 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Red Queen: Adversarial Program Evolution in Core War with LLMs
Jan 06, 2026Large language models (LLMs) are increasingly being used to evolve solutions to problems in many domains, in a process inspired by biological evolution. However, unlike biological evolution, most LLM-evolution frameworks are formulated as static optimization problems, overlooking the open-ended adversarial dynamics that characterize real-world evolutionary processes. Here, we study Digital Red Queen (DRQ), a simple self-play algorithm that embraces these so-called "Red Queen" dynamics via continual adaptation to a changing objective. DRQ uses an LLM to evolve assembly-like programs, called warriors, which compete against each other for control of a virtual machine in the game of Core War, a Turing-complete environment studied in artificial life and connected to cybersecurity. In each round of DRQ, the model evolves a new warrior to defeat all previous ones, producing a sequence of adapted warriors. Over many rounds, we observe that warriors become increasingly general (relative to a set of held-out human warriors). Interestingly, warriors also become less behaviorally diverse across independent runs, indicating a convergence pressure toward a general-purpose behavioral strategy, much like convergent evolution in nature. This result highlights a potential value of shifting from static objectives to dynamic Red Queen objectives. Our work positions Core War as a rich, controllable sandbox for studying adversarial adaptation in artificial systems and for evaluating LLM-based evolution methods. More broadly, the simplicity and effectiveness of DRQ suggest that similarly minimal self-play approaches could prove useful in other more practical multi-agent adversarial domains, like real-world cybersecurity or combating drug resistance.
MARBLE: Material Recomposition and Blending in CLIP-Space
Jun 05, 2025



Editing materials of objects in images based on exemplar images is an active area of research in computer vision and graphics. We propose MARBLE, a method for performing material blending and recomposing fine-grained material properties by finding material embeddings in CLIP-space and using that to control pre-trained text-to-image models. We improve exemplar-based material editing by finding a block in the denoising UNet responsible for material attribution. Given two material exemplar-images, we find directions in the CLIP-space for blending the materials. Further, we can achieve parametric control over fine-grained material attributes such as roughness, metallic, transparency, and glow using a shallow network to predict the direction for the desired material attribute change. We perform qualitative and quantitative analysis to demonstrate the efficacy of our proposed method. We also present the ability of our method to perform multiple edits in a single forward pass and applicability to painting. Project Page: https://marblecontrol.github.io/
ZeST: Zero-Shot Material Transfer from a Single Image
Apr 09, 2024We propose ZeST, a method for zero-shot material transfer to an object in the input image given a material exemplar image. ZeST leverages existing diffusion adapters to extract implicit material representation from the exemplar image. This representation is used to transfer the material using pre-trained inpainting diffusion model on the object in the input image using depth estimates as geometry cue and grayscale object shading as illumination cues. The method works on real images without any training resulting a zero-shot approach. Both qualitative and quantitative results on real and synthetic datasets demonstrate that ZeST outputs photorealistic images with transferred materials. We also show the application of ZeST to perform multiple edits and robust material assignment under different illuminations. Project Page: https://ttchengab.github.io/zest
Alchemist: Parametric Control of Material Properties with Diffusion Models
Dec 05, 2023
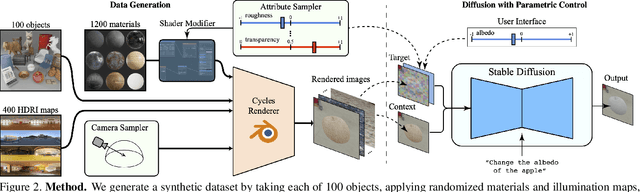


We propose a method to control material attributes of objects like roughness, metallic, albedo, and transparency in real images. Our method capitalizes on the generative prior of text-to-image models known for photorealism, employing a scalar value and instructions to alter low-level material properties. Addressing the lack of datasets with controlled material attributes, we generated an object-centric synthetic dataset with physically-based materials. Fine-tuning a modified pre-trained text-to-image model on this synthetic dataset enables us to edit material properties in real-world images while preserving all other attributes. We show the potential application of our model to material edited NeRFs.
Materialistic: Selecting Similar Materials in Images
May 22, 2023Separating an image into meaningful underlying components is a crucial first step for both editing and understanding images. We present a method capable of selecting the regions of a photograph exhibiting the same material as an artist-chosen area. Our proposed approach is robust to shading, specular highlights, and cast shadows, enabling selection in real images. As we do not rely on semantic segmentation (different woods or metal should not be selected together), we formulate the problem as a similarity-based grouping problem based on a user-provided image location. In particular, we propose to leverage the unsupervised DINO features coupled with a proposed Cross-Similarity module and an MLP head to extract material similarities in an image. We train our model on a new synthetic image dataset, that we release. We show that our method generalizes well to real-world images. We carefully analyze our model's behavior on varying material properties and lighting. Additionally, we evaluate it against a hand-annotated benchmark of 50 real photographs. We further demonstrate our model on a set of applications, including material editing, in-video selection, and retrieval of object photographs with similar materials.
SAR-to-EO Image Translation with Multi-Conditional Adversarial Networks
Jul 26, 2022



This paper explores the use of multi-conditional adversarial networks for SAR-to-EO image translation. Previous methods condition adversarial networks only on the input SAR. We show that incorporating multiple complementary modalities such as Google maps and IR can further improve SAR-to-EO image translation especially on preserving sharp edges of manmade objects. We demonstrate effectiveness of our approach on a diverse set of datasets including SEN12MS, DFC2020, and SpaceNet6. Our experimental results suggest that additional information provided by complementary modalities improves the performance of SAR-to-EO image translation compared to the models trained on paired SAR and EO data only. To best of our knowledge, our approach is the first to leverage multiple modalities for improving SAR-to-EO image translation performance.
Seeing 3D Objects in a Single Image via Self-Supervised Static-Dynamic Disentanglement
Jul 22, 2022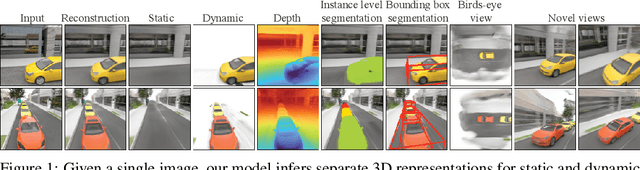
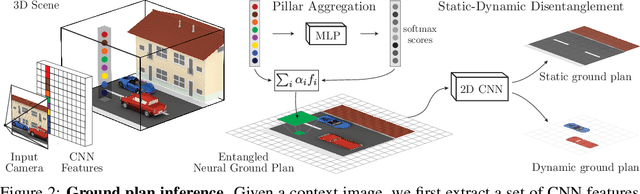
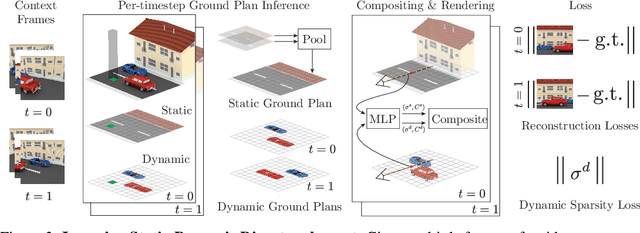
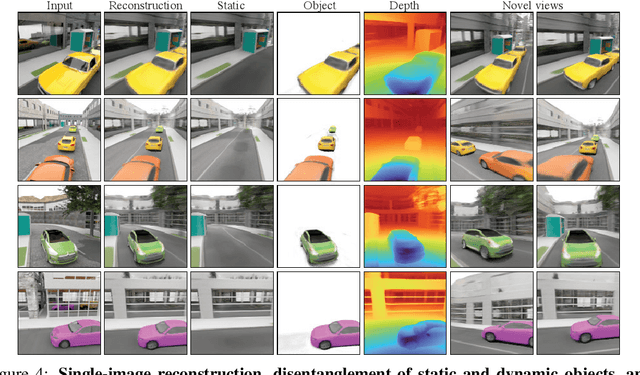
Human perception reliably identifies movable and immovable parts of 3D scenes, and completes the 3D structure of objects and background from incomplete observations. We learn this skill not via labeled examples, but simply by observing objects move. In this work, we propose an approach that observes unlabeled multi-view videos at training time and learns to map a single image observation of a complex scene, such as a street with cars, to a 3D neural scene representation that is disentangled into movable and immovable parts while plausibly completing its 3D structure. We separately parameterize movable and immovable scene parts via 2D neural ground plans. These ground plans are 2D grids of features aligned with the ground plane that can be locally decoded into 3D neural radiance fields. Our model is trained self-supervised via neural rendering. We demonstrate that the structure inherent to our disentangled 3D representation enables a variety of downstream tasks in street-scale 3D scenes using simple heuristics, such as extraction of object-centric 3D representations, novel view synthesis, instance segmentation, and 3D bounding box prediction, highlighting its value as a backbone for data-efficient 3D scene understanding models. This disentanglement further enables scene editing via object manipulation such as deletion, insertion, and rigid-body motion.
What You Can Learn by Staring at a Blank Wall
Aug 30, 2021



We present a passive non-line-of-sight method that infers the number of people or activity of a person from the observation of a blank wall in an unknown room. Our technique analyzes complex imperceptible changes in indirect illumination in a video of the wall to reveal a signal that is correlated with motion in the hidden part of a scene. We use this signal to classify between zero, one, or two moving people, or the activity of a person in the hidden scene. We train two convolutional neural networks using data collected from 20 different scenes, and achieve an accuracy of $\approx94\%$ for both tasks in unseen test environments and real-time online settings. Unlike other passive non-line-of-sight methods, the technique does not rely on known occluders or controllable light sources, and generalizes to unknown rooms with no re-calibration. We analyze the generalization and robustness of our method with both real and synthetic data, and study the effect of the scene parameters on the signal quality.
Computational Mirrors: Blind Inverse Light Transport by Deep Matrix Factorization
Dec 05, 2019

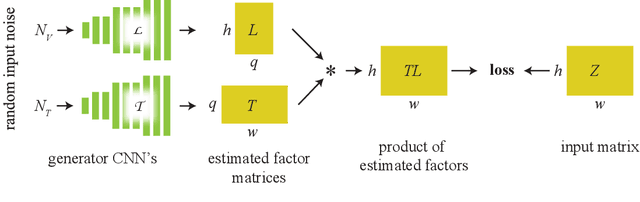

We recover a video of the motion taking place in a hidden scene by observing changes in indirect illumination in a nearby uncalibrated visible region. We solve this problem by factoring the observed video into a matrix product between the unknown hidden scene video and an unknown light transport matrix. This task is extremely ill-posed, as any non-negative factorization will satisfy the data. Inspired by recent work on the Deep Image Prior, we parameterize the factor matrices using randomly initialized convolutional neural networks trained in a one-off manner, and show that this results in decompositions that reflect the true motion in the hidden scene.
* 14 pages, 5 figures, Advances in Neural Information Processing Systems 2019