text understanding, as well as real-world industrial text Ads relevance datasets, demonstrate that MTL-LoRA outperforms LoRA and its various variants with comparable or even fewer learnable parameters in multitask learning.
An efficient framework based on large foundation model for cervical cytopathology whole slide image screening
Jul 16, 2024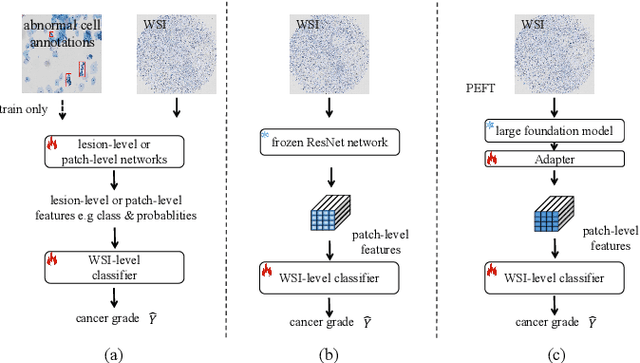
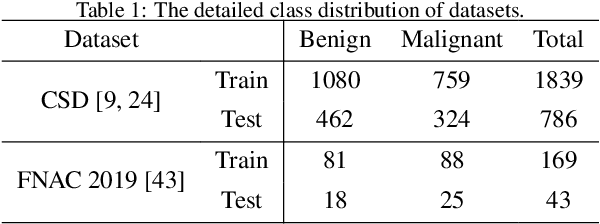
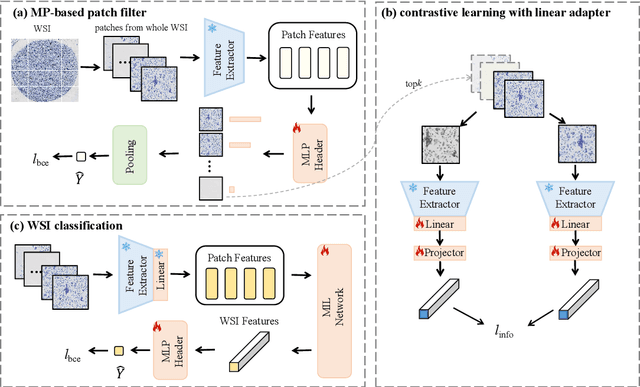
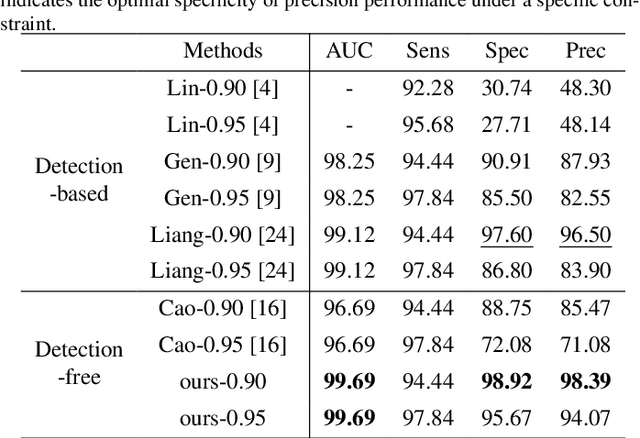
Current cervical cytopathology whole slide image (WSI) screening primarily relies on detection-based approaches, which are limited in performance due to the expense and time-consuming annotation process. Multiple Instance Learning (MIL), a weakly supervised approach that relies solely on bag-level labels, can effectively alleviate these challenges. Nonetheless, MIL commonly employs frozen pretrained models or self-supervised learning for feature extraction, which suffers from low efficacy or inefficiency. In this paper, we propose an efficient framework for cervical cytopathology WSI classification using only WSI-level labels through unsupervised and weakly supervised learning. Given the sparse and dispersed nature of abnormal cells within cytopathological WSIs, we propose a strategy that leverages the pretrained foundation model to filter the top$k$ high-risk patches. Subsequently, we suggest parameter-efficient fine-tuning (PEFT) of a large foundation model using contrastive learning on the filtered patches to enhance its representation ability for task-specific signals. By training only the added linear adapters, we enhance the learning of patch-level features with substantially reduced time and memory consumption. Experiments conducted on the CSD and FNAC 2019 datasets demonstrate that the proposed method enhances the performance of various MIL methods and achieves state-of-the-art (SOTA) performance. The code and trained models are publicly available at https://github.com/CVIU-CSU/TCT-InfoNCE.
Mobile-Bench: An Evaluation Benchmark for LLM-based Mobile Agents
Jul 01, 2024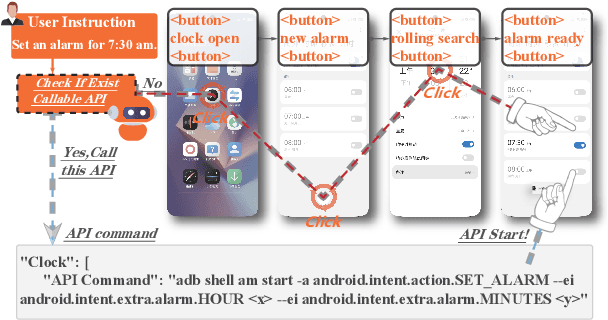


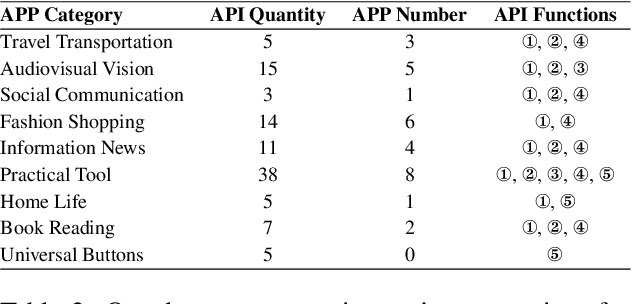
With the remarkable advancements of large language models (LLMs), LLM-based agents have become a research hotspot in human-computer interaction. However, there is a scarcity of benchmarks available for LLM-based mobile agents. Benchmarking these agents generally faces three main challenges: (1) The inefficiency of UI-only operations imposes limitations to task evaluation. (2) Specific instructions within a singular application lack adequacy for assessing the multi-dimensional reasoning and decision-making capacities of LLM mobile agents. (3) Current evaluation metrics are insufficient to accurately assess the process of sequential actions. To this end, we propose Mobile-Bench, a novel benchmark for evaluating the capabilities of LLM-based mobile agents. First, we expand conventional UI operations by incorporating 103 collected APIs to accelerate the efficiency of task completion. Subsequently, we collect evaluation data by combining real user queries with augmentation from LLMs. To better evaluate different levels of planning capabilities for mobile agents, our data is categorized into three distinct groups: SAST, SAMT, and MAMT, reflecting varying levels of task complexity. Mobile-Bench comprises 832 data entries, with more than 200 tasks specifically designed to evaluate multi-APP collaboration scenarios. Furthermore, we introduce a more accurate evaluation metric, named CheckPoint, to assess whether LLM-based mobile agents reach essential points during their planning and reasoning steps.
$Se^2$: Sequential Example Selection for In-Context Learning
Mar 06, 2024



The remarkable capability of large language models (LLMs) for in-context learning (ICL) needs to be activated by demonstration examples. Prior work has extensively explored the selection of examples for ICL, predominantly following the "select then organize" paradigm, such approaches often neglect the internal relationships between examples and exist an inconsistency between the training and inference. In this paper, we formulate the problem as a $\textit{se}$quential $\textit{se}$lection problem and introduce $Se^2$, a sequential-aware method that leverages the LLM's feedback on varying context, aiding in capturing inter-relationships and sequential information among examples, significantly enriching the contextuality and relevance of ICL prompts. Meanwhile, we utilize beam search to seek and construct example sequences, enhancing both quality and diversity. Extensive experiments across 23 NLP tasks from 8 distinct categories illustrate that $Se^2$ markedly surpasses competitive baselines and achieves 42% relative improvement over random selection. Further in-depth analysis show the effectiveness of proposed strategies, highlighting $Se^2$'s exceptional stability and adaptability across various scenarios. Our code will be released to facilitate future research.