 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochasticSplats: Stochastic Rasterization for Sorting-Free 3D Gaussian Splatting
Mar 31, 20253D Gaussian splatting (3DGS) is a popular radiance field method, with many application-specific extensions. Most variants rely on the same core algorithm: depth-sorting of Gaussian splats then rasterizing in primitive order. This ensures correct alpha compositing, but can cause rendering artifacts due to built-in approximations. Moreover, for a fixed representation, sorted rendering offers little control over render cost and visual fidelity. For example, and counter-intuitively, rendering a lower-resolution image is not necessarily faster. In this work, we address the above limitations by combining 3D Gaussian splatting with stochastic rasterization. Concretely, we leverage an unbiased Monte Carlo estimator of the volume rendering equation. This removes the need for sorting, and allows for accurate 3D blending of overlapping Gaussians. The number of Monte Carlo samples further imbues 3DGS with a way to trade off computation time and quality. We implement our method using OpenGL shaders, enabling efficient rendering on modern GPU hardware. At a reasonable visual quality, our method renders more than four times faster than sorted rasterization.
RoMo: Robust Motion Segmentation Improves Structure from Motion
Nov 27, 2024
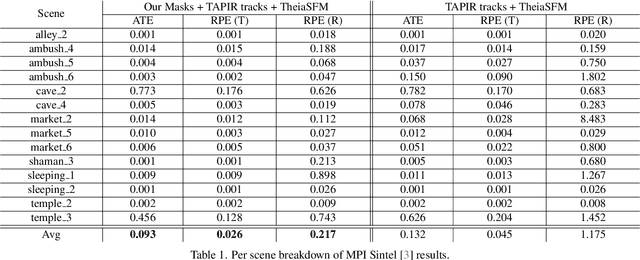


There has been extensive progress in the reconstruction and generation of 4D scenes from monocular casually-captured video. While these tasks rely heavily on known camera poses, the problem of finding such poses using structure-from-motion (SfM) often depends on robustly separating static from dynamic parts of a video. The lack of a robust solution to this problem limits the performance of SfM camera-calibration pipelines. We propose a novel approach to video-based motion segmentation to identify the components of a scene that are moving w.r.t. a fixed world frame. Our simple but effective iterative method, RoMo, combines optical flow and epipolar cues with a pre-trained video segmentation model. It outperforms unsupervised baselines for motion segmentation as well as supervised baselines trained from synthetic data. More importantly, the combination of an off-the-shelf SfM pipeline with our segmentation masks establishes a new state-of-the-art on camera calibration for scenes with dynamic content, outperforming existing methods by a substantial margin.
SpotlessSplats: Ignoring Distractors in 3D Gaussian Splatting
Jun 28, 2024
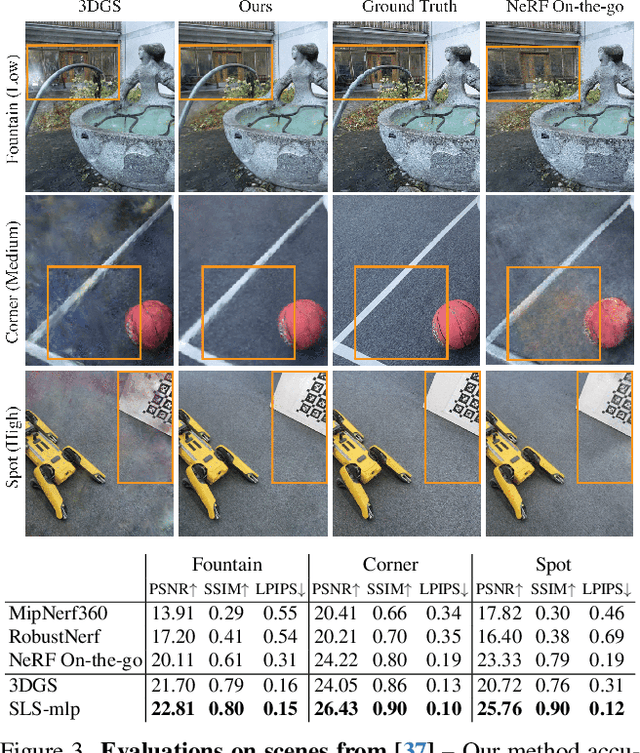

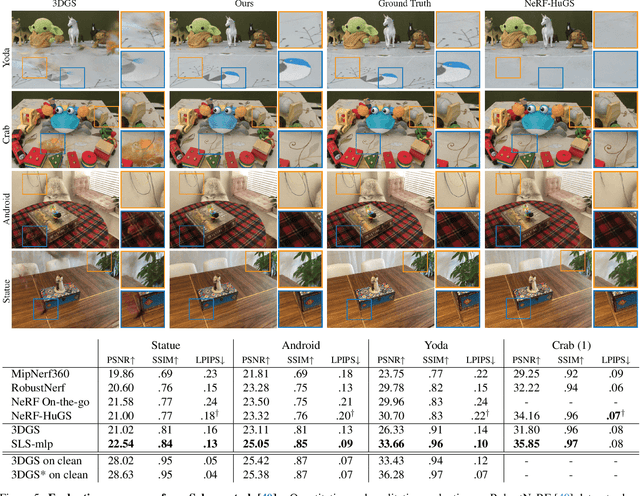
3D Gaussian Splatting (3DGS) is a promising technique for 3D reconstruction, offering efficient training and rendering speeds, making it suitable for real-time applications.However, current methods require highly controlled environments (no moving people or wind-blown elements, and consistent lighting) to meet the inter-view consistency assumption of 3DGS. This makes reconstruction of real-world captures problematic. We present SpotlessSplats, an approach that leverages pre-trained and general-purpose features coupled with robust optimization to effectively ignore transient distractors. Our method achieves state-of-the-art reconstruction quality both visually and quantitatively, on casual captures.
MagicMirror: Fast and High-Quality Avatar Generation with a Constrained Search Space
Apr 01, 2024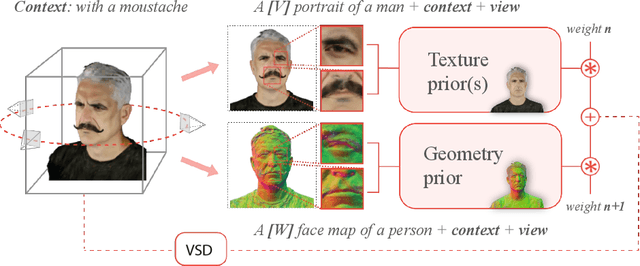



We introduce a novel framework for 3D human avatar generation and personalization, leveraging text prompts to enhance user engagement and customization. Central to our approach are key innovations aimed at overcoming the challenges in photo-realistic avatar synthesis. Firstly, we utilize a conditional Neural Radiance Fields (NeRF) model, trained on a large-scale unannotated multi-view dataset, to create a versatile initial solution space that accelerates and diversifies avatar generation. Secondly, we develop a geometric prior, leveraging the capabilities of Text-to-Image Diffusion Models, to ensure superior view invariance and enable direct optimization of avatar geometry. These foundational ideas are complemented by our optimization pipeline built on Variational Score Distillation (VSD), which mitigates texture loss and over-saturation issues. As supported by our extensive experiments, these strategies collectively enable the creation of custom avatars with unparalleled visual quality and better adherence to input text prompts. You can find more results and videos in our website: https://syntec-research.github.io/MagicMirror
Alchemist: Parametric Control of Material Properties with Diffusion Models
Dec 05, 2023
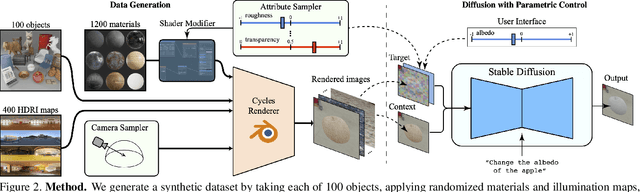


We propose a method to control material attributes of objects like roughness, metallic, albedo, and transparency in real images. Our method capitalizes on the generative prior of text-to-image models known for photorealism, employing a scalar value and instructions to alter low-level material properties. Addressing the lack of datasets with controlled material attributes, we generated an object-centric synthetic dataset with physically-based materials. Fine-tuning a modified pre-trained text-to-image model on this synthetic dataset enables us to edit material properties in real-world images while preserving all other attributes. We show the potential application of our model to material edited NeRFs.
MELON: NeRF with Unposed Images Using Equivalence Class Estimation
Mar 14, 2023Neural radiance fields enable novel-view synthesis and scene reconstruction with photorealistic quality from a few images, but require known and accurate camera poses. Conventional pose estimation algorithms fail on smooth or self-similar scenes, while methods performing inverse rendering from unposed views require a rough initialization of the camera orientations. The main difficulty of pose estimation lies in real-life objects being almost invariant under certain transformations, making the photometric distance between rendered views non-convex with respect to the camera parameters. Using an equivalence relation that matches the distribution of local minima in camera space, we reduce this space to its quotient set, in which pose estimation becomes a more convex problem. Using a neural-network to regularize pose estimation, we demonstrate that our method - MELON - can reconstruct a neural radiance field from unposed images with state-of-the-art accuracy while requiring ten times fewer views than adversarial approaches.
CUF: Continuous Upsampling Filters
Oct 20, 2022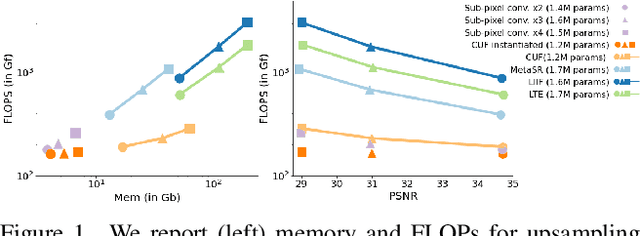


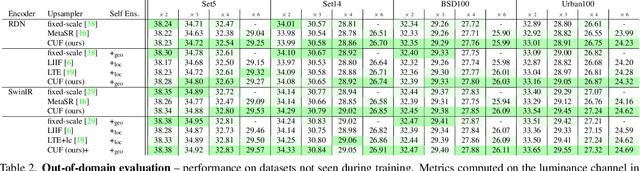
Neural fields have rapidly been adopted for representing 3D signals, but their application to more classical 2D image-processing has been relatively limited. In this paper, we consider one of the most important operations in image processing: upsampling. In deep learning, learnable upsampling layers have extensively been used for single image super-resolution. We propose to parameterize upsampling kernels as neural fields. This parameterization leads to a compact architecture that obtains a 40-fold reduction in the number of parameters when compared with competing arbitrary-scale super-resolution architectures. When upsampling images of size 256x256 we show that our architecture is 2x-10x more efficient than competing arbitrary-scale super-resolution architectures, and more efficient than sub-pixel convolutions when instantiated to a single-scale model. In the general setting, these gains grow polynomially with the square of the target scale. We validate our method on standard benchmarks showing such efficiency gains can be achieved without sacrifices in super-resolution performance.
LOLNeRF: Learn from One Look
Nov 19, 2021


We present a method for learning a generative 3D model based on neural radiance fields, trained solely from data with only single views of each object. While generating realistic images is no longer a difficult task, producing the corresponding 3D structure such that they can be rendered from different views is non-trivial. We show that, unlike existing methods, one does not need multi-view data to achieve this goal. Specifically, we show that by reconstructing many images aligned to an approximate canonical pose with a single network conditioned on a shared latent space, you can learn a space of radiance fields that models shape and appearance for a class of objects. We demonstrate this by training models to reconstruct object categories using datasets that contain only one view of each subject without depth or geometry information. Our experiments show that we achieve state-of-the-art results in novel view synthesis and competitive results for monocular depth prediction.