 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Distributed Algorithm for Hybrid Near-Far Field Activity Detection in Cell-Free Massive MIMO
Sep 18, 2025
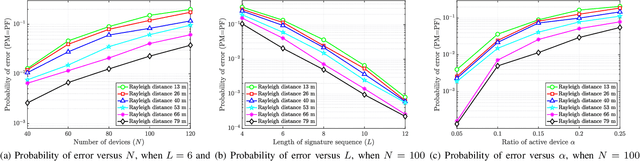
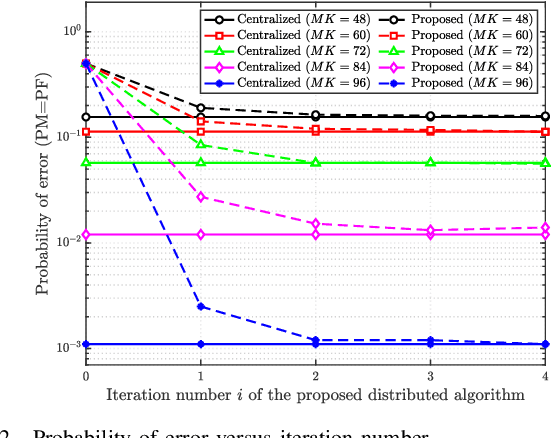
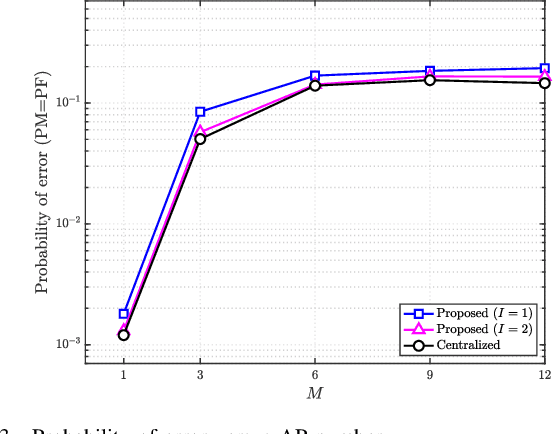
A great amount of endeavor has recently been devoted to activity detection for massive machine-type communications in cell-free multiple-input multiple-output (MIMO) systems. However, as the number of antennas at the access points (APs) increases, the Rayleigh distance that separates the near-field and far-field regions also expands, rendering the conventional assumption of far-field propagation alone impractical. To address this challenge, this paper establishes a covariance-based formulation that can effectively capture the statistical property of hybrid near-far field channels. Based on this formulation, we theoretically reveal that increasing the proportion of near-field channels enhances the detection performance. Furthermore, we propose a distributed algorithm, where each AP performs local activity detection and only exchanges the detection results to the central processing unit, thus significantly reducing the computational complexity and the communication overhead. Not only with convergence guarantee, the proposed algorithm is unified in the sense that it can handle single-cell or cell-free systems with either near-field or far-field devices as special cases. Simulation results validate the theoretical analyses and demonstrate the superior performance of the proposed approach compared with existing methods.
Distributed Activity Detection for Cell-Free Hybrid Near-Far Field Communications
Jun 17, 2025A great amount of endeavor has recently been devoted to activity detection for massive machine-type communications in cell-free massive MIMO. However, in practice, as the number of antennas at the access points (APs) increases, the Rayleigh distance that separates the near-field and far-field regions also expands, rendering the conventional assumption of far-field propagation alone impractical. To address this challenge, this paper considers a hybrid near-far field activity detection in cell-free massive MIMO, and establishes a covariance-based formulation, which facilitates the development of a distributed algorithm to alleviate the computational burden at the central processing unit (CPU). Specifically, each AP performs local activity detection for the devices and then transmits the detection result to the CPU for further processing. In particular, a novel coordinate descent algorithm based on the Sherman-Morrison-Woodbury update with Taylor expansion is proposed to handle the local detection problem at each AP. Moreover, we theoretically analyze how the hybrid near-far field channels affect the detection performance. Simulation results validate the theoretical analysis and demonstrate the superior performance of the proposed approach compared with existing approaches.
Deep Unfolding with Kernel-based Quantization in MIMO Detection
May 19, 2025The development of edge computing places critical demands on energy-efficient model deployment for multiple-input multiple-output (MIMO) detection tasks. Deploying deep unfolding models such as PGD-Nets and ADMM-Nets into resource-constrained edge devices using quantization methods is challenging. Existing quantization methods based on quantization aware training (QAT) suffer from performance degradation due to their reliance on parametric distribution assumption of activations and static quantization step sizes. To address these challenges, this paper proposes a novel kernel-based adaptive quantization (KAQ) framework for deep unfolding networks. By utilizing a joint kernel density estimation (KDE) and maximum mean discrepancy (MMD) approach to align activation distributions between full-precision and quantized models, the need for prior distribution assumptions is eliminated. Additionally, a dynamic step size updating method is introduced to adjust the quantization step size based on the channel conditions of wireless networks. Extensive simulations demonstrate that the accuracy of proposed KAQ framework outperforms traditional methods and successfully reduces the model's inference latency.
A General Optimization Framework for Tackling Distance Constraints in Movable Antenna-Aided Systems
Mar 04, 2025The recently emerged movable antenna (MA) shows great promise in leveraging spatial degrees of freedom to enhance the performance of wireless systems. However, resource allocation in MA-aided systems faces challenges due to the nonconvex and coupled constraints on antenna positions. This paper systematically reveals the challenges posed by the minimum antenna separation distance constraints. Furthermore, we propose a penalty optimization framework for resource allocation under such new constraints for MA-aided systems. Specifically, the proposed framework separates the non-convex and coupled antenna distance constraints from the movable region constraints by introducing auxiliary variables. Subsequently, the resulting problem is efficiently solved by alternating optimization, where the optimization of the original variables resembles that in conventional resource allocation problem while the optimization with respect to the auxiliary variables is achieved in closedform solutions. To illustrate the effectiveness of the proposed framework, we present three case studies: capacity maximization, latency minimization, and regularized zero-forcing precoding. Simulation results demonstrate that the proposed optimization framework consistently outperforms state-of-the-art schemes.
Mixture of Experts-augmented Deep Unfolding for Activity Detection in IRS-aided Systems
Feb 27, 2025In the realm of activity detection for massive machine-type communications, intelligent reflecting surfaces (IRS) have shown significant potential in enhancing coverage for devices lacking direct connections to the base station (BS). However, traditional activity detection methods are typically designed for a single type of channel model, which does not reflect the complexities of real-world scenarios, particularly in systems incorporating IRS. To address this challenge, this paper introduces a novel approach that combines model-driven deep unfolding with a mixture of experts (MoE) framework. By automatically selecting one of three expert designs and applying it to the unfolded projected gradient method, our approach eliminates the need for prior knowledge of channel types between devices and the BS. Simulation results demonstrate that the proposed MoE-augmented deep unfolding method surpasses the traditional covariance-based method and black-box neural network design, delivering superior detection performance under mixed channel fading conditions.
Enhancing Large Vision Model in Street Scene Semantic Understanding through Leveraging Posterior Optimization Trajectory
Jan 03, 2025To improve the generalization of the autonomous driving (AD) perception model, vehicles need to update the model over time based on the continuously collected data. As time progresses, the amount of data fitted by the AD model expands, which helps to improve the AD model generalization substantially. However, such ever-expanding data is a double-edged sword for the AD model. Specifically, as the fitted data volume grows to exceed the the AD model's fitting capacities, the AD model is prone to under-fitting. To address this issue, we propose to use a pretrained Large Vision Models (LVMs) as backbone coupled with downstream perception head to understand AD semantic information. This design can not only surmount the aforementioned under-fitting problem due to LVMs' powerful fitting capabilities, but also enhance the perception generalization thanks to LVMs' vast and diverse training data. On the other hand, to mitigate vehicles' computational burden of training the perception head while running LVM backbone, we introduce a Posterior Optimization Trajectory (POT)-Guided optimization scheme (POTGui) to accelerate the convergence. Concretely, we propose a POT Generator (POTGen) to generate posterior (future) optimization direction in advance to guide the current optimization iteration, through which the model can generally converge within 10 epochs. Extensive experiments demonstrate that the proposed method improves the performance by over 66.48\% and converges faster over 6 times, compared to the existing state-of-the-art approach.
Deep Unfolding Beamforming and Power Control Designs for Multi-Port Matching Networks
Dec 09, 2024



The key technologies of sixth generation (6G), such as ultra-massive multiple-input multiple-output (MIMO), enable intricate interactions between antennas and wireless propagation environments. As a result, it becomes necessary to develop joint models that encompass both antennas and wireless propagation channels. To achieve this, we utilize the multi-port communication theory, which considers impedance matching among the source, transmission medium, and load to facilitate efficient power transfer. Specifically, we first investigate the impact of insertion loss, mutual coupling, and other factors on the performance of multi-port matching networks. Next, to further improve system performance, we explore two important deep unfolding designs for the multi-port matching networks: beamforming and power control, respectively. For the hybrid beamforming, we develop a deep unfolding framework, i.e., projected gradient descent (PGD)-Net based on unfolding projected gradient descent. For the power control, we design a deep unfolding network, graph neural network (GNN) aided alternating optimization (AO)Net, which considers the interaction between different ports in optimizing power allocation. Numerical results verify the necessity of considering insertion loss in the dynamic metasurface antenna (DMA) performance analysis. Besides, the proposed PGD-Net based hybrid beamforming approaches approximate the conventional model-based algorithm with very low complexity. Moreover, our proposed power control scheme has a fast run time compared to the traditional weighted minimum mean squared error (WMMSE) method.
Fast-Convergent and Communication-Alleviated Heterogeneous Hierarchical Federated Learning in Autonomous Driving
Sep 29, 2024Street Scene Semantic Understanding (denoted as TriSU) is a complex task for autonomous driving (AD). However, inference model trained from data in a particular geographical region faces poor generalization when applied in other regions due to inter-city data domain-shift. Hierarchical Federated Learning (HFL) offers a potential solution for improving TriSU model generalization by collaborative privacy-preserving training over distributed datasets from different cities. Unfortunately, it suffers from slow convergence because data from different cities are with disparate statistical properties. Going beyond existing HFL methods, we propose a Gaussian heterogeneous HFL algorithm (FedGau) to address inter-city data heterogeneity so that convergence can be accelerated. In the proposed FedGau algorithm, both single RGB image and RGB dataset are modelled as Gaussian distributions for aggregation weight design. This approach not only differentiates each RGB image by respective statistical distribution, but also exploits the statistics of dataset from each city in addition to the conventionally considered data volume. With the proposed approach, the convergence is accelerated by 35.5\%-40.6\% compared to existing state-of-the-art (SOTA) HFL methods. On the other hand, to reduce the involved communication resource, we further introduce a novel performance-aware adaptive resource scheduling (AdapRS) policy. Unlike the traditional static resource scheduling policy that exchanges a fixed number of models between two adjacent aggregations, AdapRS adjusts the number of model aggregation at different levels of HFL so that unnecessary communications are minimized. Extensive experiments demonstrate that AdapRS saves 29.65\% communication overhead compared to conventional static resource scheduling policy while maintaining almost the same performance.
Handling Distance Constraint in Movable Antenna Aided Systems: A General Optimization Framework
Jul 11, 2024The movable antenna (MA) is a promising technology to exploit more spatial degrees of freedom for enhancing wireless system performance. However, the MA-aided system introduces the non-convex antenna distance constraints, which poses challenges in the underlying optimization problems. To fill this gap, this paper proposes a general framework for optimizing the MA-aided system under the antenna distance constraints. Specifically, we separate the non-convex antenna distance constraints from the objective function by introducing auxiliary variables. Then, the resulting problem can be efficiently solved under the alternating optimization framework. For the subproblems with respect to the antenna position variables and auxiliary variables, the proposed algorithms are able to obtain at least stationary points without any approximations. To verify the effectiveness of the proposed optimization framework, we present two case studies: capacity maximization and regularized zero-forcing precoding. Simulation results demonstrate the proposed optimization framework outperforms the existing baseline schemes under both cases.
FedRC: A Rapid-Converged Hierarchical Federated Learning Framework in Street Scene Semantic Understanding
Jul 01, 2024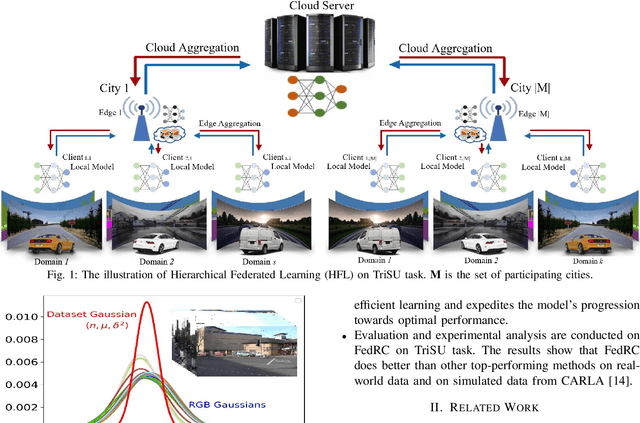
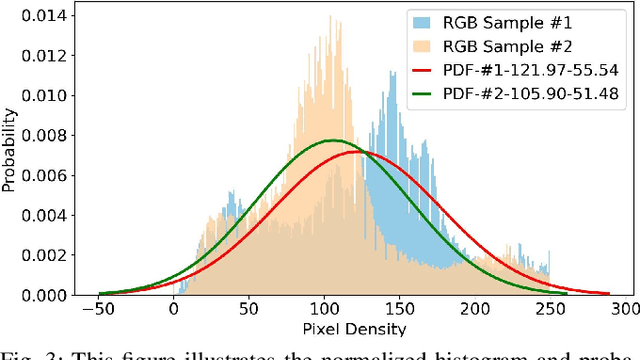
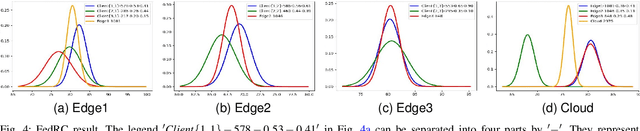

Street Scene Semantic Understanding (denoted as TriSU) is a crucial but complex task for world-wide distributed autonomous driving (AD) vehicles (e.g., Tesla). Its inference model faces poor generalization issue due to inter-city domain-shift. Hierarchical Federated Learning (HFL) offers a potential solution for improving TriSU model generalization, but suffers from slow convergence rate because of vehicles' surrounding heterogeneity across cities. Going beyond existing HFL works that have deficient capabilities in complex tasks, we propose a rapid-converged heterogeneous HFL framework (FedRC) to address the inter-city data heterogeneity and accelerate HFL model convergence rate. In our proposed FedRC framework, both single RGB image and RGB dataset are modelled as Gaussian distributions in HFL aggregation weight design. This approach not only differentiates each RGB sample instead of typically equalizing them, but also considers both data volume and statistical properties rather than simply taking data quantity into consideration. Extensive experiments on the TriSU task using across-city datasets demonstrate that FedRC converges faster than the state-of-the-art benchmark by 38.7%, 37.5%, 35.5%, and 40.6% in terms of mIoU, mPrecision, mRecall, and mF1, respectively. Furthermore, qualitative evaluations in the CARLA simulation environment confirm that the proposed FedRC framework delivers top-tier performance.