 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCellMamba: Adaptive Mamba for Accurate and Efficient Cell Detection
Dec 25, 2025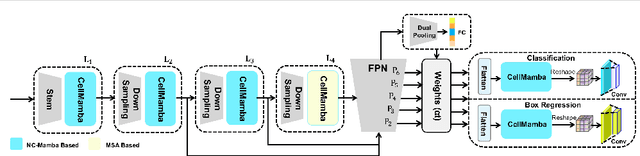
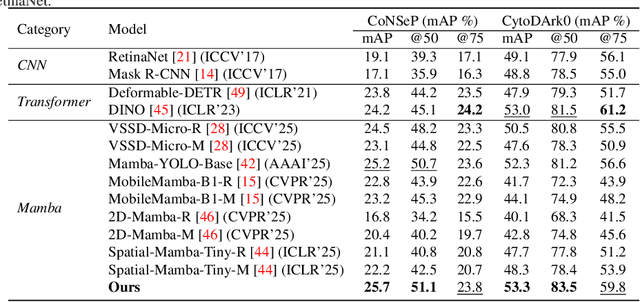
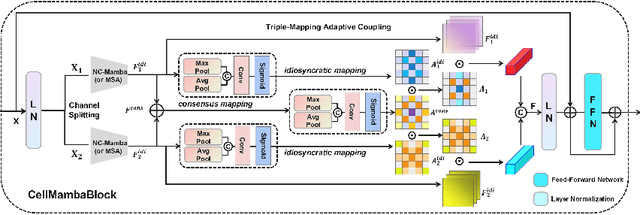
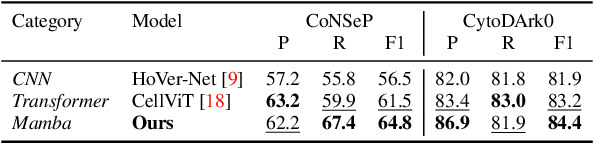
Cell detection in pathological images presents unique challenges due to densely packed objects, subtle inter-class differences, and severe background clutter. In this paper, we propose CellMamba, a lightweight and accurate one-stage detector tailored for fine-grained biomedical instance detection. Built upon a VSSD backbone, CellMamba integrates CellMamba Blocks, which couple either NC-Mamba or Multi-Head Self-Attention (MSA) with a novel Triple-Mapping Adaptive Coupling (TMAC) module. TMAC enhances spatial discriminability by splitting channels into two parallel branches, equipped with dual idiosyncratic and one consensus attention map, adaptively fused to preserve local sensitivity and global consistency. Furthermore, we design an Adaptive Mamba Head that fuses multi-scale features via learnable weights for robust detection under varying object sizes. Extensive experiments on two public datasets-CoNSeP and CytoDArk0-demonstrate that CellMamba outperforms both CNN-based, Transformer-based, and Mamba-based baselines in accuracy, while significantly reducing model size and inference latency. Our results validate CellMamba as an efficient and effective solution for high-resolution cell detection.
Advancing Cross-Organ Domain Generalization with Test-Time Style Transfer and Diversity Enhancement
Mar 24, 2025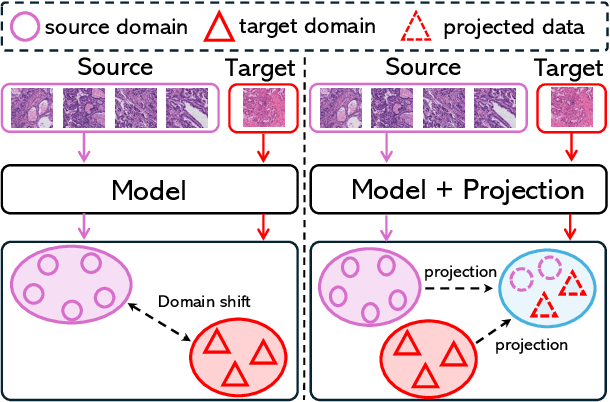



Deep learning has made significant progress in addressing challenges in various fields including computational pathology (CPath). However, due to the complexity of the domain shift problem, the performance of existing models will degrade, especially when it comes to multi-domain or cross-domain tasks. In this paper, we propose a Test-time style transfer (T3s) that uses a bidirectional mapping mechanism to project the features of the source and target domains into a unified feature space, enhancing the generalization ability of the model. To further increase the style expression space, we introduce a Cross-domain style diversification module (CSDM) to ensure the orthogonality between style bases. In addition, data augmentation and low-rank adaptation techniques are used to improve feature alignment and sensitivity, enabling the model to adapt to multi-domain inputs effectively. Our method has demonstrated effectiveness on three unseen datasets.
Tuning LLMs by RAG Principles: Towards LLM-native Memory
Mar 20, 2025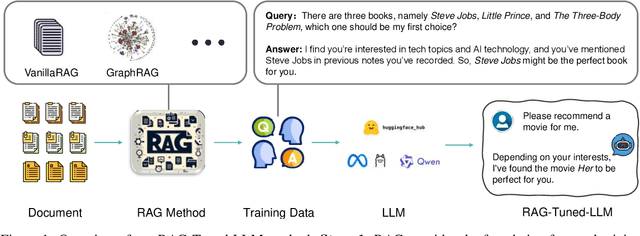
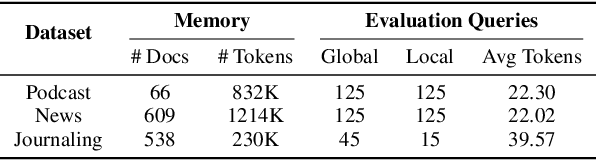
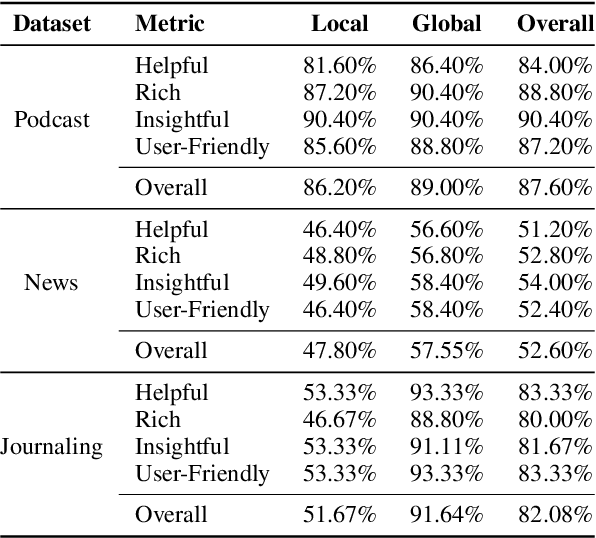
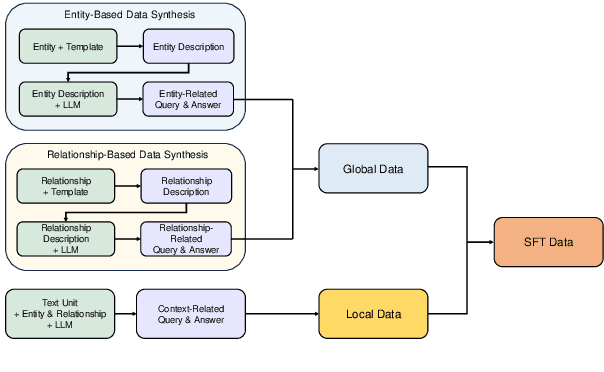
Memory, additional information beyond the training of large language models (LLMs), is crucial to various real-world applications, such as personal assistant. The two mainstream solutions to incorporate memory into the generation process are long-context LLMs and retrieval-augmented generation (RAG). In this paper, we first systematically compare these two types of solutions on three renovated/new datasets and show that (1) long-context solutions, although more expensive, shall be easier to capture the big picture and better answer queries which require considering the memory as a whole; and (2) when the queries concern specific information, RAG solutions shall be more competitive especially when the keywords can be explicitly matched. Therefore, we propose a novel method RAG-Tuned-LLM which fine-tunes a relative small (e.g., 7B) LLM using the data generated following the RAG principles, so it can combine the advantages of both solutions. Extensive experiments on three datasets demonstrate that RAG-Tuned-LLM can beat long-context LLMs and RAG methods across a wide range of query types.
FilterLLM: Text-To-Distribution LLM for Billion-Scale Cold-Start Recommendation
Feb 24, 2025Large Language Model (LLM)-based cold-start recommendation systems continue to face significant computational challenges in billion-scale scenarios, as they follow a "Text-to-Judgment" paradigm. This approach processes user-item content pairs as input and evaluates each pair iteratively. To maintain efficiency, existing methods rely on pre-filtering a small candidate pool of user-item pairs. However, this severely limits the inferential capabilities of LLMs by reducing their scope to only a few hundred pre-filtered candidates. To overcome this limitation, we propose a novel "Text-to-Distribution" paradigm, which predicts an item's interaction probability distribution for the entire user set in a single inference. Specifically, we present FilterLLM, a framework that extends the next-word prediction capabilities of LLMs to billion-scale filtering tasks. FilterLLM first introduces a tailored distribution prediction and cold-start framework. Next, FilterLLM incorporates an efficient user-vocabulary structure to train and store the embeddings of billion-scale users. Finally, we detail the training objectives for both distribution prediction and user-vocabulary construction. The proposed framework has been deployed on the Alibaba platform, where it has been serving cold-start recommendations for two months, processing over one billion cold items. Extensive experiments demonstrate that FilterLLM significantly outperforms state-of-the-art methods in cold-start recommendation tasks, achieving over 30 times higher efficiency. Furthermore, an online A/B test validates its effectiveness in billion-scale recommendation systems.
When Graph meets Multimodal: Benchmarking on Multimodal Attributed Graphs Learning
Oct 11, 2024



Multimodal attributed graphs (MAGs) are prevalent in various real-world scenarios and generally contain two kinds of knowledge: (a) Attribute knowledge is mainly supported by the attributes of different modalities contained in nodes (entities) themselves, such as texts and images. (b) Topology knowledge, on the other hand, is provided by the complex interactions posed between nodes. The cornerstone of MAG representation learning lies in the seamless integration of multimodal attributes and topology. Recent advancements in Pre-trained Language/Vision models (PLMs/PVMs) and Graph neural networks (GNNs) have facilitated effective learning on MAGs, garnering increased research interest. However, the absence of meaningful benchmark datasets and standardized evaluation procedures for MAG representation learning has impeded progress in this field. In this paper, we propose Multimodal Attribute Graph Benchmark (MAGB)}, a comprehensive and diverse collection of challenging benchmark datasets for MAGs. The MAGB datasets are notably large in scale and encompass a wide range of domains, spanning from e-commerce networks to social networks. In addition to the brand-new datasets, we conduct extensive benchmark experiments over MAGB with various learning paradigms, ranging from GNN-based and PLM-based methods, to explore the necessity and feasibility of integrating multimodal attributes and graph topology. In a nutshell, we provide an overview of the MAG datasets, standardized evaluation procedures, and present baseline experiments. The entire MAGB project is publicly accessible at https://github.com/sktsherlock/ATG.
Training Interactive Agent in Large FPS Game Map with Rule-enhanced Reinforcement Learning
Oct 07, 2024In the realm of competitive gaming, 3D first-person shooter (FPS) games have gained immense popularity, prompting the development of game AI systems to enhance gameplay. However, deploying game AI in practical scenarios still poses challenges, particularly in large-scale and complex FPS games. In this paper, we focus on the practical deployment of game AI in the online multiplayer competitive 3D FPS game called Arena Breakout, developed by Tencent Games. We propose a novel gaming AI system named Private Military Company Agent (PMCA), which is interactable within a large game map and engages in combat with players while utilizing tactical advantages provided by the surrounding terrain. To address the challenges of navigation and combat in modern 3D FPS games, we introduce a method that combines navigation mesh (Navmesh) and shooting-rule with deep reinforcement learning (NSRL). The integration of Navmesh enhances the agent's global navigation capabilities while shooting behavior is controlled using rule-based methods to ensure controllability. NSRL employs a DRL model to predict when to enable the navigation mesh, resulting in a diverse range of behaviors for the game AI. Customized rewards for human-like behaviors are also employed to align PMCA's behavior with that of human players.
Breaking the mold: The challenge of large scale MARL specialization
Oct 03, 2024In multi-agent learning, the predominant approach focuses on generalization, often neglecting the optimization of individual agents. This emphasis on generalization limits the ability of agents to utilize their unique strengths, resulting in inefficiencies. This paper introduces Comparative Advantage Maximization (CAM), a method designed to enhance individual agent specialization in multiagent systems. CAM employs a two-phase process, combining centralized population training with individual specialization through comparative advantage maximization. CAM achieved a 13.2% improvement in individual agent performance and a 14.9% increase in behavioral diversity compared to state-of-the-art systems. The success of CAM highlights the importance of individual agent specialization, suggesting new directions for multi-agent system development.
Unleash LLMs Potential for Recommendation by Coordinating Twin-Tower Dynamic Semantic Token Generator
Sep 14, 2024Owing to the unprecedented capability in semantic understanding and logical reasoning, the pre-trained large language models (LLMs) have shown fantastic potential in developing the next-generation recommender systems (RSs). However, the static index paradigm adopted by current methods greatly restricts the utilization of LLMs capacity for recommendation, leading to not only the insufficient alignment between semantic and collaborative knowledge, but also the neglect of high-order user-item interaction patterns. In this paper, we propose Twin-Tower Dynamic Semantic Recommender (TTDS), the first generative RS which adopts dynamic semantic index paradigm, targeting at resolving the above problems simultaneously. To be more specific, we for the first time contrive a dynamic knowledge fusion framework which integrates a twin-tower semantic token generator into the LLM-based recommender, hierarchically allocating meaningful semantic index for items and users, and accordingly predicting the semantic index of target item. Furthermore, a dual-modality variational auto-encoder is proposed to facilitate multi-grained alignment between semantic and collaborative knowledge. Eventually, a series of novel tuning tasks specially customized for capturing high-order user-item interaction patterns are proposed to take advantages of user historical behavior. Extensive experiments across three public datasets demonstrate the superiority of the proposed methodology in developing LLM-based generative RSs. The proposed TTDS recommender achieves an average improvement of 19.41% in Hit-Rate and 20.84% in NDCG metric, compared with the leading baseline methods.
Style-Aware Radiology Report Generation with RadGraph and Few-Shot Prompting
Oct 31, 2023



Automatically generated reports from medical images promise to improve the workflow of radiologists. Existing methods consider an image-to-report modeling task by directly generating a fully-fledged report from an image. However, this conflates the content of the report (e.g., findings and their attributes) with its style (e.g., format and choice of words), which can lead to clinically inaccurate reports. To address this, we propose a two-step approach for radiology report generation. First, we extract the content from an image; then, we verbalize the extracted content into a report that matches the style of a specific radiologist. For this, we leverage RadGraph -- a graph representation of reports -- together with large language models (LLMs). In our quantitative evaluations, we find that our approach leads to beneficial performance. Our human evaluation with clinical raters highlights that the AI-generated reports are indistinguishably tailored to the style of individual radiologist despite leveraging only a few examples as context.
sasdim: self-adaptive noise scaling diffusion model for spatial time series imputation
Sep 05, 2023



Spatial time series imputation is critically important to many real applications such as intelligent transportation and air quality monitoring. Although recent transformer and diffusion model based approaches have achieved significant performance gains compared with conventional statistic based methods, spatial time series imputation still remains as a challenging issue due to the complex spatio-temporal dependencies and the noise uncertainty of the spatial time series data. Especially, recent diffusion process based models may introduce random noise to the imputations, and thus cause negative impact on the model performance. To this end, we propose a self-adaptive noise scaling diffusion model named SaSDim to more effectively perform spatial time series imputation. Specially, we propose a new loss function that can scale the noise to the similar intensity, and propose the across spatial-temporal global convolution module to more effectively capture the dynamic spatial-temporal dependencies. Extensive experiments conducted on three real world datasets verify the effectiveness of SaSDim by comparison with current state-of-the-art baselines.