 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Allocentric Intuitive Physics Prediction from Real Videos
Paper and Code
Sep 17, 2018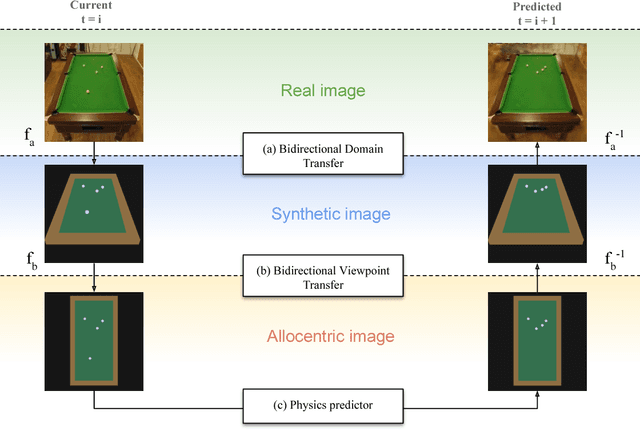

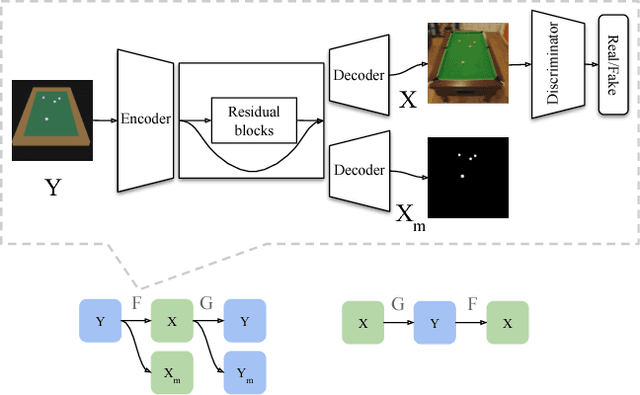
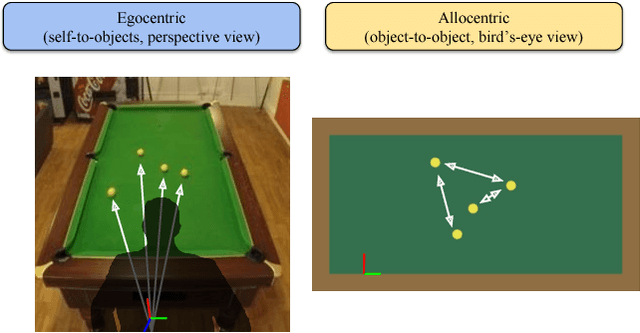
Humans are able to make rich predictions about the future dynamics of physical objects from a glance. On the other hand, most existing computer vision approaches require strong assumptions about the underlying system, ad-hoc modeling, or annotated datasets, to carry out even simple predictions. To tackle this gap, we propose a new perspective on the problem of learning intuitive physics that is inspired by the spatial memory representation of objects and spaces in human brains, in particular the co-existence of egocentric and allocentric spatial representations. We present a generic framework that learns a layered representation of the physical world, using a cascade of invertible modules. In this framework, real images are first converted to a synthetic domain representation that reduces complexity arising from lighting and texture. Then, an allocentric viewpoint transformer removes viewpoint complexity by projecting images to a canonical view. Finally, a novel Recurrent Latent Variation Network (RLVN) architecture learns the dynamics of the objects interacting with the environment and predicts future motion, leveraging the availability of unlimited synthetic simulations. Predicted frames are then projected back to the original camera view and translated back to the real world domain. Experimental results show the ability of the framework to consistently and accurately predict several frames in the future and the ability to adapt to real images.