 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Recursive Thinking: Self-Improvement without External Feedback
Feb 03, 2026Modern Large Language Models (LLMs) have shown rapid improvements in reasoning capabilities, driven largely by reinforcement learning (RL) with verifiable rewards. Here, we ask whether these LLMs can self-improve without the need for additional training. We identify two core challenges for such systems: (i) efficiently generating diverse, high-quality candidate solutions, and (ii) reliably selecting correct answers in the absence of ground-truth supervision. To address these challenges, we propose Test-time Recursive Thinking (TRT), an iterative self-improvement framework that conditions generation on rollout-specific strategies, accumulated knowledge, and self-generated verification signals. Using TRT, open-source models reach 100% accuracy on AIME-25/24, and on LiveCodeBench's most difficult problems, closed-source models improve by 10.4-14.8 percentage points without external feedback.
Mon3tr: Monocular 3D Telepresence with Pre-built Gaussian Avatars as Amortization
Jan 12, 2026Immersive telepresence aims to transform human interaction in AR/VR applications by enabling lifelike full-body holographic representations for enhanced remote collaboration. However, existing systems rely on hardware-intensive multi-camera setups and demand high bandwidth for volumetric streaming, limiting their real-time performance on mobile devices. To overcome these challenges, we propose Mon3tr, a novel Monocular 3D telepresence framework that integrates 3D Gaussian splatting (3DGS) based parametric human modeling into telepresence for the first time. Mon3tr adopts an amortized computation strategy, dividing the process into a one-time offline multi-view reconstruction phase to build a user-specific avatar and a monocular online inference phase during live telepresence sessions. A single monocular RGB camera is used to capture body motions and facial expressions in real time to drive the 3DGS-based parametric human model, significantly reducing system complexity and cost. The extracted motion and appearance features are transmitted at < 0.2 Mbps over WebRTC's data channel, allowing robust adaptation to network fluctuations. On the receiver side, e.g., Meta Quest 3, we develop a lightweight 3DGS attribute deformation network to dynamically generate corrective 3DGS attribute adjustments on the pre-built avatar, synthesizing photorealistic motion and appearance at ~ 60 FPS. Extensive experiments demonstrate the state-of-the-art performance of our method, achieving a PSNR of > 28 dB for novel poses, an end-to-end latency of ~ 80 ms, and > 1000x bandwidth reduction compared to point-cloud streaming, while supporting real-time operation from monocular inputs across diverse scenarios. Our demos can be found at https://mon3tr3d.github.io.
Text Generation Beyond Discrete Token Sampling
May 20, 2025
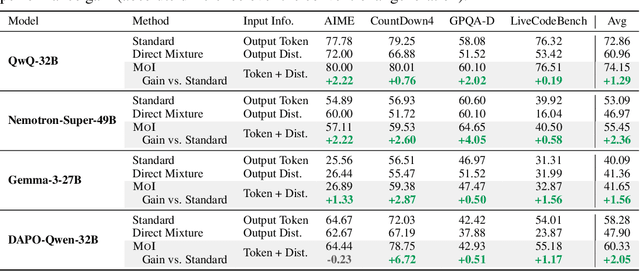


In standard autoregressive generation, an LLM predicts the next-token distribution, samples a discrete token, and then discards the distribution, passing only the sampled token as new input. To preserve this distribution's rich information, we propose Mixture of Inputs (MoI), a training-free method for autoregressive generation. After generating a token following the standard paradigm, we construct a new input that blends the generated discrete token with the previously discarded token distribution. Specifically, we employ a Bayesian estimation method that treats the token distribution as the prior, the sampled token as the observation, and replaces the conventional one-hot vector with the continuous posterior expectation as the new model input. MoI allows the model to maintain a richer internal representation throughout the generation process, resulting in improved text quality and reasoning capabilities. On mathematical reasoning, code generation, and PhD-level QA tasks, MoI consistently improves performance across multiple models including QwQ-32B, Nemotron-Super-49B, Gemma-3-27B, and DAPO-Qwen-32B, with no additional training and negligible computational overhead.
Self-Taught Agentic Long Context Understanding
Feb 21, 2025Answering complex, long-context questions remains a major challenge for large language models (LLMs) as it requires effective question clarifications and context retrieval. We propose Agentic Long-Context Understanding (AgenticLU), a framework designed to enhance an LLM's understanding of such queries by integrating targeted self-clarification with contextual grounding within an agentic workflow. At the core of AgenticLU is Chain-of-Clarifications (CoC), where models refine their understanding through self-generated clarification questions and corresponding contextual groundings. By scaling inference as a tree search where each node represents a CoC step, we achieve 97.8% answer recall on NarrativeQA with a search depth of up to three and a branching factor of eight. To amortize the high cost of this search process to training, we leverage the preference pairs for each step obtained by the CoC workflow and perform two-stage model finetuning: (1) supervised finetuning to learn effective decomposition strategies, and (2) direct preference optimization to enhance reasoning quality. This enables AgenticLU models to generate clarifications and retrieve relevant context effectively and efficiently in a single inference pass. Extensive experiments across seven long-context tasks demonstrate that AgenticLU significantly outperforms state-of-the-art prompting methods and specialized long-context LLMs, achieving robust multi-hop reasoning while sustaining consistent performance as context length grows.
Vector-ICL: In-context Learning with Continuous Vector Representations
Oct 08, 2024
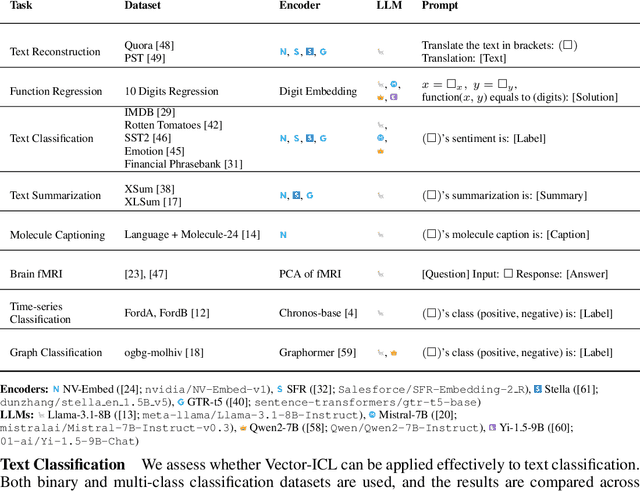
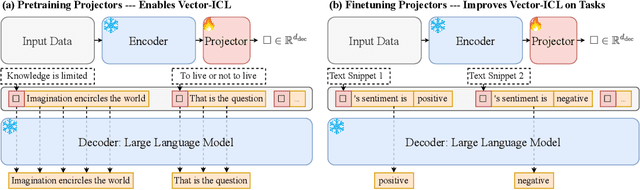
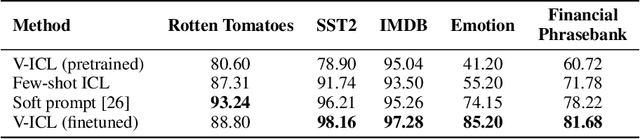
Large language models (LLMs) have shown remarkable in-context learning (ICL) capabilities on textual data. We explore whether these capabilities can be extended to continuous vectors from diverse domains, obtained from black-box pretrained encoders. By aligning input data with an LLM's embedding space through lightweight projectors, we observe that LLMs can effectively process and learn from these projected vectors, which we term Vector-ICL. In particular, we find that pretraining projectors with general language modeling objectives enables Vector-ICL, while task-specific finetuning further enhances performance. In our experiments across various tasks and modalities, including text reconstruction, numerical function regression, text classification, summarization, molecule captioning, time-series classification, graph classification, and fMRI decoding, Vector-ICL often surpasses both few-shot ICL and domain-specific model or tuning. We further conduct analyses and case studies, indicating the potential of LLMs to process vector representations beyond traditional token-based paradigms.
Data Contamination Can Cross Language Barriers
Jun 19, 2024The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be \emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from \url{https://github.com/ShangDataLab/Deep-Contam}.
Learning a Decision Tree Algorithm with Transformers
Feb 06, 2024



Decision trees are renowned for their interpretability capability to achieve high predictive performance, especially on tabular data. Traditionally, they are constructed through recursive algorithms, where they partition the data at every node in a tree. However, identifying the best partition is challenging, as decision trees optimized for local segments may not bring global generalization. To address this, we introduce MetaTree, which trains a transformer-based model on filtered outputs from classical algorithms to produce strong decision trees for classification. Specifically, we fit both greedy decision trees and optimized decision trees on a large number of datasets. We then train MetaTree to produce the trees that achieve strong generalization performance. This training enables MetaTree to not only emulate these algorithms, but also to intelligently adapt its strategy according to the context, thereby achieving superior generalization performance.
Waveformer: Linear-Time Attention with Forward and Backward Wavelet Transform
Oct 05, 2022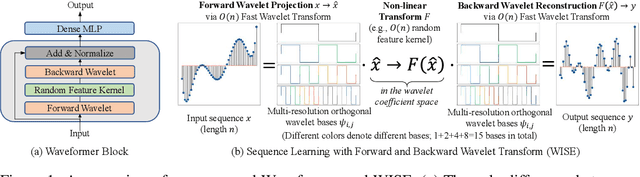
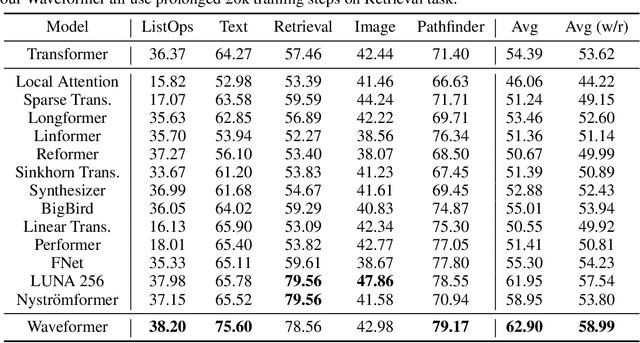
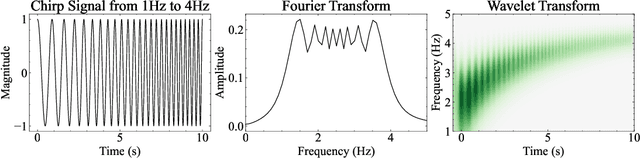

We propose Waveformer that learns attention mechanism in the wavelet coefficient space, requires only linear time complexity, and enjoys universal approximating power. Specifically, we first apply forward wavelet transform to project the input sequences to multi-resolution orthogonal wavelet bases, then conduct nonlinear transformations (in this case, a random feature kernel) in the wavelet coefficient space, and finally reconstruct the representation in input space via backward wavelet transform. We note that other non-linear transformations may be used, hence we name the learning paradigm Wavelet transformatIon for Sequence lEarning (WISE). We emphasize the importance of backward reconstruction in the WISE paradigm -- without it, one would be mixing information from both the input space and coefficient space through skip connections, which shall not be considered as mathematically sound. Compared with Fourier transform in recent works, wavelet transform is more efficient in time complexity and better captures local and positional information; we further support this through our ablation studies. Extensive experiments on seven long-range understanding datasets from the Long Range Arena benchmark and code understanding tasks demonstrate that (1) Waveformer achieves competitive and even better accuracy than a number of state-of-the-art Transformer variants and (2) WISE can boost accuracies of various attention approximation methods without increasing the time complexity. These together showcase the superiority of learning attention in a wavelet coefficient space over the input space.
Reconfigurable Intelligent Surface Assisted OFDM Relaying: Subcarrier Matching with Balanced SNR
Mar 03, 2022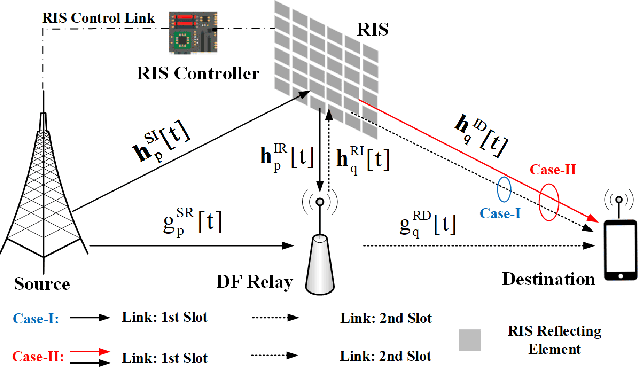
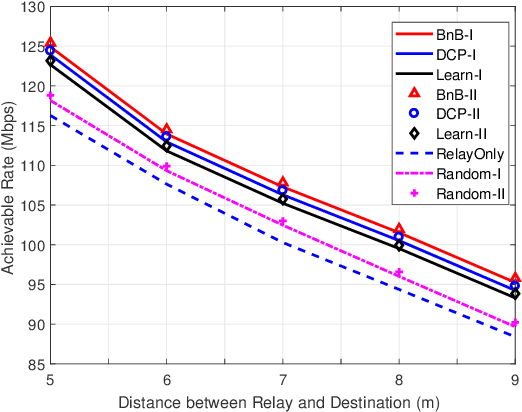


Reconfigurable intelligent surface (RIS) is a promising solution to enhance the performance of wireless communications via reconfiguring the wireless propagation environment. In this paper, we investigate the joint design of RIS passive beamforming and subcarrier matching in RIS-assisted orthogonal frequency division multiplexing (OFDM) dual-hop relaying systems under two cases, depending on the presence of the RIS reflected link from the source to the destination in the first hop. Accordingly, we formulate a mixed-integer nonlinear programming (MINIP) problem to maximize the sum achievable rate over all subcarriers by jointly optimizing the RIS passive beamforming and subcarrier matching. To solve this challenging problem, we first develop a branch-and-bound (BnB)-based alternating optimization algorithm to obtain a near-optimal solution by alternatively optimizing the subcarrier matching by the BnB method and the RIS passive beamforming by using semidefinite relaxation techniques. Then, a low-complexity difference-of-convex penalty-based algorithm is proposed to reduce the computation complexity in the BnB method. To further reduce the computational complexity, we utilize the learning-to-optimize approach to learn the joint design obtained from optimization techniques, which is more amenable to practical implementations. Lastly, computer simulations are presented to evaluate the performance of the proposed algorithms in the two cases. Simulation results demonstrate that the RIS-assisted OFDM relaying system achieves sustainable achievable rate gain as compared to that without RIS, and that with random passive beamforming, since RIS passive beamforming can be leveraged to recast the subcarrier matching among different subcarriers and balance the signal-to-noise ratio within each subcarrier pair.
Data-Driven and SE-assisted AI Model Signal-Awareness Enhancement and Introspection
Nov 10, 2021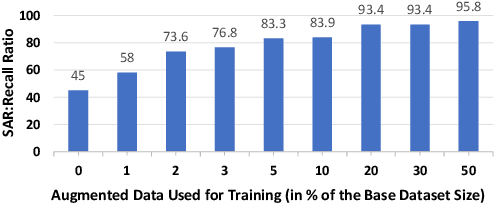
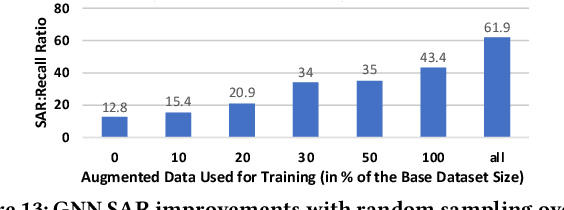
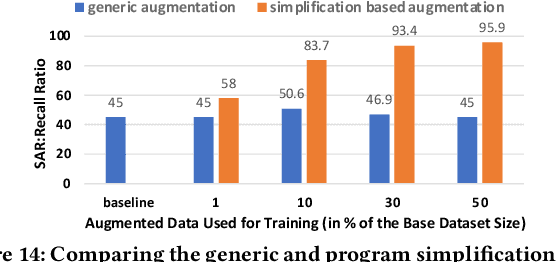
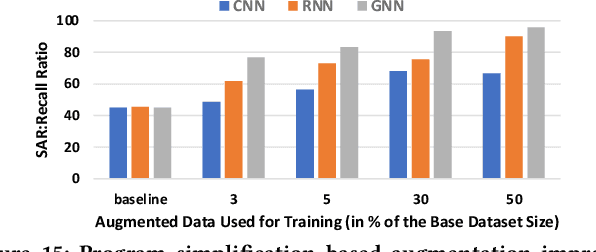
AI modeling for source code understanding tasks has been making significant progress, and is being adopted in production development pipelines. However, reliability concerns, especially whether the models are actually learning task-related aspects of source code, are being raised. While recent model-probing approaches have observed a lack of signal awareness in many AI-for-code models, i.e. models not capturing task-relevant signals, they do not offer solutions to rectify this problem. In this paper, we explore data-driven approaches to enhance models' signal-awareness: 1) we combine the SE concept of code complexity with the AI technique of curriculum learning; 2) we incorporate SE assistance into AI models by customizing Delta Debugging to generate simplified signal-preserving programs, augmenting them to the training dataset. With our techniques, we achieve up to 4.8x improvement in model signal awareness. Using the notion of code complexity, we further present a novel model learning introspection approach from the perspective of the dataset.