 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildDepth: A Multimodal Dataset for 3D Wildlife Perception and Depth Estimation
Mar 17, 2026Depth estimation and 3D reconstruction have been extensively studied as core topics in computer vision. Starting from rigid objects with relatively simple geometric shapes, such as vehicles, the research has expanded to address general objects, including challenging deformable objects, such as humans and animals. However, for the animal, in particular, the majority of existing models are trained based on datasets without metric scale, which can help validate image-only models. To address this limitation, we present WildDepth, a multimodal dataset and benchmark suite for depth estimation, behavior detection, and 3D reconstruction from diverse categories of animals ranging from domestic to wild environments with synchronized RGB and LiDAR. Experimental results show that the use of multi-modal data improves depth reliability by up to 10% RMSE, while RGB-LiDAR fusion enhances 3D reconstruction fidelity by 12% in Chamfer distance. By releasing WildDepth and its benchmarks, we aim to foster robust multimodal perception systems that generalize across domains.
CycleVLA: Proactive Self-Correcting Vision-Language-Action Models via Subtask Backtracking and Minimum Bayes Risk Decoding
Jan 05, 2026Current work on robot failure detection and correction typically operate in a post hoc manner, analyzing errors and applying corrections only after failures occur. This work introduces CycleVLA, a system that equips Vision-Language-Action models (VLAs) with proactive self-correction, the capability to anticipate incipient failures and recover before they fully manifest during execution. CycleVLA achieves this by integrating a progress-aware VLA that flags critical subtask transition points where failures most frequently occur, a VLM-based failure predictor and planner that triggers subtask backtracking upon predicted failure, and a test-time scaling strategy based on Minimum Bayes Risk (MBR) decoding to improve retry success after backtracking. Extensive experiments show that CycleVLA improves performance for both well-trained and under-trained VLAs, and that MBR serves as an effective zero-shot test-time scaling strategy for VLAs. Project Page: https://dannymcy.github.io/cyclevla/
Efficient and Microphone-Fault-Tolerant 3D Sound Source Localization
May 27, 2025Sound source localization (SSL) is a critical technology for determining the position of sound sources in complex environments. However, existing methods face challenges such as high computational costs and precise calibration requirements, limiting their deployment in dynamic or resource-constrained environments. This paper introduces a novel 3D SSL framework, which uses sparse cross-attention, pretraining, and adaptive signal coherence metrics, to achieve accurate and computationally efficient localization with fewer input microphones. The framework is also fault-tolerant to unreliable or even unknown microphone position inputs, ensuring its applicability in real-world scenarios. Preliminary experiments demonstrate its scalability for multi-source localization without requiring additional hardware. This work advances SSL by balancing the model's performance and efficiency and improving its robustness for real-world scenarios.
Target Speaker Extraction through Comparing Noisy Positive and Negative Audio Enrollments
Feb 23, 2025Target speaker extraction focuses on isolating a specific speaker's voice from an audio mixture containing multiple speakers. To provide information about the target speaker's identity, prior works have utilized clean audio examples as conditioning inputs. However, such clean audio examples are not always readily available (e.g. It is impractical to obtain a clean audio example of a stranger's voice at a cocktail party without stepping away from the noisy environment). Limited prior research has explored extracting the target speaker's characteristics from noisy audio examples, which may include overlapping speech from disturbing speakers. In this work, we focus on target speaker extraction when multiple speakers are present during the enrollment stage, through leveraging differences between audio segments where the target speakers are speaking (Positive Enrollments) and segments where they are not (Negative Enrollments). Experiments show the effectiveness of our model architecture and the dedicated pretraining method for the proposed task. Our method achieves state-of-the-art performance in the proposed application settings and demonstrates strong generalizability across challenging and realistic scenarios.
SoundLoc3D: Invisible 3D Sound Source Localization and Classification Using a Multimodal RGB-D Acoustic Camera
Dec 22, 2024Accurately localizing 3D sound sources and estimating their semantic labels -- where the sources may not be visible, but are assumed to lie on the physical surface of objects in the scene -- have many real applications, including detecting gas leak and machinery malfunction. The audio-visual weak-correlation in such setting poses new challenges in deriving innovative methods to answer if or how we can use cross-modal information to solve the task. Towards this end, we propose to use an acoustic-camera rig consisting of a pinhole RGB-D camera and a coplanar four-channel microphone array~(Mic-Array). By using this rig to record audio-visual signals from multiviews, we can use the cross-modal cues to estimate the sound sources 3D locations. Specifically, our framework SoundLoc3D treats the task as a set prediction problem, each element in the set corresponds to a potential sound source. Given the audio-visual weak-correlation, the set representation is initially learned from a single view microphone array signal, and then refined by actively incorporating physical surface cues revealed from multiview RGB-D images. We demonstrate the efficiency and superiority of SoundLoc3D on large-scale simulated dataset, and further show its robustness to RGB-D measurement inaccuracy and ambient noise interference.
* Accepted by WACV2025
RiTTA: Modeling Event Relations in Text-to-Audio Generation
Dec 20, 2024
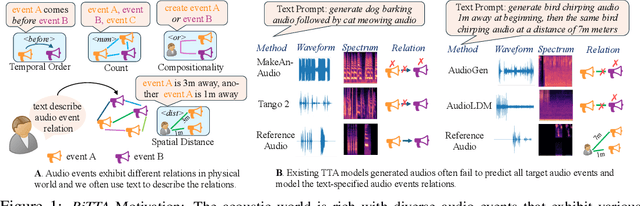
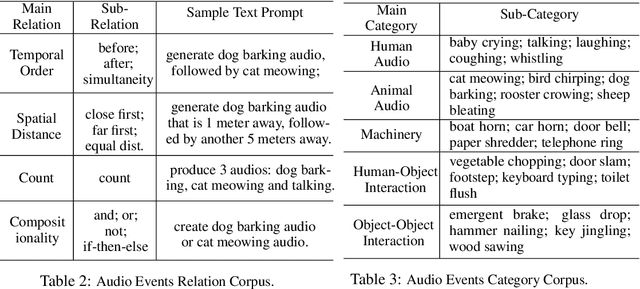
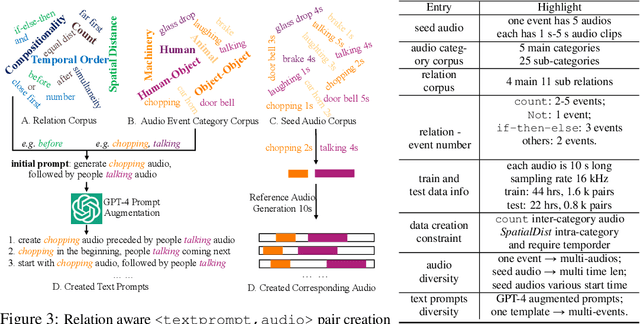
Despite significant advancements in Text-to-Audio (TTA) generation models achieving high-fidelity audio with fine-grained context understanding, they struggle to model the relations between audio events described in the input text. However, previous TTA methods have not systematically explored audio event relation modeling, nor have they proposed frameworks to enhance this capability. In this work, we systematically study audio event relation modeling in TTA generation models. We first establish a benchmark for this task by: 1. proposing a comprehensive relation corpus covering all potential relations in real-world scenarios; 2. introducing a new audio event corpus encompassing commonly heard audios; and 3. proposing new evaluation metrics to assess audio event relation modeling from various perspectives. Furthermore, we propose a finetuning framework to enhance existing TTA models ability to model audio events relation. Code is available at: https://github.com/yuhanghe01/RiTTA
HyperspectralViTs: General Hyperspectral Models for On-board Remote Sensing
Oct 24, 2024


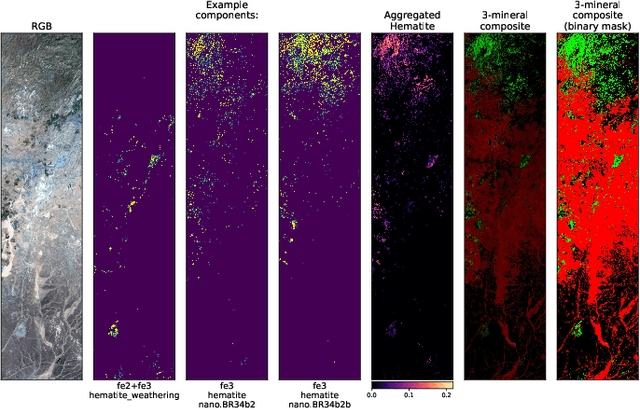
On-board processing of hyperspectral data with machine learning models would enable unprecedented amount of autonomy for a wide range of tasks, for example methane detection or mineral identification. This can enable early warning system and could allow new capabilities such as automated scheduling across constellations of satellites. Classical methods suffer from high false positive rates and previous deep learning models exhibit prohibitive computational requirements. We propose fast and accurate machine learning architectures which support end-to-end training with data of high spectral dimension without relying on hand-crafted products or spectral band compression preprocessing. We evaluate our models on two tasks related to hyperspectral data processing. With our proposed general architectures, we improve the F1 score of the previous methane detection state-of-the-art models by 27% on a newly created synthetic dataset and by 13% on the previously released large benchmark dataset. We also demonstrate that training models on the synthetic dataset improves performance of models finetuned on the dataset of real events by 6.9% in F1 score in contrast with training from scratch. On a newly created dataset for mineral identification, our models provide 3.5% improvement in the F1 score in contrast to the default versions of the models. With our proposed models we improve the inference speed by 85% in contrast to previous classical and deep learning approaches by removing the dependency on classically computed features. With our architecture, one capture from the EMIT sensor can be processed within 30 seconds on realistic proxy of the ION-SCV 004 satellite.
Towards Multi-Modal Animal Pose Estimation: An In-Depth Analysis
Oct 12, 2024



Animal pose estimation (APE) aims to locate the animal body parts using a diverse array of sensor and modality inputs, which is crucial for research across neuroscience, biomechanics, and veterinary medicine. By evaluating 178 papers since 2013, APE methods are categorised by sensor and modality types, learning paradigms, experimental setup, and application domains, presenting detailed analyses of current trends, challenges, and future directions in single- and multi-modality APE systems. The analysis also highlights the transition between human and animal pose estimation. Additionally, 2D and 3D APE datasets and evaluation metrics based on different sensors and modalities are provided. A regularly updated project page is provided here: https://github.com/ChennyDeng/MM-APE.
MambaLoc: Efficient Camera Localisation via State Space Model
Aug 20, 2024



Location information is pivotal for the automation and intelligence of terminal devices and edge-cloud IoT systems, such as autonomous vehicles and augmented reality. However, achieving reliable positioning across diverse IoT applications remains challenging due to significant training costs and the necessity of densely collected data. To tackle these issues, we have innovatively applied the selective state space (SSM) model to visual localization, introducing a new model named MambaLoc. The proposed model demonstrates exceptional training efficiency by capitalizing on the SSM model's strengths in efficient feature extraction, rapid computation, and memory optimization, and it further ensures robustness in sparse data environments due to its parameter sparsity. Additionally, we propose the Global Information Selector (GIS), which leverages selective SSM to implicitly achieve the efficient global feature extraction capabilities of Non-local Neural Networks. This design leverages the computational efficiency of the SSM model alongside the Non-local Neural Networks' capacity to capture long-range dependencies with minimal layers. Consequently, the GIS enables effective global information capture while significantly accelerating convergence. Our extensive experimental validation using public indoor and outdoor datasets first demonstrates our model's effectiveness, followed by evidence of its versatility with various existing localization models. Our code and models are publicly available to support further research and development in this area.
SPEAR: Receiver-to-Receiver Acoustic Neural Warping Field
Jun 16, 2024



We present SPEAR, a continuous receiver-to-receiver acoustic neural warping field for spatial acoustic effects prediction in an acoustic 3D space with a single stationary audio source. Unlike traditional source-to-receiver modelling methods that require prior space acoustic properties knowledge to rigorously model audio propagation from source to receiver, we propose to predict by warping the spatial acoustic effects from one reference receiver position to another target receiver position, so that the warped audio essentially accommodates all spatial acoustic effects belonging to the target position. SPEAR can be trained in a data much more readily accessible manner, in which we simply ask two robots to independently record spatial audio at different positions. We further theoretically prove the universal existence of the warping field if and only if one audio source presents. Three physical principles are incorporated to guide SPEAR network design, leading to the learned warping field physically meaningful. We demonstrate SPEAR superiority on both synthetic, photo-realistic and real-world dataset, showing the huge potential of SPEAR to various down-stream robotic tasks.