 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Graph meets Multimodal: Benchmarking on Multimodal Attributed Graphs Learning
Oct 11, 2024



Multimodal attributed graphs (MAGs) are prevalent in various real-world scenarios and generally contain two kinds of knowledge: (a) Attribute knowledge is mainly supported by the attributes of different modalities contained in nodes (entities) themselves, such as texts and images. (b) Topology knowledge, on the other hand, is provided by the complex interactions posed between nodes. The cornerstone of MAG representation learning lies in the seamless integration of multimodal attributes and topology. Recent advancements in Pre-trained Language/Vision models (PLMs/PVMs) and Graph neural networks (GNNs) have facilitated effective learning on MAGs, garnering increased research interest. However, the absence of meaningful benchmark datasets and standardized evaluation procedures for MAG representation learning has impeded progress in this field. In this paper, we propose Multimodal Attribute Graph Benchmark (MAGB)}, a comprehensive and diverse collection of challenging benchmark datasets for MAGs. The MAGB datasets are notably large in scale and encompass a wide range of domains, spanning from e-commerce networks to social networks. In addition to the brand-new datasets, we conduct extensive benchmark experiments over MAGB with various learning paradigms, ranging from GNN-based and PLM-based methods, to explore the necessity and feasibility of integrating multimodal attributes and graph topology. In a nutshell, we provide an overview of the MAG datasets, standardized evaluation procedures, and present baseline experiments. The entire MAGB project is publicly accessible at https://github.com/sktsherlock/ATG.
Unleash LLMs Potential for Recommendation by Coordinating Twin-Tower Dynamic Semantic Token Generator
Sep 14, 2024Owing to the unprecedented capability in semantic understanding and logical reasoning, the pre-trained large language models (LLMs) have shown fantastic potential in developing the next-generation recommender systems (RSs). However, the static index paradigm adopted by current methods greatly restricts the utilization of LLMs capacity for recommendation, leading to not only the insufficient alignment between semantic and collaborative knowledge, but also the neglect of high-order user-item interaction patterns. In this paper, we propose Twin-Tower Dynamic Semantic Recommender (TTDS), the first generative RS which adopts dynamic semantic index paradigm, targeting at resolving the above problems simultaneously. To be more specific, we for the first time contrive a dynamic knowledge fusion framework which integrates a twin-tower semantic token generator into the LLM-based recommender, hierarchically allocating meaningful semantic index for items and users, and accordingly predicting the semantic index of target item. Furthermore, a dual-modality variational auto-encoder is proposed to facilitate multi-grained alignment between semantic and collaborative knowledge. Eventually, a series of novel tuning tasks specially customized for capturing high-order user-item interaction patterns are proposed to take advantages of user historical behavior. Extensive experiments across three public datasets demonstrate the superiority of the proposed methodology in developing LLM-based generative RSs. The proposed TTDS recommender achieves an average improvement of 19.41% in Hit-Rate and 20.84% in NDCG metric, compared with the leading baseline methods.
Hybrid Multimodal Fusion for Humor Detection
Sep 24, 2022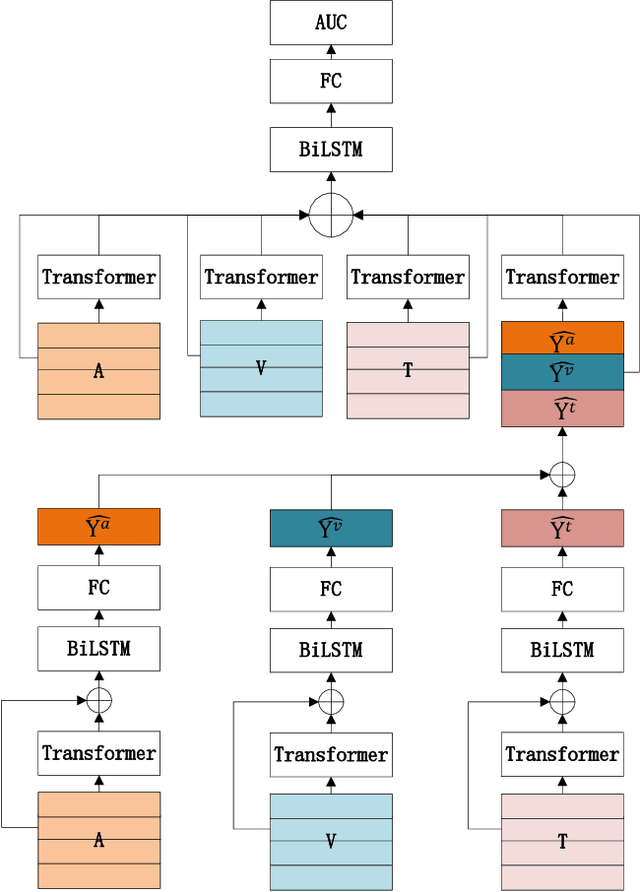



In this paper, we present our solution to the MuSe-Humor sub-challenge of the Multimodal Emotional Challenge (MuSe) 2022. The goal of the MuSe-Humor sub-challenge is to detect humor and calculate AUC from audiovisual recordings of German football Bundesliga press conferences. It is annotated for humor displayed by the coaches. For this sub-challenge, we first build a discriminant model using the transformer module and BiLSTM module, and then propose a hybrid fusion strategy to use the prediction results of each modality to improve the performance of the model. Our experiments demonstrate the effectiveness of our proposed model and hybrid fusion strategy on multimodal fusion, and the AUC of our proposed model on the test set is 0.8972.
An Adaptive Graph Pre-training Framework for Localized Collaborative Filtering
Dec 14, 2021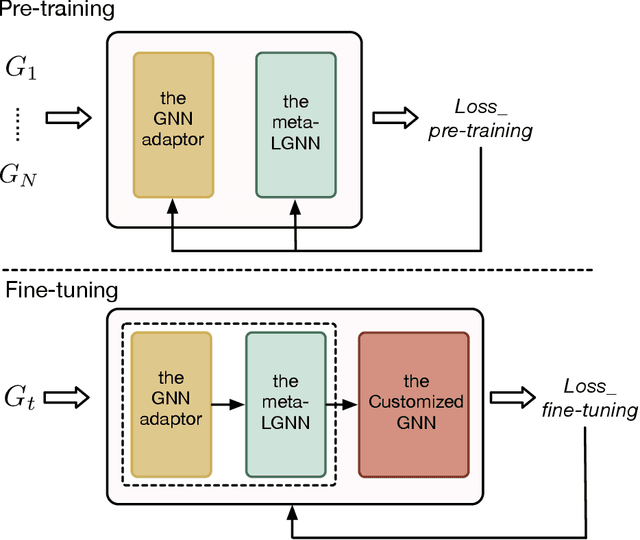


Graph neural networks (GNNs) have been widely applied in the recommendation tasks and have obtained very appealing performance. However, most GNN-based recommendation methods suffer from the problem of data sparsity in practice. Meanwhile, pre-training techniques have achieved great success in mitigating data sparsity in various domains such as natural language processing (NLP) and computer vision (CV). Thus, graph pre-training has the great potential to alleviate data sparsity in GNN-based recommendations. However, pre-training GNNs for recommendations face unique challenges. For example, user-item interaction graphs in different recommendation tasks have distinct sets of users and items, and they often present different properties. Therefore, the successful mechanisms commonly used in NLP and CV to transfer knowledge from pre-training tasks to downstream tasks such as sharing learned embeddings or feature extractors are not directly applicable to existing GNN-based recommendations models. To tackle these challenges, we delicately design an adaptive graph pre-training framework for localized collaborative filtering (ADAPT). It does not require transferring user/item embeddings, and is able to capture both the common knowledge across different graphs and the uniqueness for each graph. Extensive experimental results have demonstrated the effectiveness and superiority of ADAPT.
Localized Graph Collaborative Filtering
Aug 10, 2021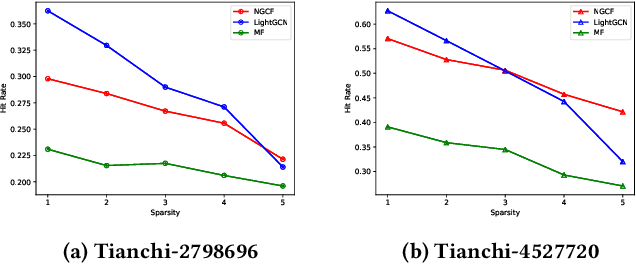
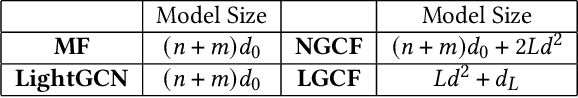
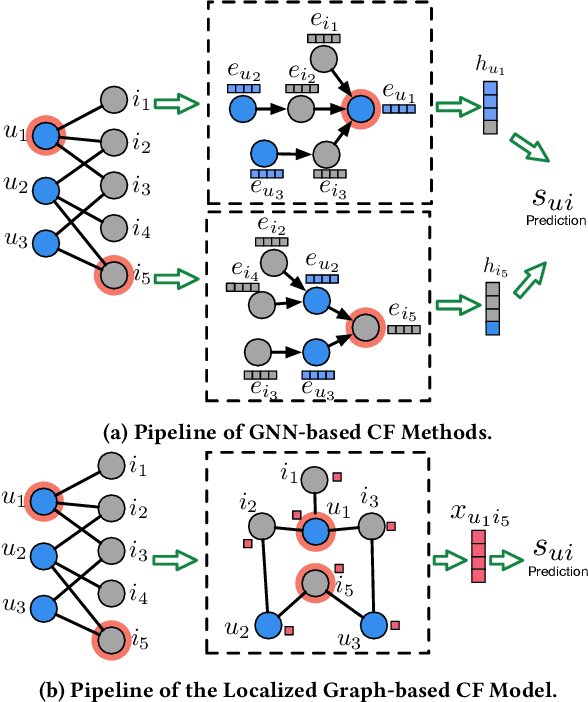
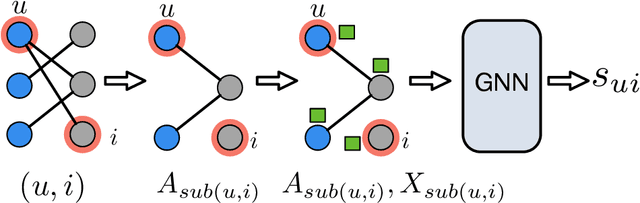
User-item interactions in recommendations can be naturally de-noted as a user-item bipartite graph. Given the success of graph neural networks (GNNs) in graph representation learning, GNN-based C methods have been proposed to advance recommender systems. These methods often make recommendations based on the learned user and item embeddings. However, we found that they do not perform well wit sparse user-item graphs which are quite common in real-world recommendations. Therefore, in this work, we introduce a novel perspective to build GNN-based CF methods for recommendations which leads to the proposed framework Localized Graph Collaborative Filtering (LGCF). One key advantage of LGCF is that it does not need to learn embeddings for each user and item, which is challenging in sparse scenarios. Alternatively, LGCF aims at encoding useful CF information into a localized graph and making recommendations based on such graph. Extensive experiments on various datasets validate the effectiveness of LGCF especially in sparse scenarios. Furthermore, empirical results demonstrate that LGCF provides complementary information to the embedding-based CF model which can be utilized to boost recommendation performance.