 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Exploratory Multiomics Research via Language Models
Jun 09, 2025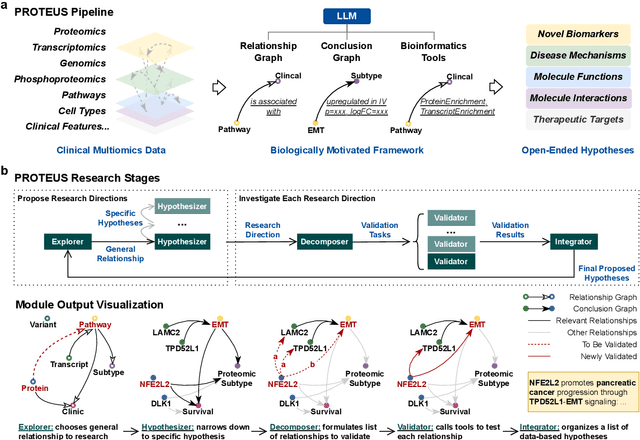
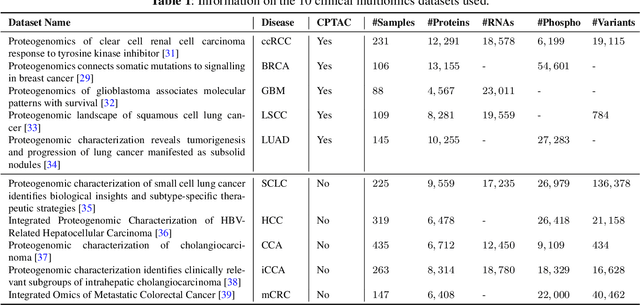
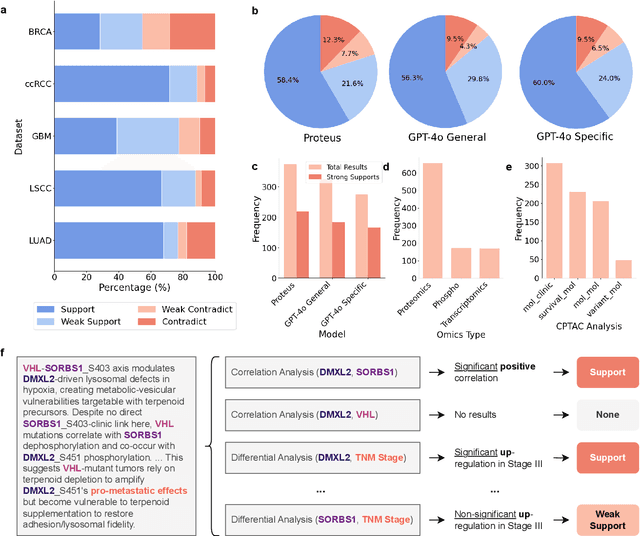

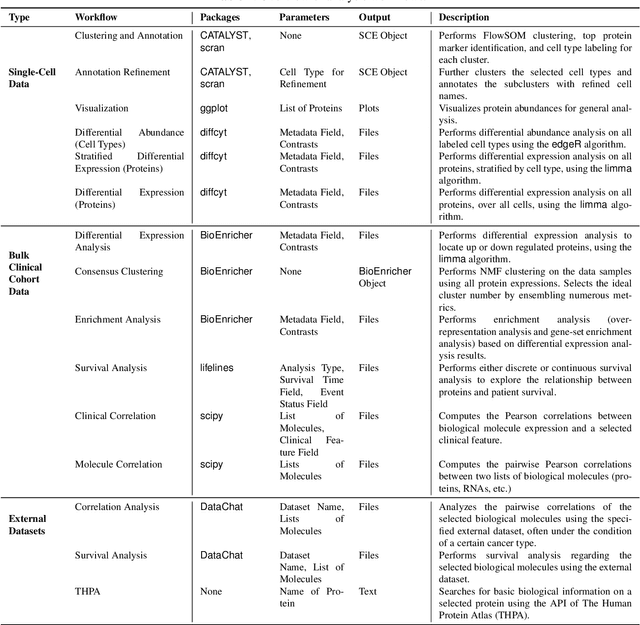
This paper introduces PROTEUS, a fully automated system that produces data-driven hypotheses from raw data files. We apply PROTEUS to clinical proteogenomics, a field where effective downstream data analysis and hypothesis proposal is crucial for producing novel discoveries. PROTEUS uses separate modules to simulate different stages of the scientific process, from open-ended data exploration to specific statistical analysis and hypothesis proposal. It formulates research directions, tools, and results in terms of relationships between biological entities, using unified graph structures to manage complex research processes. We applied PROTEUS to 10 clinical multiomics datasets from published research, arriving at 360 total hypotheses. Results were evaluated through external data validation and automatic open-ended scoring. Through exploratory and iterative research, the system can navigate high-throughput and heterogeneous multiomics data to arrive at hypotheses that balance reliability and novelty. In addition to accelerating multiomic analysis, PROTEUS represents a path towards tailoring general autonomous systems to specialized scientific domains to achieve open-ended hypothesis generation from data.
Automating Exploratory Proteomics Research via Language Models
Nov 06, 2024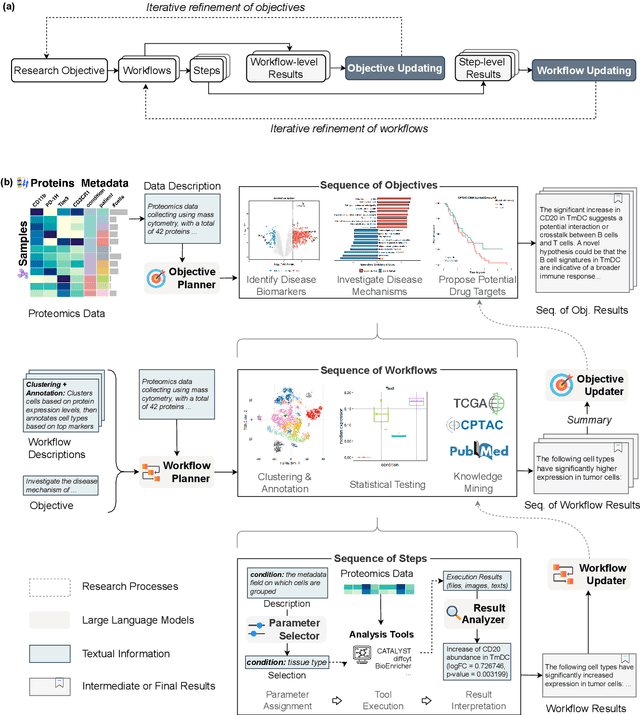
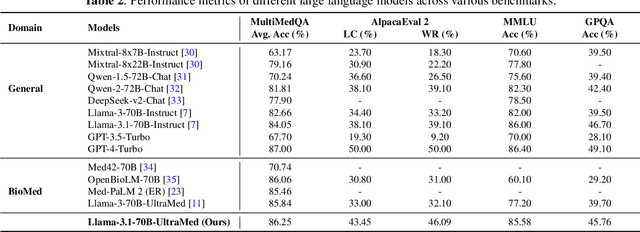
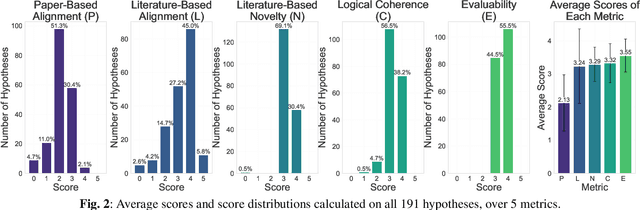
With the development of artificial intelligence, its contribution to science is evolving from simulating a complex problem to automating entire research processes and producing novel discoveries. Achieving this advancement requires both specialized general models grounded in real-world scientific data and iterative, exploratory frameworks that mirror human scientific methodologies. In this paper, we present PROTEUS, a fully automated system for scientific discovery from raw proteomics data. PROTEUS uses large language models (LLMs) to perform hierarchical planning, execute specialized bioinformatics tools, and iteratively refine analysis workflows to generate high-quality scientific hypotheses. The system takes proteomics datasets as input and produces a comprehensive set of research objectives, analysis results, and novel biological hypotheses without human intervention. We evaluated PROTEUS on 12 proteomics datasets collected from various biological samples (e.g. immune cells, tumors) and different sample types (single-cell and bulk), generating 191 scientific hypotheses. These were assessed using both automatic LLM-based scoring on 5 metrics and detailed reviews from human experts. Results demonstrate that PROTEUS consistently produces reliable, logically coherent results that align well with existing literature while also proposing novel, evaluable hypotheses. The system's flexible architecture facilitates seamless integration of diverse analysis tools and adaptation to different proteomics data types. By automating complex proteomics analysis workflows and hypothesis generation, PROTEUS has the potential to considerably accelerate the pace of scientific discovery in proteomics research, enabling researchers to efficiently explore large-scale datasets and uncover biological insights.
Differentiable architecture search with multi-dimensional attention for spiking neural networks
Nov 01, 2024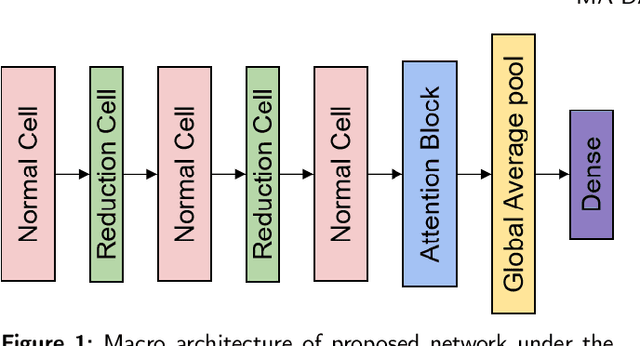
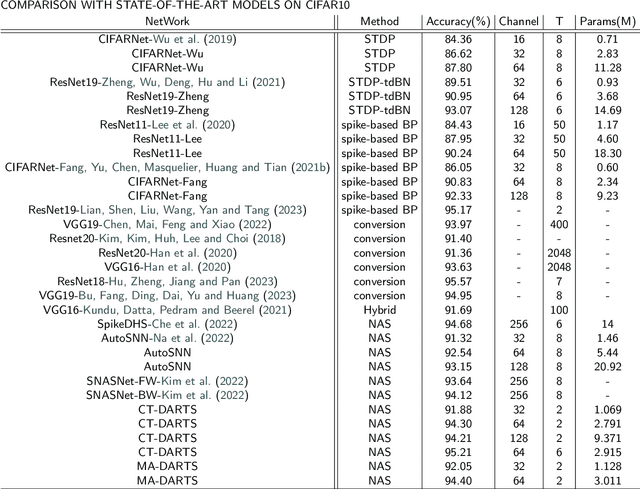
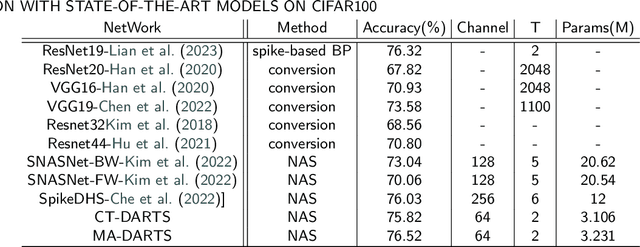
Spiking Neural Networks (SNNs) have gained enormous popularity in the field of artificial intelligence due to their low power consumption. However, the majority of SNN methods directly inherit the structure of Artificial Neural Networks (ANN), usually leading to sub-optimal model performance in SNNs. To alleviate this problem, we integrate Neural Architecture Search (NAS) method and propose Multi-Attention Differentiable Architecture Search (MA-DARTS) to directly automate the search for the optimal network structure of SNNs. Initially, we defined a differentiable two-level search space and conducted experiments within micro architecture under a fixed layer. Then, we incorporated a multi-dimensional attention mechanism and implemented the MA-DARTS algorithm in this search space. Comprehensive experiments demonstrate our model achieves state-of-the-art performance on classification compared to other methods under the same parameters with 94.40% accuracy on CIFAR10 dataset and 76.52% accuracy on CIFAR100 dataset. Additionally, we monitored and assessed the number of spikes (NoS) in each cell during the whole experiment. Notably, the number of spikes of the whole model stabilized at approximately 110K in validation and 100k in training on datasets.
Learning Semantic Segmentation of Large-Scale Point Clouds with Random Sampling
Jul 06, 2021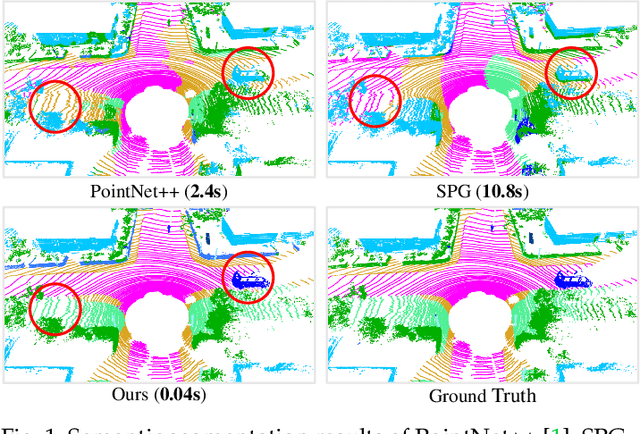
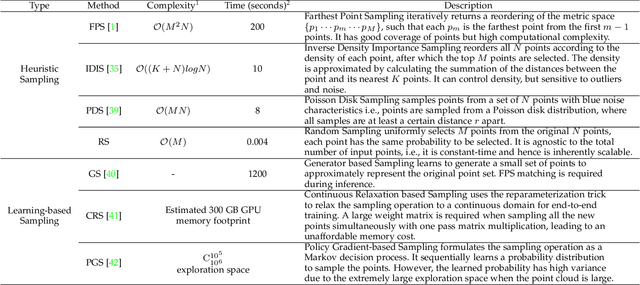
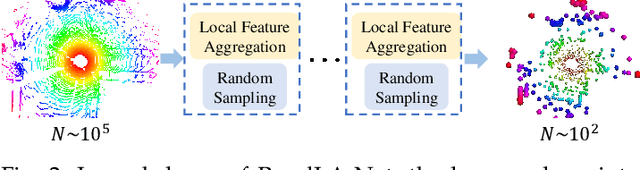
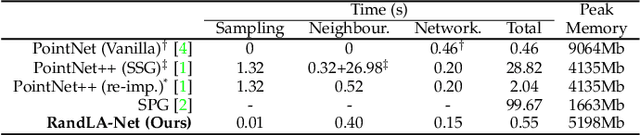
We study the problem of efficient semantic segmentation of large-scale 3D point clouds. By relying on expensive sampling techniques or computationally heavy pre/post-processing steps, most existing approaches are only able to be trained and operate over small-scale point clouds. In this paper, we introduce RandLA-Net, an efficient and lightweight neural architecture to directly infer per-point semantics for large-scale point clouds. The key to our approach is to use random point sampling instead of more complex point selection approaches. Although remarkably computation and memory efficient, random sampling can discard key features by chance. To overcome this, we introduce a novel local feature aggregation module to progressively increase the receptive field for each 3D point, thereby effectively preserving geometric details. Comparative experiments show that our RandLA-Net can process 1 million points in a single pass up to 200x faster than existing approaches. Moreover, extensive experiments on five large-scale point cloud datasets, including Semantic3D, SemanticKITTI, Toronto3D, NPM3D and S3DIS, demonstrate the state-of-the-art semantic segmentation performance of our RandLA-Net.
Watch and Learn: Mapping Language and Noisy Real-world Videos with Self-supervision
Nov 19, 2020
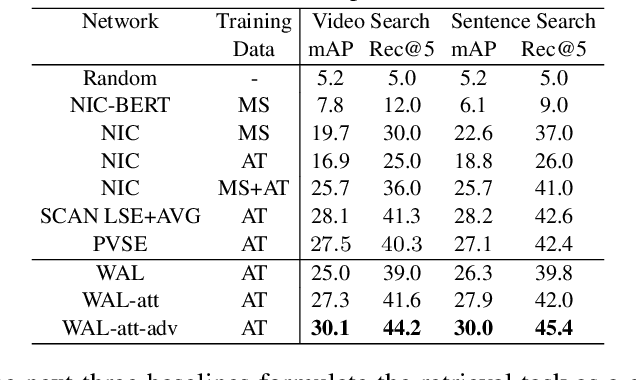
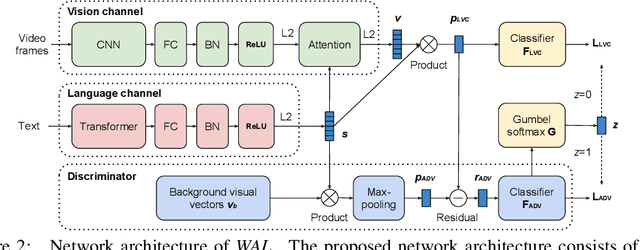
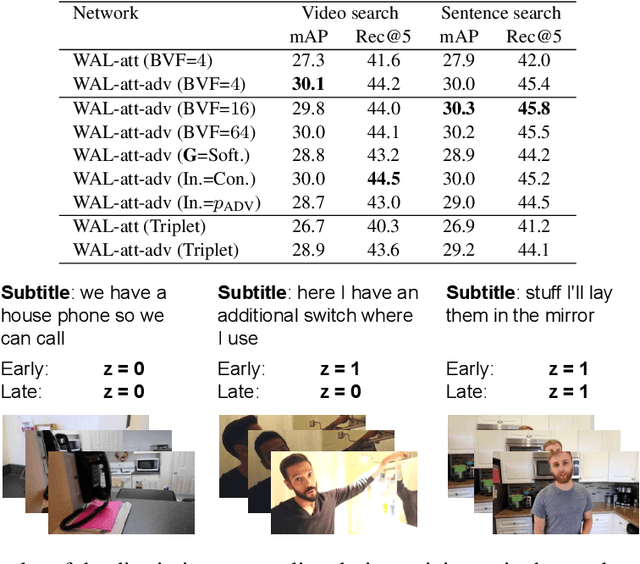
In this paper, we teach machines to understand visuals and natural language by learning the mapping between sentences and noisy video snippets without explicit annotations. Firstly, we define a self-supervised learning framework that captures the cross-modal information. A novel adversarial learning module is then introduced to explicitly handle the noises in the natural videos, where the subtitle sentences are not guaranteed to be strongly corresponded to the video snippets. For training and evaluation, we contribute a new dataset `ApartmenTour' that contains a large number of online videos and subtitles. We carry out experiments on the bidirectional retrieval tasks between sentences and videos, and the results demonstrate that our proposed model achieves the state-of-the-art performance on both retrieval tasks and exceeds several strong baselines. The dataset will be released soon.
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
Nov 25, 2019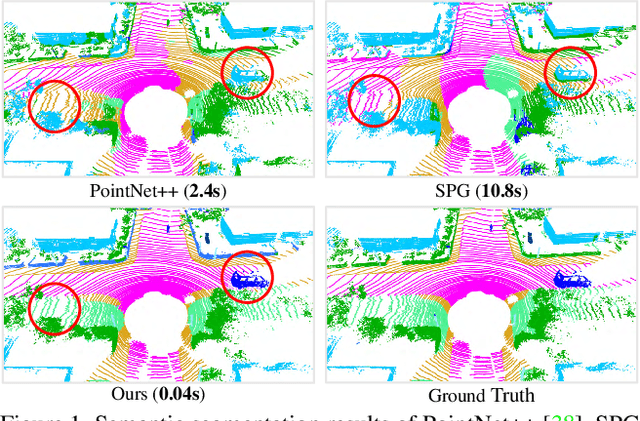
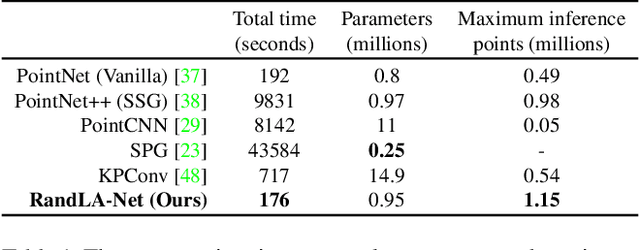
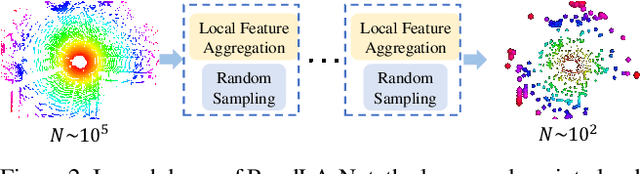
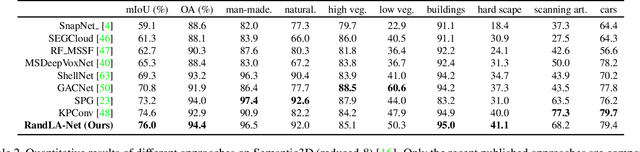
We study the problem of efficient semantic segmentation for large-scale 3D point clouds. By relying on expensive sampling techniques or computationally heavy pre/post-processing steps, most existing approaches are only able to be trained and operate over small-scale point clouds. In this paper, we introduce RandLA-Net, an efficient and lightweight neural architecture to directly infer per-point semantics for large-scale point clouds. The key to our approach is to use random point sampling instead of more complex point selection approaches. Although remarkably computation and memory efficient, random sampling can discard key features by chance. To overcome this, we introduce a novel local feature aggregation module to progressively increase the receptive field for each 3D point, thereby effectively preserving geometric details. Extensive experiments show that our RandLA-Net can process 1 million points in a single pass with up to 200X faster than existing approaches. Moreover, our RandLA-Net clearly surpasses state-of-the-art approaches for semantic segmentation on two large-scale benchmarks Semantic3D and SemanticKITTI.
Learning with Training Wheels: Speeding up Training with a Simple Controller for Deep Reinforcement Learning
Dec 12, 2018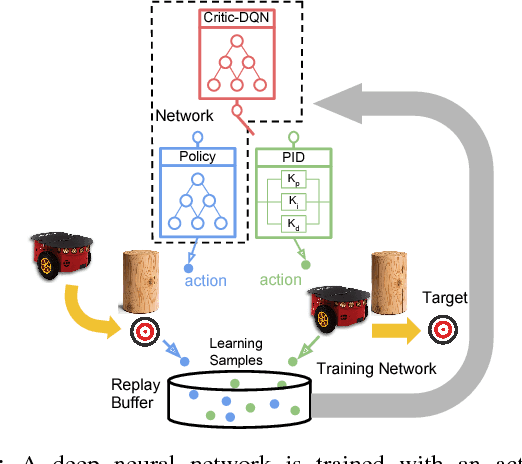
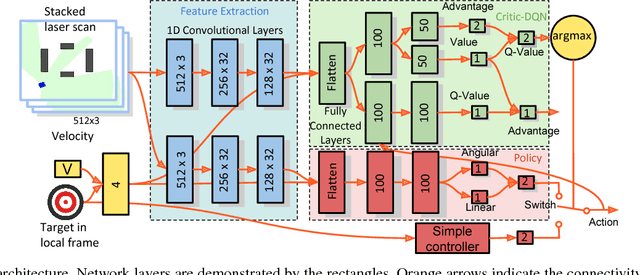
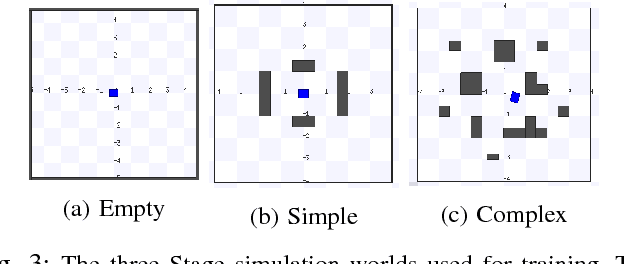
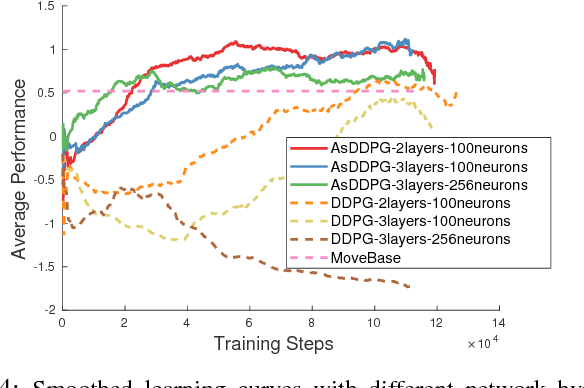
Deep Reinforcement Learning (DRL) has been applied successfully to many robotic applications. However, the large number of trials needed for training is a key issue. Most of existing techniques developed to improve training efficiency (e.g. imitation) target on general tasks rather than being tailored for robot applications, which have their specific context to benefit from. We propose a novel framework, Assisted Reinforcement Learning, where a classical controller (e.g. a PID controller) is used as an alternative, switchable policy to speed up training of DRL for local planning and navigation problems. The core idea is that the simple control law allows the robot to rapidly learn sensible primitives, like driving in a straight line, instead of random exploration. As the actor network becomes more advanced, it can then take over to perform more complex actions, like obstacle avoidance. Eventually, the simple controller can be discarded entirely. We show that not only does this technique train faster, it also is less sensitive to the structure of the DRL network and consistently outperforms a standard Deep Deterministic Policy Gradient network. We demonstrate the results in both simulation and real-world experiments.
Learning with Stochastic Guidance for Navigation
Nov 27, 2018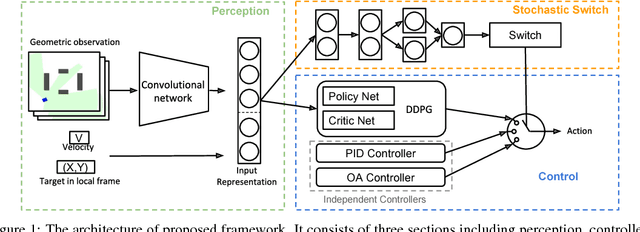
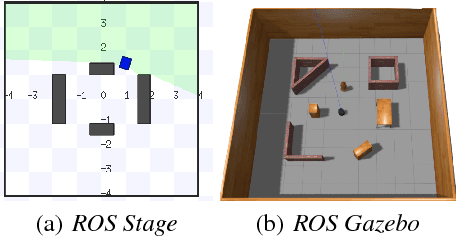
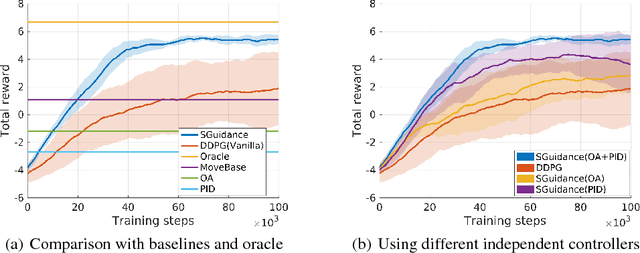
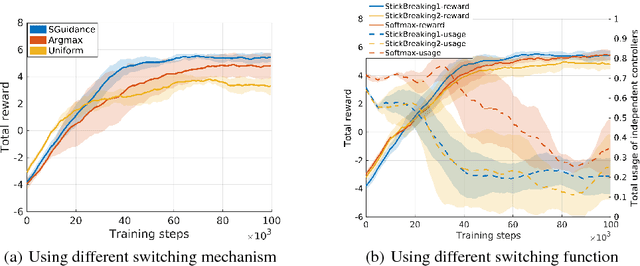
Due to the sparse rewards and high degree of environment variation, reinforcement learning approaches such as Deep Deterministic Policy Gradient (DDPG) are plagued by issues of high variance when applied in complex real world environments. We present a new framework for overcoming these issues by incorporating a stochastic switch, allowing an agent to choose between high and low variance policies. The stochastic switch can be jointly trained with the original DDPG in the same framework. In this paper, we demonstrate the power of the framework in a navigation task, where the robot can dynamically choose to learn through exploration, or to use the output of a heuristic controller as guidance. Instead of starting from completely random moves, the navigation capability of a robot can be quickly bootstrapped by several simple independent controllers. The experimental results show that with the aid of stochastic guidance we are able to effectively and efficiently train DDPG navigation policies and achieve significantly better performance than state-of-the-art baselines models.
Neural Allocentric Intuitive Physics Prediction from Real Videos
Sep 17, 2018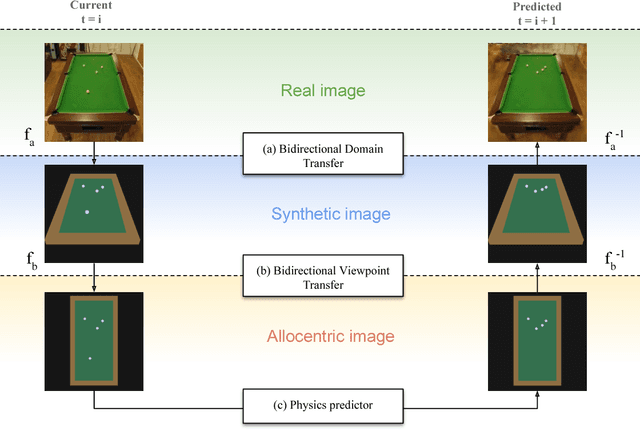

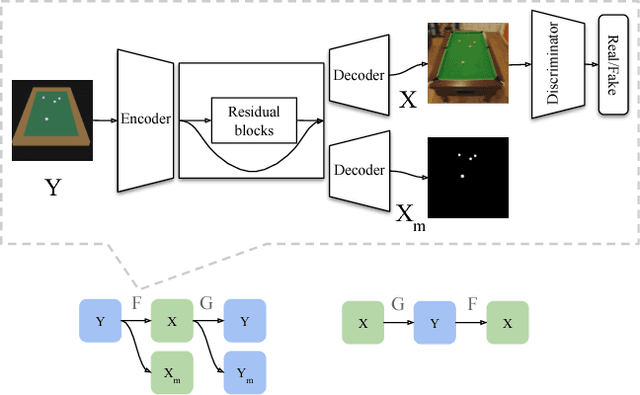
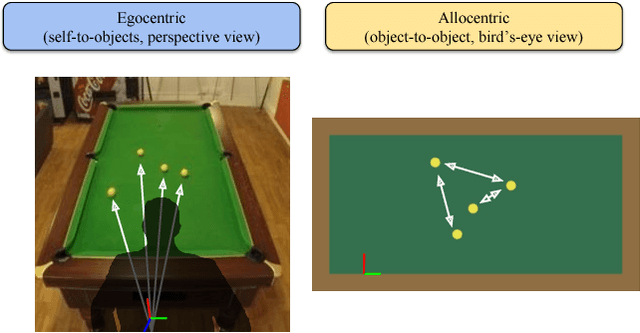
Humans are able to make rich predictions about the future dynamics of physical objects from a glance. On the other hand, most existing computer vision approaches require strong assumptions about the underlying system, ad-hoc modeling, or annotated datasets, to carry out even simple predictions. To tackle this gap, we propose a new perspective on the problem of learning intuitive physics that is inspired by the spatial memory representation of objects and spaces in human brains, in particular the co-existence of egocentric and allocentric spatial representations. We present a generic framework that learns a layered representation of the physical world, using a cascade of invertible modules. In this framework, real images are first converted to a synthetic domain representation that reduces complexity arising from lighting and texture. Then, an allocentric viewpoint transformer removes viewpoint complexity by projecting images to a canonical view. Finally, a novel Recurrent Latent Variation Network (RLVN) architecture learns the dynamics of the objects interacting with the environment and predicts future motion, leveraging the availability of unlimited synthetic simulations. Predicted frames are then projected back to the original camera view and translated back to the real world domain. Experimental results show the ability of the framework to consistently and accurately predict several frames in the future and the ability to adapt to real images.
Defo-Net: Learning Body Deformation using Generative Adversarial Networks
Apr 16, 2018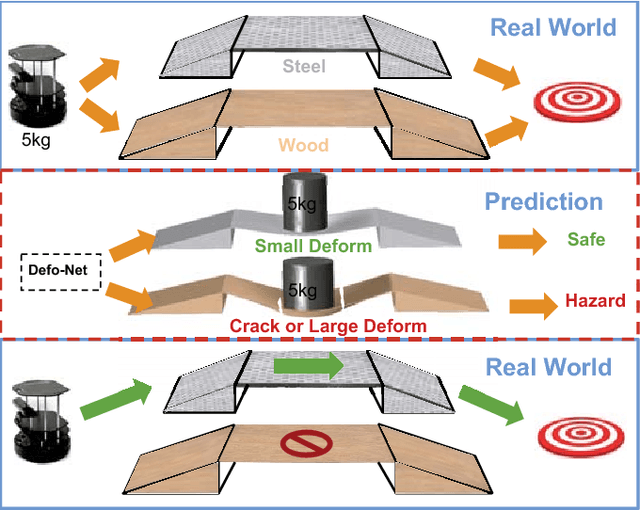
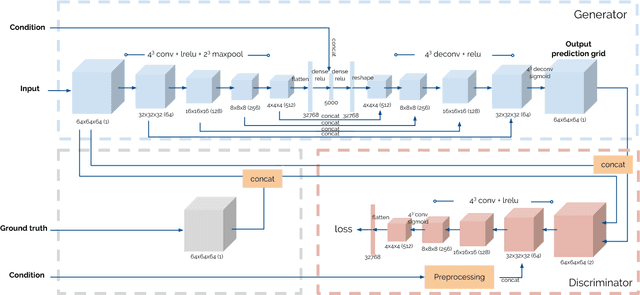
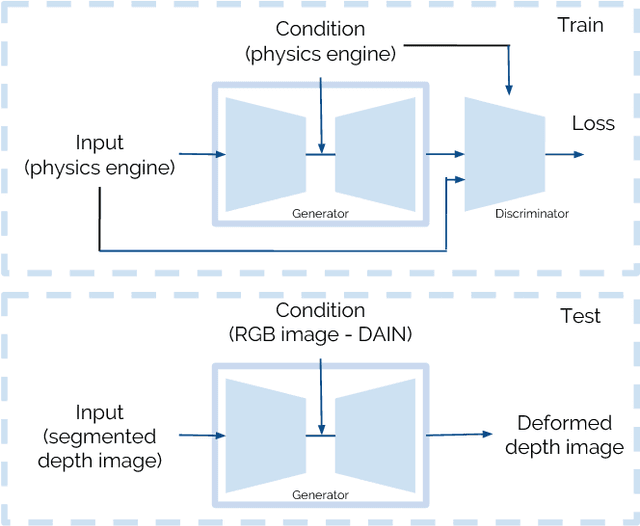

Modelling the physical properties of everyday objects is a fundamental prerequisite for autonomous robots. We present a novel generative adversarial network (Defo-Net), able to predict body deformations under external forces from a single RGB-D image. The network is based on an invertible conditional Generative Adversarial Network (IcGAN) and is trained on a collection of different objects of interest generated by a physical finite element model simulator. Defo-Net inherits the generalisation properties of GANs. This means that the network is able to reconstruct the whole 3-D appearance of the object given a single depth view of the object and to generalise to unseen object configurations. Contrary to traditional finite element methods, our approach is fast enough to be used in real-time applications. We apply the network to the problem of safe and fast navigation of mobile robots carrying payloads over different obstacles and floor materials. Experimental results in real scenarios show how a robot equipped with an RGB-D camera can use the network to predict terrain deformations under different payload configurations and use this to avoid unsafe areas.