 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning LLMs by RAG Principles: Towards LLM-native Memory
Mar 20, 2025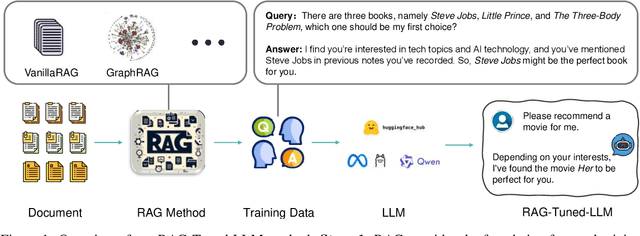
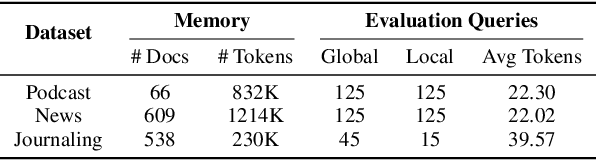
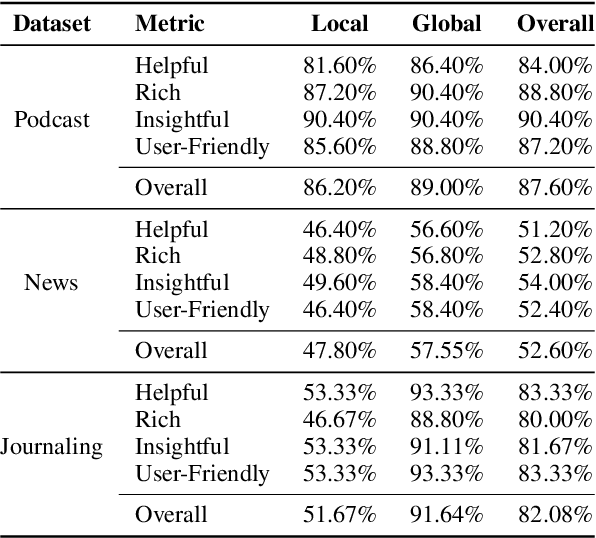
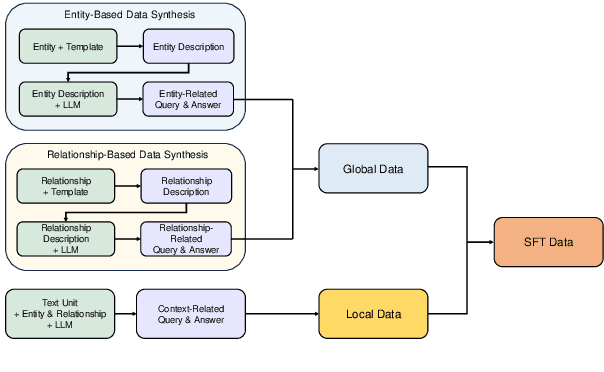
Memory, additional information beyond the training of large language models (LLMs), is crucial to various real-world applications, such as personal assistant. The two mainstream solutions to incorporate memory into the generation process are long-context LLMs and retrieval-augmented generation (RAG). In this paper, we first systematically compare these two types of solutions on three renovated/new datasets and show that (1) long-context solutions, although more expensive, shall be easier to capture the big picture and better answer queries which require considering the memory as a whole; and (2) when the queries concern specific information, RAG solutions shall be more competitive especially when the keywords can be explicitly matched. Therefore, we propose a novel method RAG-Tuned-LLM which fine-tunes a relative small (e.g., 7B) LLM using the data generated following the RAG principles, so it can combine the advantages of both solutions. Extensive experiments on three datasets demonstrate that RAG-Tuned-LLM can beat long-context LLMs and RAG methods across a wide range of query types.
Waveformer: Linear-Time Attention with Forward and Backward Wavelet Transform
Oct 05, 2022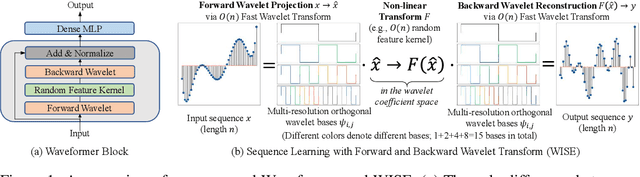
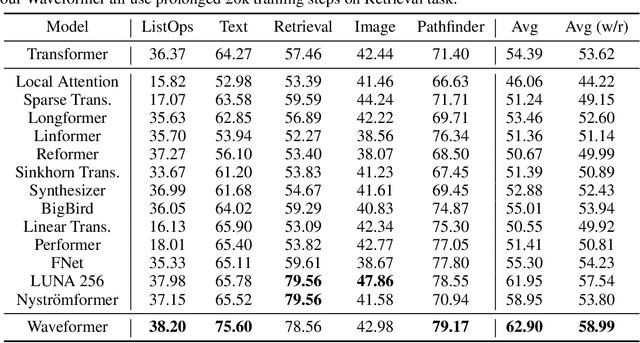

We propose Waveformer that learns attention mechanism in the wavelet coefficient space, requires only linear time complexity, and enjoys universal approximating power. Specifically, we first apply forward wavelet transform to project the input sequences to multi-resolution orthogonal wavelet bases, then conduct nonlinear transformations (in this case, a random feature kernel) in the wavelet coefficient space, and finally reconstruct the representation in input space via backward wavelet transform. We note that other non-linear transformations may be used, hence we name the learning paradigm Wavelet transformatIon for Sequence lEarning (WISE). We emphasize the importance of backward reconstruction in the WISE paradigm -- without it, one would be mixing information from both the input space and coefficient space through skip connections, which shall not be considered as mathematically sound. Compared with Fourier transform in recent works, wavelet transform is more efficient in time complexity and better captures local and positional information; we further support this through our ablation studies. Extensive experiments on seven long-range understanding datasets from the Long Range Arena benchmark and code understanding tasks demonstrate that (1) Waveformer achieves competitive and even better accuracy than a number of state-of-the-art Transformer variants and (2) WISE can boost accuracies of various attention approximation methods without increasing the time complexity. These together showcase the superiority of learning attention in a wavelet coefficient space over the input space.
The Spike Gating Flow: A Hierarchical Structure Based Spiking Neural Network for Online Gesture Recognition
Jun 07, 2022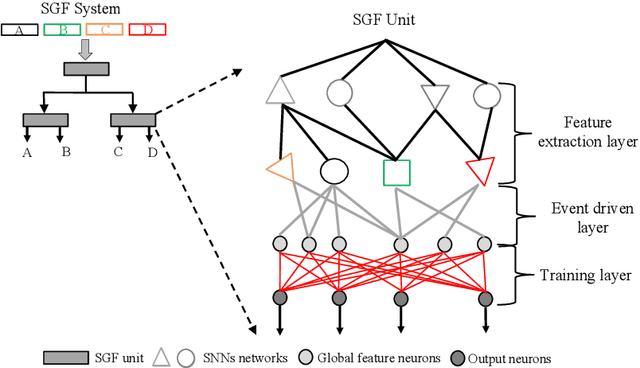
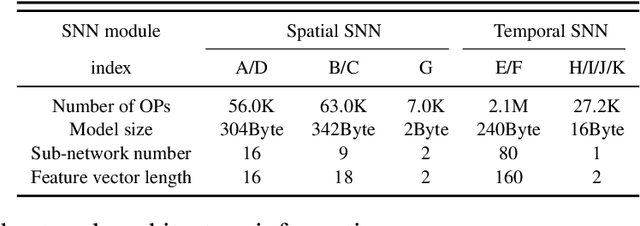
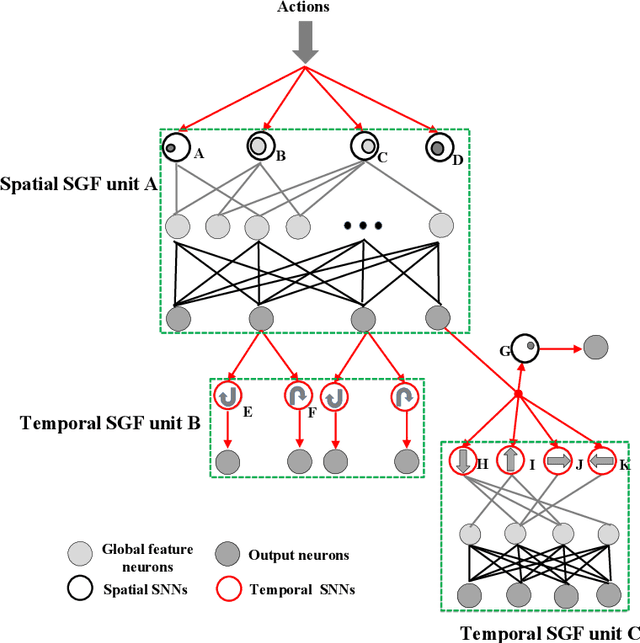
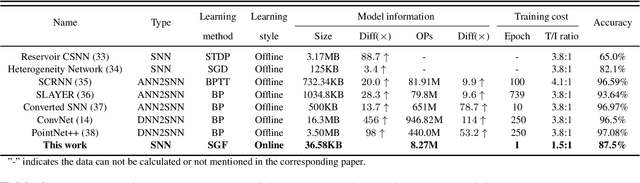
Action recognition is an exciting research avenue for artificial intelligence since it may be a game changer in the emerging industrial fields such as robotic visions and automobiles. However, current deep learning faces major challenges for such applications because of the huge computational cost and the inefficient learning. Hence, we develop a novel brain-inspired Spiking Neural Network (SNN) based system titled Spiking Gating Flow (SGF) for online action learning. The developed system consists of multiple SGF units which assembled in a hierarchical manner. A single SGF unit involves three layers: a feature extraction layer, an event-driven layer and a histogram-based training layer. To demonstrate the developed system capabilities, we employ a standard Dynamic Vision Sensor (DVS) gesture classification as a benchmark. The results indicate that we can achieve 87.5% accuracy which is comparable with Deep Learning (DL), but at smaller training/inference data number ratio 1.5:1. And only a single training epoch is required during the learning process. Meanwhile, to the best of our knowledge, this is the highest accuracy among the non-backpropagation algorithm based SNNs. At last, we conclude the few-shot learning paradigm of the developed network: 1) a hierarchical structure-based network design involves human prior knowledge; 2) SNNs for content based global dynamic feature detection.
Augmenting Anchors by the Detector Itself
May 28, 2021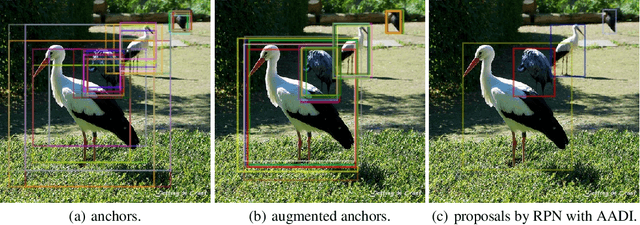
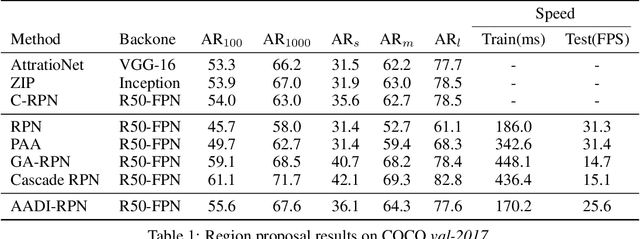
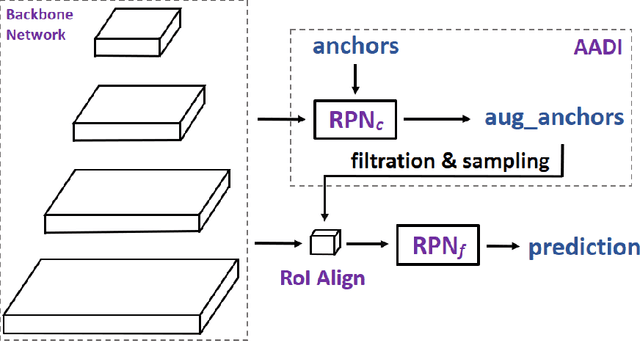

It is difficult to determine the scale and aspect ratio of anchors for anchor-based object detection methods. Current state-of-the-art object detectors either determine anchor parameters according to objects' shape and scale in a dataset, or avoid this problem by utilizing anchor-free method. In this paper, we propose a gradient-free anchor augmentation method named AADI, which means Augmenting Anchors by the Detector Itself. AADI is not an anchor-free method, but it converts the scale and aspect ratio of anchors from a continuous space to a discrete space, which greatly alleviates the problem of anchors' designation. Furthermore, AADI does not add any parameters or hyper-parameters, which is beneficial for future research and downstream tasks. Extensive experiments on COCO dataset show that AADI has obvious advantages for both two-stage and single-stage methods, specifically, AADI achieves at least 2.1 AP improvements on Faster R-CNN and 1.6 AP improvements on RetinaNet, using ResNet-50 model. We hope that this simple and cost-efficient method can be widely used in object detection.
Augmenting Proposals by the Detector Itself
Jan 28, 2021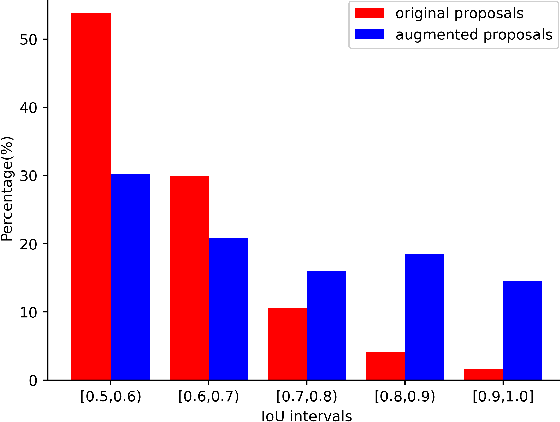
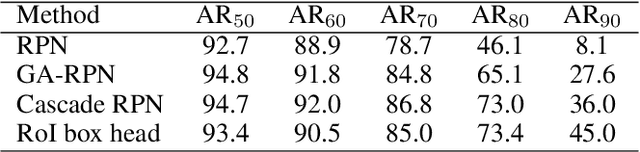
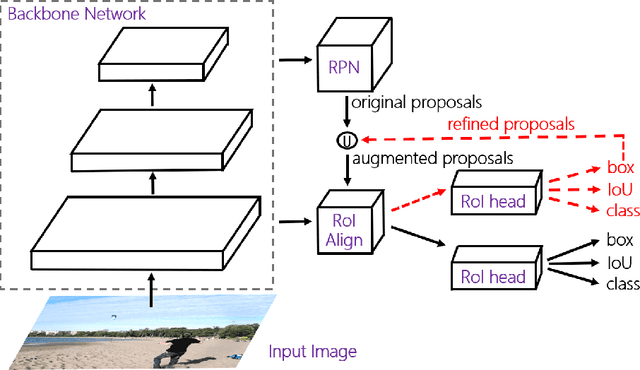
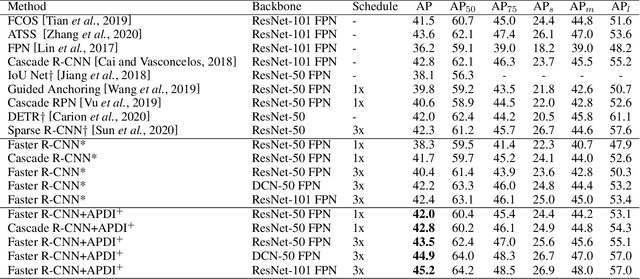
Lacking enough high quality proposals for RoI box head has impeded two-stage and multi-stage object detectors for a long time, and many previous works try to solve it via improving RPN's performance or manually generating proposals from ground truth. However, these methods either need huge training and inference costs or bring little improvements. In this paper, we design a novel training method named APDI, which means augmenting proposals by the detector itself and can generate proposals with higher quality. Furthermore, APDI makes it possible to integrate IoU head into RoI box head. And it does not add any hyperparameter, which is beneficial for future research and downstream tasks. Extensive experiments on COCO dataset show that our method brings at least 2.7 AP improvements on Faster R-CNN with various backbones, and APDI can cooperate with advanced RPNs, such as GA-RPN and Cascade RPN, to obtain extra gains. Furthermore, it brings significant improvements on Cascade R-CNN.