 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOScaR: The Occam's Razor for Extreme KV Cache Quantization in LLMs and Beyond
May 19, 2026The rapid advancement toward long-context reasoning and multi-modal intelligence has made the memory footprint of the Key-Value (KV) cache a dominant memory bottleneck for efficient deployment. While the established per-channel quantization effectively accommodates intrinsic channel-wise outliers in Key tensors, its efficacy diminishes under extreme compression. In this work, we revisit the inherent limitations of the per-channel quantization paradigm from both empirical and theoretical perspectives. Our analysis identifies Token Norm Imbalance (TNI) as the primary bottleneck to quantization fidelity. We demonstrate that TNI systematically amplifies errors when shared quantization parameters are required to span token groups exhibiting substantial norm disparities. Instead of relying on intricate quantization pipelines (e.g., TurboQuant), we propose OScaR (Omni-Scaled Canalized Rotation), an accurate and lightweight KV cache compression framework for X-LLMs (i.e., text-only, multi-modal, and omni-modal LLMs). Advancing the per-channel paradigm, OScaR employs Canalized Rotation followed by Omni-Token Scaling to mitigate TNI-induced sequence-dimensional variance both effectively and efficiently, further supported by our optimized system design and CUDA kernels. Extensive evaluations across X-LLMs show that OScaR consistently outperforms existing methods and achieves near-lossless performance under INT2 quantization, establishing it as a robust, low-complexity, and universal framework that defines a new Pareto front. Compared with the BF16 FlashDecoding-v2 baseline, our OScaR implementation achieves a notable up to 3.0x speedup in decoding, reduces memory footprint by 5.3x, and increases throughput by 4.1x. The code for OScaR is publicly available at https://github.com/ZunhaiSu/OScaR-KV-Quant.
Memory Centric Power Allocation for Multi-Agent Embodied Question Answering
Apr 20, 2026This paper considers multi-agent embodied question answering (MA-EQA), which aims to query robot teams on what they have seen over a long horizon. In contrast to existing edge resource management methods that emphasize sensing, communication, or computation performance metrics, MA-EQA emphasizes the memory qualities. To cope with this paradigm shift, we propose a quality of memory (QoM) model based on generative adversarial exam (GAE), which leverages forward simulation to assess memory retrieval and uses the resulting exam scores to compute QoM values. Then we propose memory centric power allocation (MCPA), which maximizes the QoM function under communication resource constraints. Through asymptotic analysis, it is found that the transmit powers are proportional to the GAE error probability, thus prioritizing towards high-QoM robots. Extensive experiments demonstrate that MCPA achieves significant improvements over extensive benchmarks in terms of diverse metrics in various scenarios.
Learning to Jointly Optimize Antenna Positioning and Beamforming for Movable Antenna-Aided Systems
Mar 17, 2026The recently emerged movable antenna (MA) and fluid antenna technologies offer promising solutions to enhance the spatial degrees of freedom in wireless systems by dynamically adjusting the positions of transmit or receive antennas within given regions. In this paper, we aim to address the joint optimization problem of antenna positioning and beamforming in MA-aided multi-user downlink transmission systems. This problem involves mixed discrete antenna position and continuous beamforming weight variables, along with coupled distance constraints on antenna positions, which pose significant challenges for optimization algorithm design. To overcome these challenges, we propose an end-to-end deep learning framework, consisting of a positioning model that handles the discrete variables and the coupled constraints, and a beamforming model that handles the continuous variables. Simulation results demonstrate that the proposed framework achieves superior sum rate performance, yet with much reduced computation time compared to existing methods.
Unified framework for outage-constrained rate maximization in secure ISAC under various sensing metrics
Mar 13, 2026Integrated sensing and communication (ISAC) is poised to redefine the landscape of wireless networks by seamlessly combining data transmission and environmental sensing. However, ISAC systems remain susceptible to eavesdropping, especially under uncertainty in eavesdroppers' channel state information, which can lead to secrecy outages. On the other hand, diverse and complex sensing performance requirements further complicate resource optimization, often requiring custom solutions for each scenario. To this end, this paper introduces a unified optimization framework that holistically addresses both the worst-case user secrecy rate and the sum secrecy rate across multiple users. Besides putting the two commonly used objectives into a single but flexible objective function, the framework accurately controls secrecy outage probabilities while accommodating a broad spectrum of sensing constraints. To solve such a general problem, we integrate the sensing requirements into the objective function through an auxiliary variable. This enables efficient alternating optimization and the proposed approach is theoretically guaranteed to converge to at least a stationary point of the original problem. Extensive simulation results show that the proposed framework consistently achieves higher optimized secrecy rates under various sensing constraints compared to existing methods. These results underscore the proposed unified framework's superiority and versatility in secure ISAC systems.
HPTune: Hierarchical Proactive Tuning for Collision-Free Model Predictive Control
Jan 29, 2026Parameter tuning is a powerful approach to enhance adaptability in model predictive control (MPC) motion planners. However, existing methods typically operate in a myopic fashion that only evaluates executed actions, leading to inefficient parameter updates due to the sparsity of failure events (e.g., obstacle nearness or collision). To cope with this issue, we propose to extend evaluation from executed to non-executed actions, yielding a hierarchical proactive tuning (HPTune) framework that combines both a fast-level tuning and a slow-level tuning. The fast one adopts risk indicators of predictive closing speed and predictive proximity distance, and the slow one leverages an extended evaluation loss for closed-loop backpropagation. Additionally, we integrate HPTune with the Doppler LiDAR that provides obstacle velocities apart from position-only measurements for enhanced motion predictions, thus facilitating the implementation of HPTune. Extensive experiments on high-fidelity simulator demonstrate that HPTune achieves efficient MPC tuning and outperforms various baseline schemes in complex environments. It is found that HPTune enables situation-tailored motion planning by formulating a safe, agile collision avoidance strategy.
When Bayesian Tensor Completion Meets Multioutput Gaussian Processes: Functional Universality and Rank Learning
Dec 25, 2025Functional tensor decomposition can analyze multi-dimensional data with real-valued indices, paving the path for applications in machine learning and signal processing. A limitation of existing approaches is the assumption that the tensor rank-a critical parameter governing model complexity-is known. However, determining the optimal rank is a non-deterministic polynomial-time hard (NP-hard) task and there is a limited understanding regarding the expressive power of functional low-rank tensor models for continuous signals. We propose a rank-revealing functional Bayesian tensor completion (RR-FBTC) method. Modeling the latent functions through carefully designed multioutput Gaussian processes, RR-FBTC handles tensors with real-valued indices while enabling automatic tensor rank determination during the inference process. We establish the universal approximation property of the model for continuous multi-dimensional signals, demonstrating its expressive power in a concise format. To learn this model, we employ the variational inference framework and derive an efficient algorithm with closed-form updates. Experiments on both synthetic and real-world datasets demonstrate the effectiveness and superiority of the RR-FBTC over state-of-the-art approaches. The code is available at https://github.com/OceanSTARLab/RR-FBTC.
A Unified Distributed Algorithm for Hybrid Near-Far Field Activity Detection in Cell-Free Massive MIMO
Sep 18, 2025
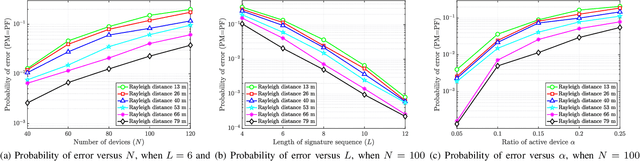
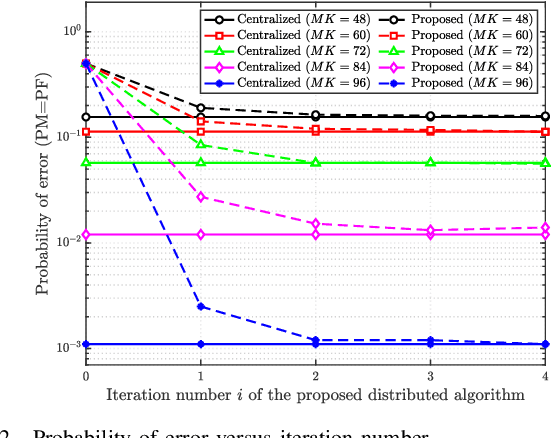
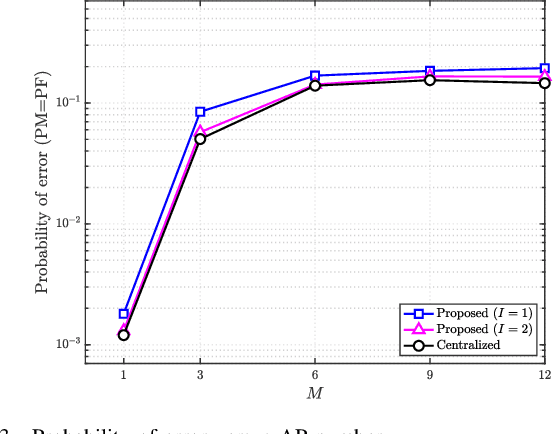
A great amount of endeavor has recently been devoted to activity detection for massive machine-type communications in cell-free multiple-input multiple-output (MIMO) systems. However, as the number of antennas at the access points (APs) increases, the Rayleigh distance that separates the near-field and far-field regions also expands, rendering the conventional assumption of far-field propagation alone impractical. To address this challenge, this paper establishes a covariance-based formulation that can effectively capture the statistical property of hybrid near-far field channels. Based on this formulation, we theoretically reveal that increasing the proportion of near-field channels enhances the detection performance. Furthermore, we propose a distributed algorithm, where each AP performs local activity detection and only exchanges the detection results to the central processing unit, thus significantly reducing the computational complexity and the communication overhead. Not only with convergence guarantee, the proposed algorithm is unified in the sense that it can handle single-cell or cell-free systems with either near-field or far-field devices as special cases. Simulation results validate the theoretical analyses and demonstrate the superior performance of the proposed approach compared with existing methods.
Aligning Effective Tokens with Video Anomaly in Large Language Models
Aug 08, 2025Understanding abnormal events in videos is a vital and challenging task that has garnered significant attention in a wide range of applications. Although current video understanding Multi-modal Large Language Models (MLLMs) are capable of analyzing general videos, they often struggle to handle anomalies due to the spatial and temporal sparsity of abnormal events, where the redundant information always leads to suboptimal outcomes. To address these challenges, exploiting the representation and generalization capabilities of Vison Language Models (VLMs) and Large Language Models (LLMs), we propose VA-GPT, a novel MLLM designed for summarizing and localizing abnormal events in various videos. Our approach efficiently aligns effective tokens between visual encoders and LLMs through two key proposed modules: Spatial Effective Token Selection (SETS) and Temporal Effective Token Generation (TETG). These modules enable our model to effectively capture and analyze both spatial and temporal information associated with abnormal events, resulting in more accurate responses and interactions. Furthermore, we construct an instruction-following dataset specifically for fine-tuning video-anomaly-aware MLLMs, and introduce a cross-domain evaluation benchmark based on XD-Violence dataset. Our proposed method outperforms existing state-of-the-art methods on various benchmarks.
Distributed Activity Detection for Cell-Free Hybrid Near-Far Field Communications
Jun 17, 2025A great amount of endeavor has recently been devoted to activity detection for massive machine-type communications in cell-free massive MIMO. However, in practice, as the number of antennas at the access points (APs) increases, the Rayleigh distance that separates the near-field and far-field regions also expands, rendering the conventional assumption of far-field propagation alone impractical. To address this challenge, this paper considers a hybrid near-far field activity detection in cell-free massive MIMO, and establishes a covariance-based formulation, which facilitates the development of a distributed algorithm to alleviate the computational burden at the central processing unit (CPU). Specifically, each AP performs local activity detection for the devices and then transmits the detection result to the CPU for further processing. In particular, a novel coordinate descent algorithm based on the Sherman-Morrison-Woodbury update with Taylor expansion is proposed to handle the local detection problem at each AP. Moreover, we theoretically analyze how the hybrid near-far field channels affect the detection performance. Simulation results validate the theoretical analysis and demonstrate the superior performance of the proposed approach compared with existing approaches.
FieldFormer: Self-supervised Reconstruction of Physical Fields via Tensor Attention Prior
Jun 13, 2025Reconstructing physical field tensors from \textit{in situ} observations, such as radio maps and ocean sound speed fields, is crucial for enabling environment-aware decision making in various applications, e.g., wireless communications and underwater acoustics. Field data reconstruction is often challenging, due to the limited and noisy nature of the observations, necessitating the incorporation of prior information to aid the reconstruction process. Deep neural network-based data-driven structural constraints (e.g., ``deeply learned priors'') have showed promising performance. However, this family of techniques faces challenges such as model mismatches between training and testing phases. This work introduces FieldFormer, a self-supervised neural prior learned solely from the limited {\it in situ} observations without the need of offline training. Specifically, the proposed framework starts with modeling the fields of interest using the tensor Tucker model of a high multilinear rank, which ensures a universal approximation property for all fields. In the sequel, an attention mechanism is incorporated to learn the sparsity pattern that underlies the core tensor in order to reduce the solution space. In this way, a ``complexity-adaptive'' neural representation, grounded in the Tucker decomposition, is obtained that can flexibly represent various types of fields. A theoretical analysis is provided to support the recoverability of the proposed design. Moreover, extensive experiments, using various physical field tensors, demonstrate the superiority of the proposed approach compared to state-of-the-art baselines.