 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNirvana: A Specialized Generalist Model With Task-Aware Memory Mechanism
Oct 30, 2025Specialized Generalist Models (SGMs) aim to preserve broad capabilities while achieving expert-level performance in target domains. However, traditional LLM structures including Transformer, Linear Attention, and hybrid models do not employ specialized memory mechanism guided by task information. In this paper, we present Nirvana, an SGM with specialized memory mechanism, linear time complexity, and test-time task information extraction. Besides, we propose the Task-Aware Memory Trigger ($\textit{Trigger}$) that flexibly adjusts memory mechanism based on the current task's requirements. In Trigger, each incoming sample is treated as a self-supervised fine-tuning task, enabling Nirvana to adapt its task-related parameters on the fly to domain shifts. We also design the Specialized Memory Updater ($\textit{Updater}$) that dynamically memorizes the context guided by Trigger. We conduct experiments on both general language tasks and specialized medical tasks. On a variety of natural language modeling benchmarks, Nirvana achieves competitive or superior results compared to the existing LLM structures. To prove the effectiveness of Trigger on specialized tasks, we test Nirvana's performance on a challenging medical task, i.e., Magnetic Resonance Imaging (MRI). We post-train frozen Nirvana backbone with lightweight codecs on paired electromagnetic signals and MRI images. Despite the frozen Nirvana backbone, Trigger guides the model to adapt to the MRI domain with the change of task-related parameters. Nirvana achieves higher-quality MRI reconstruction compared to conventional MRI models as well as the models with traditional LLMs' backbone, and can also generate accurate preliminary clinical reports accordingly.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
Automating Exploratory Multiomics Research via Language Models
Jun 09, 2025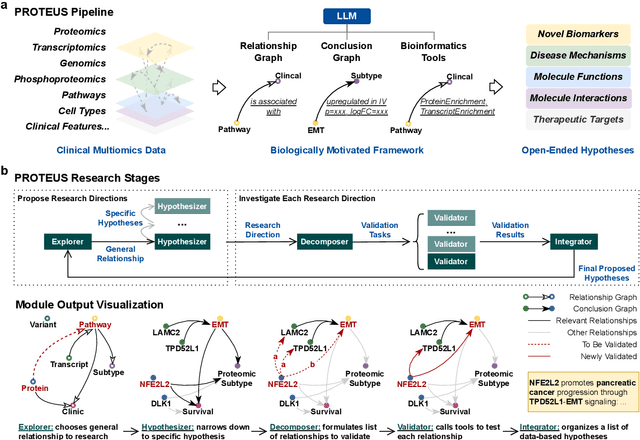
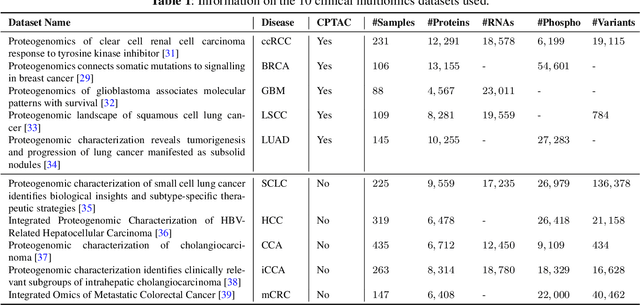
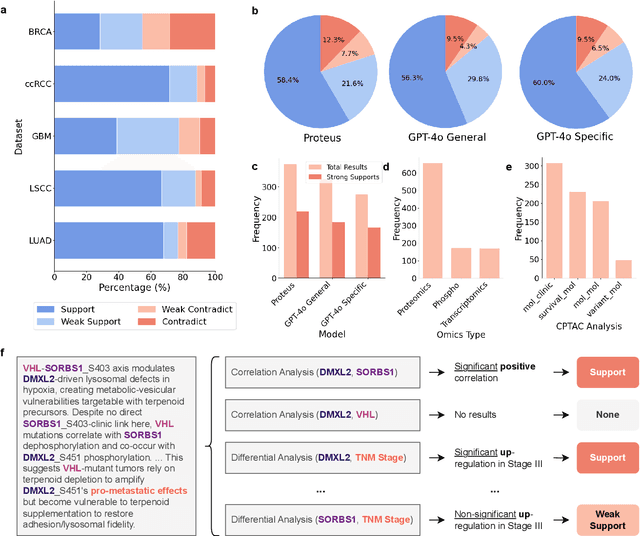

This paper introduces PROTEUS, a fully automated system that produces data-driven hypotheses from raw data files. We apply PROTEUS to clinical proteogenomics, a field where effective downstream data analysis and hypothesis proposal is crucial for producing novel discoveries. PROTEUS uses separate modules to simulate different stages of the scientific process, from open-ended data exploration to specific statistical analysis and hypothesis proposal. It formulates research directions, tools, and results in terms of relationships between biological entities, using unified graph structures to manage complex research processes. We applied PROTEUS to 10 clinical multiomics datasets from published research, arriving at 360 total hypotheses. Results were evaluated through external data validation and automatic open-ended scoring. Through exploratory and iterative research, the system can navigate high-throughput and heterogeneous multiomics data to arrive at hypotheses that balance reliability and novelty. In addition to accelerating multiomic analysis, PROTEUS represents a path towards tailoring general autonomous systems to specialized scientific domains to achieve open-ended hypothesis generation from data.
Deep Unfolding with Kernel-based Quantization in MIMO Detection
May 19, 2025The development of edge computing places critical demands on energy-efficient model deployment for multiple-input multiple-output (MIMO) detection tasks. Deploying deep unfolding models such as PGD-Nets and ADMM-Nets into resource-constrained edge devices using quantization methods is challenging. Existing quantization methods based on quantization aware training (QAT) suffer from performance degradation due to their reliance on parametric distribution assumption of activations and static quantization step sizes. To address these challenges, this paper proposes a novel kernel-based adaptive quantization (KAQ) framework for deep unfolding networks. By utilizing a joint kernel density estimation (KDE) and maximum mean discrepancy (MMD) approach to align activation distributions between full-precision and quantized models, the need for prior distribution assumptions is eliminated. Additionally, a dynamic step size updating method is introduced to adjust the quantization step size based on the channel conditions of wireless networks. Extensive simulations demonstrate that the accuracy of proposed KAQ framework outperforms traditional methods and successfully reduces the model's inference latency.
Technologies on Effectiveness and Efficiency: A Survey of State Spaces Models
Mar 14, 2025



State Space Models (SSMs) have emerged as a promising alternative to the popular transformer-based models and have been increasingly gaining attention. Compared to transformers, SSMs excel at tasks with sequential data or longer contexts, demonstrating comparable performances with significant efficiency gains. In this survey, we provide a coherent and systematic overview for SSMs, including their theoretical motivations, mathematical formulations, comparison with existing model classes, and various applications. We divide the SSM series into three main sections, providing a detailed introduction to the original SSM, the structured SSM represented by S4, and the selective SSM typified by Mamba. We put an emphasis on technicality, and highlight the various key techniques introduced to address the effectiveness and efficiency of SSMs. We hope this manuscript serves as an introduction for researchers to explore the theoretical foundations of SSMs.
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
Jan 30, 2025We introduce MedXpertQA, a highly challenging and comprehensive benchmark to evaluate expert-level medical knowledge and advanced reasoning. MedXpertQA includes 4,460 questions spanning 17 specialties and 11 body systems. It includes two subsets, Text for text evaluation and MM for multimodal evaluation. Notably, MM introduces expert-level exam questions with diverse images and rich clinical information, including patient records and examination results, setting it apart from traditional medical multimodal benchmarks with simple QA pairs generated from image captions. MedXpertQA applies rigorous filtering and augmentation to address the insufficient difficulty of existing benchmarks like MedQA, and incorporates specialty board questions to improve clinical relevance and comprehensiveness. We perform data synthesis to mitigate data leakage risk and conduct multiple rounds of expert reviews to ensure accuracy and reliability. We evaluate 16 leading models on MedXpertQA. Moreover, medicine is deeply connected to real-world decision-making, providing a rich and representative setting for assessing reasoning abilities beyond mathematics and code. To this end, we develop a reasoning-oriented subset to facilitate the assessment of o1-like models.
Fourier Position Embedding: Enhancing Attention's Periodic Extension for Length Generalization
Dec 23, 2024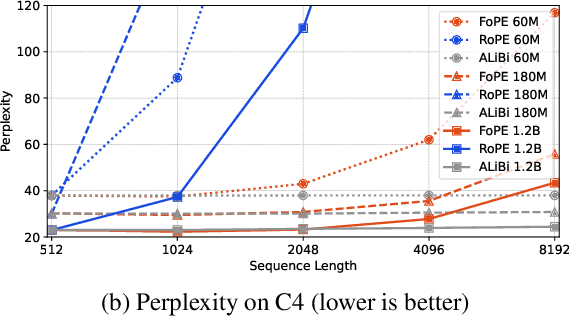
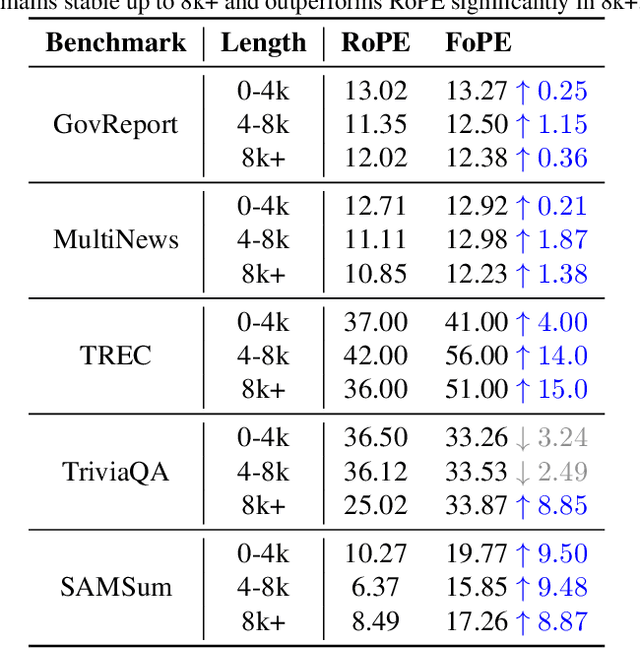
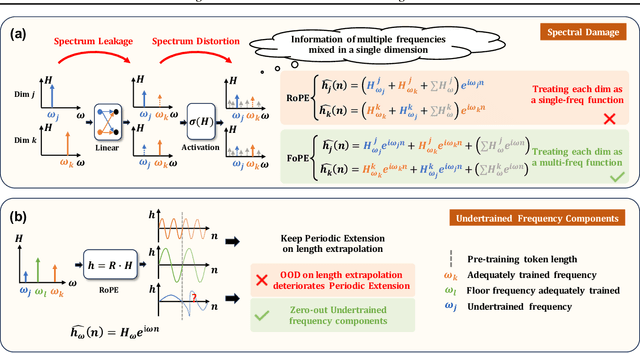
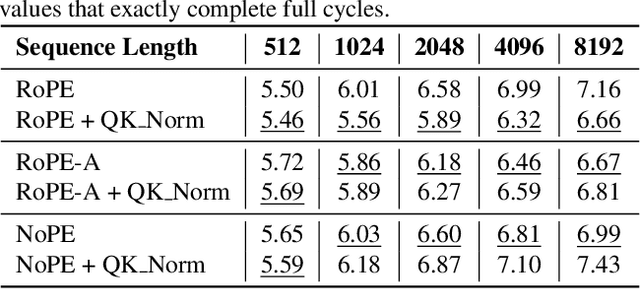
Extending the context length of Language Models (LMs) by improving Rotary Position Embedding (RoPE) has become a trend. While existing works mainly address RoPE's limitations within attention mechanism, this paper provides an analysis across nearly all parts of LMs, uncovering their adverse effects on length generalization for RoPE-based attention. Using Discrete Signal Processing theory, we show that RoPE enables periodic attention by implicitly achieving Non-Uniform Discrete Fourier Transform. However, this periodicity is undermined by the spectral damage caused by: 1) linear layers and activation functions outside of attention; 2) insufficiently trained frequency components brought by time-domain truncation. Building on our observations, we propose Fourier Position Embedding (FoPE), which enhances attention's frequency-domain properties to improve both its periodic extension and length generalization. FoPE constructs Fourier Series and zero-outs the destructive frequency components, increasing model robustness against the spectrum damage. Experiments across various model scales show that, within varying context windows, FoPE can maintain a more stable perplexity and a more consistent accuracy in a needle-in-haystack task compared to RoPE and ALiBi. Several analyses and ablations bring further support to our method and theoretical modeling.
How to Synthesize Text Data without Model Collapse?
Dec 19, 2024

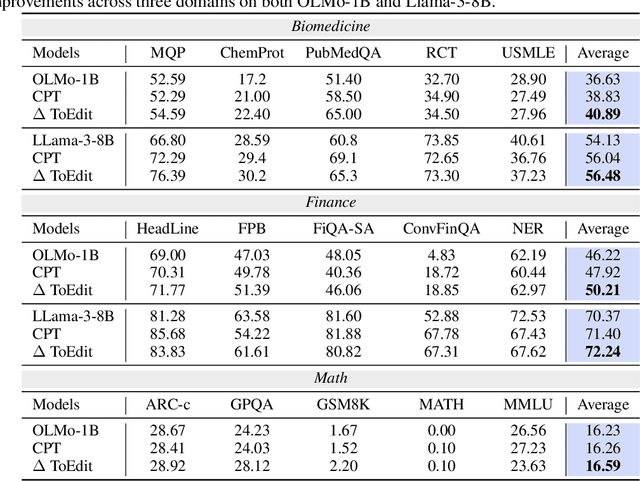
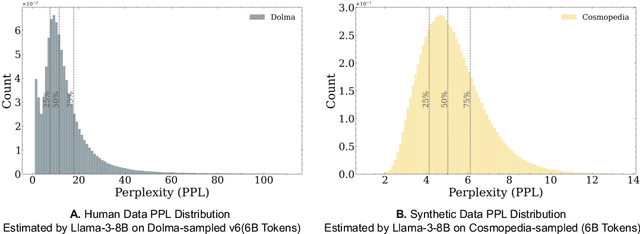
Model collapse in synthetic data indicates that iterative training on self-generated data leads to a gradual decline in performance. With the proliferation of AI models, synthetic data will fundamentally reshape the web data ecosystem. Future GPT-$\{n\}$ models will inevitably be trained on a blend of synthetic and human-produced data. In this paper, we focus on two questions: what is the impact of synthetic data on language model training, and how to synthesize data without model collapse? We first pre-train language models across different proportions of synthetic data, revealing a negative correlation between the proportion of synthetic data and model performance. We further conduct statistical analysis on synthetic data to uncover distributional shift phenomenon and over-concentration of n-gram features. Inspired by the above findings, we propose token editing on human-produced data to obtain semi-synthetic data. As a proof of concept, we theoretically demonstrate that token-level editing can prevent model collapse, as the test error is constrained by a finite upper bound. We conduct extensive experiments on pre-training from scratch, continual pre-training, and supervised fine-tuning. The results validate our theoretical proof that token-level editing improves data quality and enhances model performance.
Automating Exploratory Proteomics Research via Language Models
Nov 06, 2024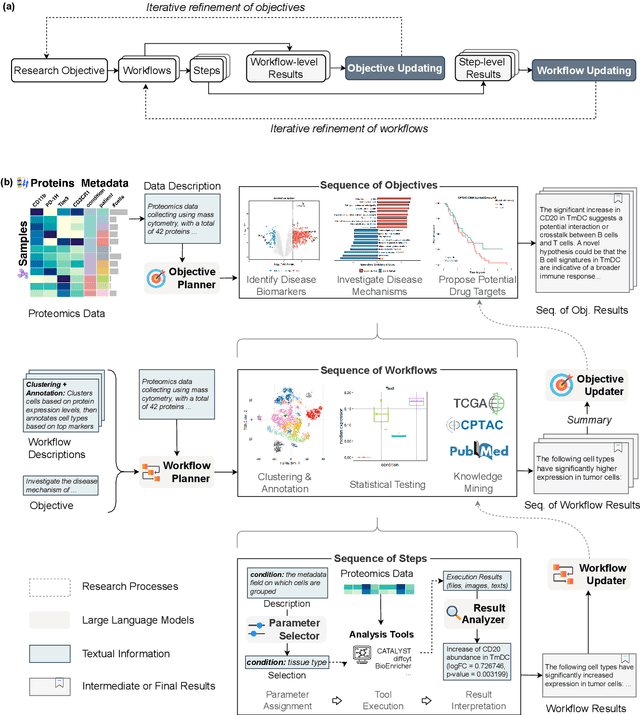
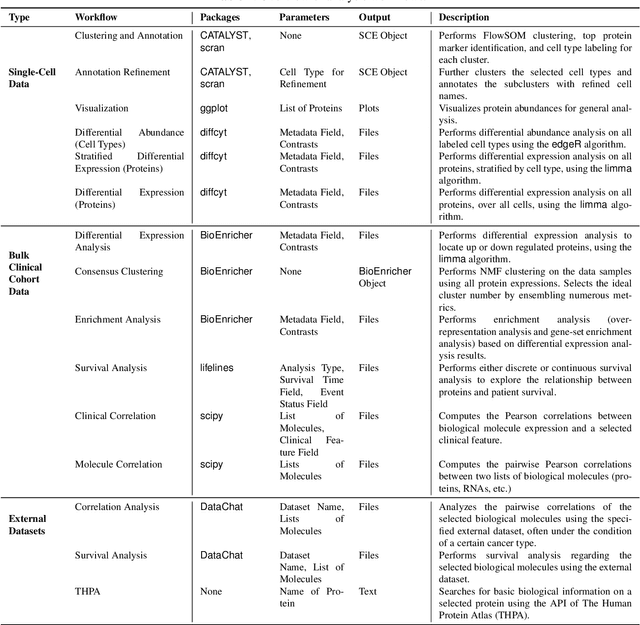
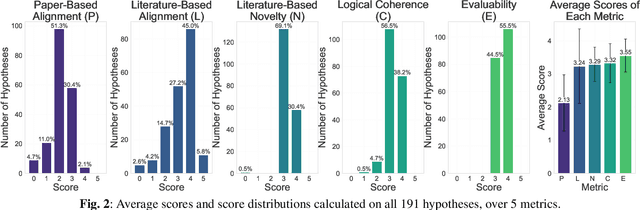
With the development of artificial intelligence, its contribution to science is evolving from simulating a complex problem to automating entire research processes and producing novel discoveries. Achieving this advancement requires both specialized general models grounded in real-world scientific data and iterative, exploratory frameworks that mirror human scientific methodologies. In this paper, we present PROTEUS, a fully automated system for scientific discovery from raw proteomics data. PROTEUS uses large language models (LLMs) to perform hierarchical planning, execute specialized bioinformatics tools, and iteratively refine analysis workflows to generate high-quality scientific hypotheses. The system takes proteomics datasets as input and produces a comprehensive set of research objectives, analysis results, and novel biological hypotheses without human intervention. We evaluated PROTEUS on 12 proteomics datasets collected from various biological samples (e.g. immune cells, tumors) and different sample types (single-cell and bulk), generating 191 scientific hypotheses. These were assessed using both automatic LLM-based scoring on 5 metrics and detailed reviews from human experts. Results demonstrate that PROTEUS consistently produces reliable, logically coherent results that align well with existing literature while also proposing novel, evaluable hypotheses. The system's flexible architecture facilitates seamless integration of diverse analysis tools and adaptation to different proteomics data types. By automating complex proteomics analysis workflows and hypothesis generation, PROTEUS has the potential to considerably accelerate the pace of scientific discovery in proteomics research, enabling researchers to efficiently explore large-scale datasets and uncover biological insights.