 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePrompt: Reasoning-Augmented Reprompting for Text-to-Image Generation via Reinforcement Learning
May 23, 2025Despite recent progress in text-to-image (T2I) generation, existing models often struggle to faithfully capture user intentions from short and under-specified prompts. While prior work has attempted to enhance prompts using large language models (LLMs), these methods frequently generate stylistic or unrealistic content due to insufficient grounding in visual semantics and real-world composition. Inspired by recent advances in reasoning for language model, we propose RePrompt, a novel reprompting framework that introduces explicit reasoning into the prompt enhancement process via reinforcement learning. Instead of relying on handcrafted rules or stylistic rewrites, our method trains a language model to generate structured, self-reflective prompts by optimizing for image-level outcomes. The tailored reward models assesse the generated images in terms of human preference, semantic alignment, and visual composition, providing indirect supervision to refine prompt generation. Our approach enables end-to-end training without human-annotated data. Experiments on GenEval and T2I-Compbench show that RePrompt significantly boosts spatial layout fidelity and compositional generalization across diverse T2I backbones, establishing new state-of-the-art results.
MAIN: Mutual Alignment Is Necessary for instruction tuning
Apr 17, 2025Instruction tuning has enabled large language models (LLMs) to achieve remarkable performance, but its success heavily depends on the availability of large-scale, high-quality instruction-response pairs. However, current methods for scaling up data generation often overlook a crucial aspect: the alignment between instructions and responses. We hypothesize that high-quality instruction-response pairs are not defined by the individual quality of each component, but by the extent of their alignment with each other. To address this, we propose a Mutual Alignment Framework (MAIN) that ensures coherence between the instruction and response through mutual constraints. Experiments demonstrate that models such as LLaMA and Mistral, fine-tuned within this framework, outperform traditional methods across multiple benchmarks. This approach underscores the critical role of instruction-response alignment in enabling scalable and high-quality instruction tuning for LLMs.
GeAR: Generation Augmented Retrieval
Jan 06, 2025



Document retrieval techniques form the foundation for the development of large-scale information systems. The prevailing methodology is to construct a bi-encoder and compute the semantic similarity. However, such scalar similarity is difficult to reflect enough information and impedes our comprehension of the retrieval results. In addition, this computational process mainly emphasizes the global semantics and ignores the fine-grained semantic relationship between the query and the complex text in the document. In this paper, we propose a new method called $\textbf{Ge}$neration $\textbf{A}$ugmented $\textbf{R}$etrieval ($\textbf{GeAR}$) that incorporates well-designed fusion and decoding modules. This enables GeAR to generate the relevant text from documents based on the fused representation of the query and the document, thus learning to "focus on" the fine-grained information. Also when used as a retriever, GeAR does not add any computational burden over bi-encoders. To support the training of the new framework, we have introduced a pipeline to efficiently synthesize high-quality data by utilizing large language models. GeAR exhibits competitive retrieval and localization performance across diverse scenarios and datasets. Moreover, the qualitative analysis and the results generated by GeAR provide novel insights into the interpretation of retrieval results. The code, data, and models will be released after completing technical review to facilitate future research.
Context-DPO: Aligning Language Models for Context-Faithfulness
Dec 18, 2024



Reliable responses from large language models (LLMs) require adherence to user instructions and retrieved information. While alignment techniques help LLMs align with human intentions and values, improving context-faithfulness through alignment remains underexplored. To address this, we propose $\textbf{Context-DPO}$, the first alignment method specifically designed to enhance LLMs' context-faithfulness. We introduce $\textbf{ConFiQA}$, a benchmark that simulates Retrieval-Augmented Generation (RAG) scenarios with knowledge conflicts to evaluate context-faithfulness. By leveraging faithful and stubborn responses to questions with provided context from ConFiQA, our Context-DPO aligns LLMs through direct preference optimization. Extensive experiments demonstrate that our Context-DPO significantly improves context-faithfulness, achieving 35% to 280% improvements on popular open-source models. Further analysis demonstrates that Context-DPO preserves LLMs' generative capabilities while providing interpretable insights into context utilization. Our code and data are released at https://github.com/byronBBL/Context-DPO
StreamAdapter: Efficient Test Time Adaptation from Contextual Streams
Nov 14, 2024



In-context learning (ICL) allows large language models (LLMs) to adapt to new tasks directly from the given demonstrations without requiring gradient updates. While recent advances have expanded context windows to accommodate more demonstrations, this approach increases inference costs without necessarily improving performance. To mitigate these issues, We propose StreamAdapter, a novel approach that directly updates model parameters from context at test time, eliminating the need for explicit in-context demonstrations. StreamAdapter employs context mapping and weight absorption mechanisms to dynamically transform ICL demonstrations into parameter updates with minimal additional parameters. By reducing reliance on numerous in-context examples, StreamAdapter significantly reduce inference costs and allows for efficient inference with constant time complexity, regardless of demonstration count. Extensive experiments across diverse tasks and model architectures demonstrate that StreamAdapter achieves comparable or superior adaptation capability to ICL while requiring significantly fewer demonstrations. The superior task adaptation and context encoding capabilities of StreamAdapter on both language understanding and generation tasks provides a new perspective for adapting LLMs at test time using context, allowing for more efficient adaptation across scenarios and more cost-effective inference
Token-level Proximal Policy Optimization for Query Generation
Nov 01, 2024Query generation is a critical task for web search engines (e.g. Google, Bing) and recommendation systems. Recently, state-of-the-art query generation methods leverage Large Language Models (LLMs) for their strong capabilities in context understanding and text generation. However, they still face challenges in generating high-quality queries in terms of inferring user intent based on their web search interaction history. In this paper, we propose Token-level Proximal Policy Optimization (TPPO), a noval approach designed to empower LLMs perform better in query generation through fine-tuning. TPPO is based on the Reinforcement Learning from AI Feedback (RLAIF) paradigm, consisting of a token-level reward model and a token-level proximal policy optimization module to address the sparse reward challenge in traditional RLAIF frameworks. To evaluate the effectiveness and robustness of TPPO, we conducted experiments on both open-source dataset and an industrial dataset that was collected from a globally-used search engine. The experimental results demonstrate that TPPO significantly improves the performance of query generation for LLMs and outperforms its existing competitors.
When Graph meets Multimodal: Benchmarking on Multimodal Attributed Graphs Learning
Oct 11, 2024



Multimodal attributed graphs (MAGs) are prevalent in various real-world scenarios and generally contain two kinds of knowledge: (a) Attribute knowledge is mainly supported by the attributes of different modalities contained in nodes (entities) themselves, such as texts and images. (b) Topology knowledge, on the other hand, is provided by the complex interactions posed between nodes. The cornerstone of MAG representation learning lies in the seamless integration of multimodal attributes and topology. Recent advancements in Pre-trained Language/Vision models (PLMs/PVMs) and Graph neural networks (GNNs) have facilitated effective learning on MAGs, garnering increased research interest. However, the absence of meaningful benchmark datasets and standardized evaluation procedures for MAG representation learning has impeded progress in this field. In this paper, we propose Multimodal Attribute Graph Benchmark (MAGB)}, a comprehensive and diverse collection of challenging benchmark datasets for MAGs. The MAGB datasets are notably large in scale and encompass a wide range of domains, spanning from e-commerce networks to social networks. In addition to the brand-new datasets, we conduct extensive benchmark experiments over MAGB with various learning paradigms, ranging from GNN-based and PLM-based methods, to explore the necessity and feasibility of integrating multimodal attributes and graph topology. In a nutshell, we provide an overview of the MAG datasets, standardized evaluation procedures, and present baseline experiments. The entire MAGB project is publicly accessible at https://github.com/sktsherlock/ATG.
E5-V: Universal Embeddings with Multimodal Large Language Models
Jul 17, 2024Multimodal large language models (MLLMs) have shown promising advancements in general visual and language understanding. However, the representation of multimodal information using MLLMs remains largely unexplored. In this work, we introduce a new framework, E5-V, designed to adapt MLLMs for achieving universal multimodal embeddings. Our findings highlight the significant potential of MLLMs in representing multimodal inputs compared to previous approaches. By leveraging MLLMs with prompts, E5-V effectively bridges the modality gap between different types of inputs, demonstrating strong performance in multimodal embeddings even without fine-tuning. We propose a single modality training approach for E5-V, where the model is trained exclusively on text pairs. This method demonstrates significant improvements over traditional multimodal training on image-text pairs, while reducing training costs by approximately 95%. Additionally, this approach eliminates the need for costly multimodal training data collection. Extensive experiments across four types of tasks demonstrate the effectiveness of E5-V. As a universal multimodal model, E5-V not only achieves but often surpasses state-of-the-art performance in each task, despite being trained on a single modality.
ASI++: Towards Distributionally Balanced End-to-End Generative Retrieval
May 23, 2024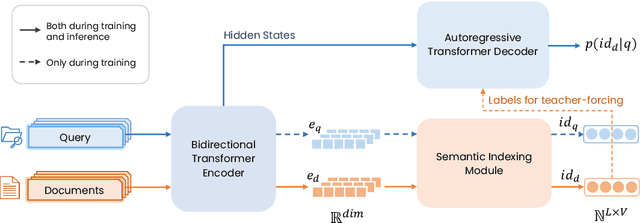



Generative retrieval, a promising new paradigm in information retrieval, employs a seq2seq model to encode document features into parameters and decode relevant document identifiers (IDs) based on search queries. Existing generative retrieval solutions typically rely on a preprocessing stage to pre-define document IDs, which can suffer from a semantic gap between these IDs and the retrieval task. However, end-to-end training for both ID assignments and retrieval tasks is challenging due to the long-tailed distribution characteristics of real-world data, resulting in inefficient and unbalanced ID space utilization. To address these issues, we propose ASI++, a novel fully end-to-end generative retrieval method that aims to simultaneously learn balanced ID assignments and improve retrieval performance. ASI++ builds on the fully end-to-end training framework of vanilla ASI and introduces several key innovations. First, a distributionally balanced criterion addresses the imbalance in ID assignments, promoting more efficient utilization of the ID space. Next, a representation bottleneck criterion enhances dense representations to alleviate bottlenecks in learning ID assignments. Finally, an information consistency criterion integrates these processes into a joint optimization framework grounded in information theory. We further explore various module structures for learning ID assignments, including neural quantization, differentiable product quantization, and residual quantization. Extensive experiments on both public and industrial datasets demonstrate the effectiveness of ASI++ in improving retrieval performance and achieving balanced ID assignments.
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
May 20, 2024



Low-rank adaptation is a popular parameter-efficient fine-tuning method for large language models. In this paper, we analyze the impact of low-rank updating, as implemented in LoRA. Our findings suggest that the low-rank updating mechanism may limit the ability of LLMs to effectively learn and memorize new knowledge. Inspired by this observation, we propose a new method called MoRA, which employs a square matrix to achieve high-rank updating while maintaining the same number of trainable parameters. To achieve it, we introduce the corresponding non-parameter operators to reduce the input dimension and increase the output dimension for the square matrix. Furthermore, these operators ensure that the weight can be merged back into LLMs, which makes our method can be deployed like LoRA. We perform a comprehensive evaluation of our method across five tasks: instruction tuning, mathematical reasoning, continual pretraining, memory and pretraining. Our method outperforms LoRA on memory-intensive tasks and achieves comparable performance on other tasks.