 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning LLMs by RAG Principles: Towards LLM-native Memory
Paper and Code
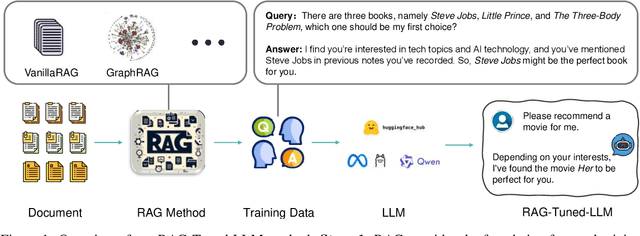
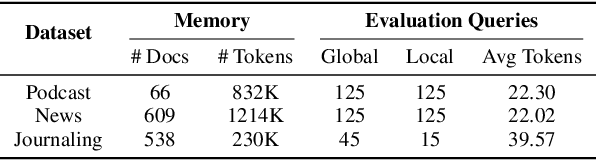
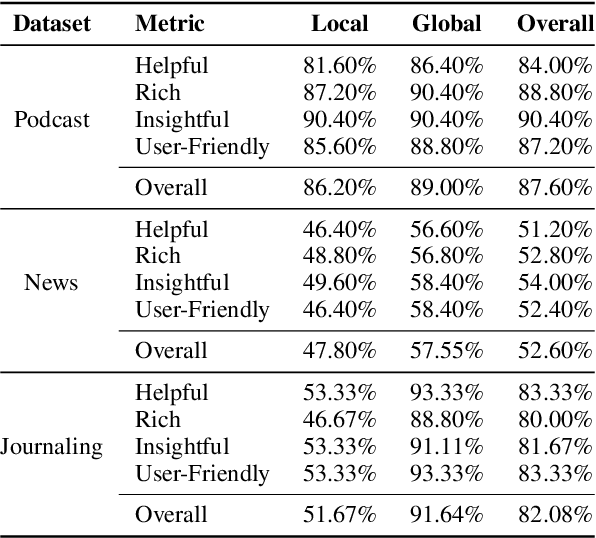
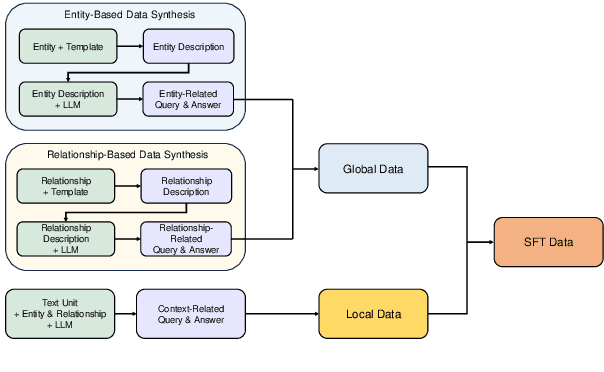
Memory, additional information beyond the training of large language models (LLMs), is crucial to various real-world applications, such as personal assistant. The two mainstream solutions to incorporate memory into the generation process are long-context LLMs and retrieval-augmented generation (RAG). In this paper, we first systematically compare these two types of solutions on three renovated/new datasets and show that (1) long-context solutions, although more expensive, shall be easier to capture the big picture and better answer queries which require considering the memory as a whole; and (2) when the queries concern specific information, RAG solutions shall be more competitive especially when the keywords can be explicitly matched. Therefore, we propose a novel method RAG-Tuned-LLM which fine-tunes a relative small (e.g., 7B) LLM using the data generated following the RAG principles, so it can combine the advantages of both solutions. Extensive experiments on three datasets demonstrate that RAG-Tuned-LLM can beat long-context LLMs and RAG methods across a wide range of query types.