 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMELON: NeRF with Unposed Images Using Equivalence Class Estimation
Mar 14, 2023Neural radiance fields enable novel-view synthesis and scene reconstruction with photorealistic quality from a few images, but require known and accurate camera poses. Conventional pose estimation algorithms fail on smooth or self-similar scenes, while methods performing inverse rendering from unposed views require a rough initialization of the camera orientations. The main difficulty of pose estimation lies in real-life objects being almost invariant under certain transformations, making the photometric distance between rendered views non-convex with respect to the camera parameters. Using an equivalence relation that matches the distribution of local minima in camera space, we reduce this space to its quotient set, in which pose estimation becomes a more convex problem. Using a neural-network to regularize pose estimation, we demonstrate that our method - MELON - can reconstruct a neural radiance field from unposed images with state-of-the-art accuracy while requiring ten times fewer views than adversarial approaches.
Kubric: A scalable dataset generator
Mar 07, 2022

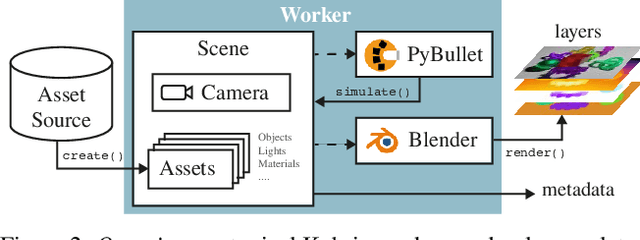
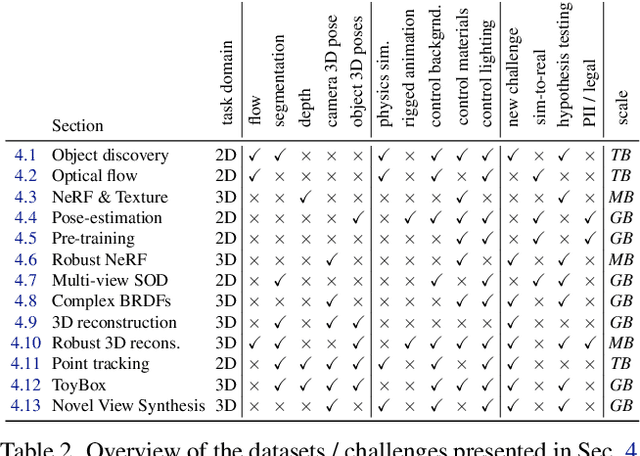
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
Specular-to-Diffuse Translation for Multi-View Reconstruction
Jul 30, 2018



Most multi-view 3D reconstruction algorithms, especially when shape-from-shading cues are used, assume that object appearance is predominantly diffuse. To alleviate this restriction, we introduce S2Dnet, a generative adversarial network for transferring multiple views of objects with specular reflection into diffuse ones, so that multi-view reconstruction methods can be applied more effectively. Our network extends unsupervised image-to-image translation to multi-view "specular to diffuse" translation. To preserve object appearance across multiple views, we introduce a Multi-View Coherence loss (MVC) that evaluates the similarity and faithfulness of local patches after the view-transformation. Our MVC loss ensures that the similarity of local correspondences among multi-view images is preserved under the image-to-image translation. As a result, our network yields significantly better results than several single-view baseline techniques. In addition, we carefully design and generate a large synthetic training data set using physically-based rendering. During testing, our network takes only the raw glossy images as input, without extra information such as segmentation masks or lighting estimation. Results demonstrate that multi-view reconstruction can be significantly improved using the images filtered by our network. We also show promising performance on real world training and testing data.
GazeGAN - Unpaired Adversarial Image Generation for Gaze Estimation
Nov 27, 2017
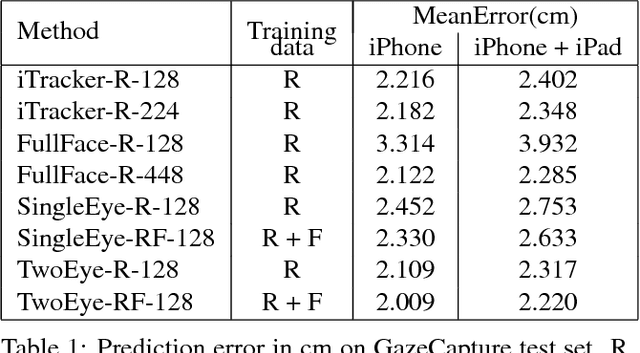

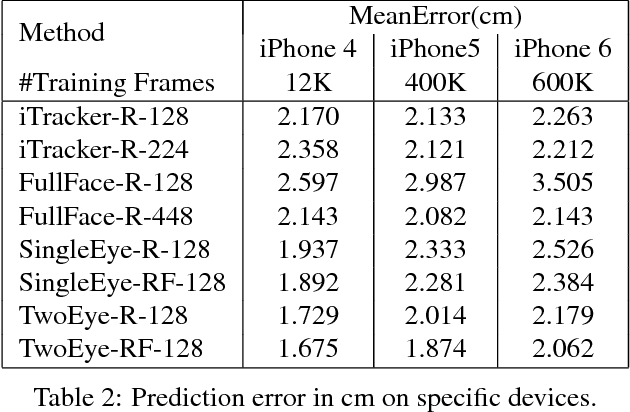
Recent research has demonstrated the ability to estimate gaze on mobile devices by performing inference on the image from the phone's front-facing camera, and without requiring specialized hardware. While this offers wide potential applications such as in human-computer interaction, medical diagnosis and accessibility (e.g., hands free gaze as input for patients with motor disorders), current methods are limited as they rely on collecting data from real users, which is a tedious and expensive process that is hard to scale across devices. There have been some attempts to synthesize eye region data using 3D models that can simulate various head poses and camera settings, however these lack in realism. In this paper, we improve upon a recently suggested method, and propose a generative adversarial framework to generate a large dataset of high resolution colorful images with high diversity (e.g., in subjects, head pose, camera settings) and realism, while simultaneously preserving the accuracy of gaze labels. The proposed approach operates on extended regions of the eye, and even completes missing parts of the image. Using this rich synthesized dataset, and without using any additional training data from real users, we demonstrate improvements over state-of-the-art for estimating 2D gaze position on mobile devices. We further demonstrate cross-device generalization of model performance, as well as improved robustness to diverse head pose, blur and distance.
Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation
Sep 15, 2017



It has been recently shown that neural networks can recover the geometric structure of a face from a single given image. A common denominator of most existing face geometry reconstruction methods is the restriction of the solution space to some low-dimensional subspace. While such a model significantly simplifies the reconstruction problem, it is inherently limited in its expressiveness. As an alternative, we propose an Image-to-Image translation network that jointly maps the input image to a depth image and a facial correspondence map. This explicit pixel-based mapping can then be utilized to provide high quality reconstructions of diverse faces under extreme expressions, using a purely geometric refinement process. In the spirit of recent approaches, the network is trained only with synthetic data, and is then evaluated on in-the-wild facial images. Both qualitative and quantitative analyses demonstrate the accuracy and the robustness of our approach.
Learning Detailed Face Reconstruction from a Single Image
Apr 06, 2017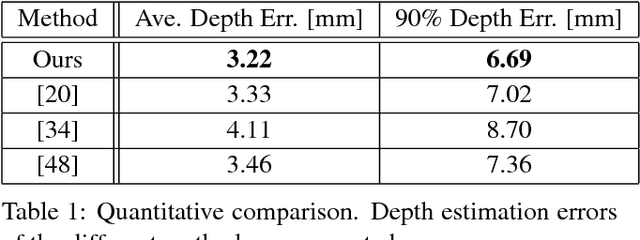


Reconstructing the detailed geometric structure of a face from a given image is a key to many computer vision and graphics applications, such as motion capture and reenactment. The reconstruction task is challenging as human faces vary extensively when considering expressions, poses, textures, and intrinsic geometries. While many approaches tackle this complexity by using additional data to reconstruct the face of a single subject, extracting facial surface from a single image remains a difficult problem. As a result, single-image based methods can usually provide only a rough estimate of the facial geometry. In contrast, we propose to leverage the power of convolutional neural networks to produce a highly detailed face reconstruction from a single image. For this purpose, we introduce an end-to-end CNN framework which derives the shape in a coarse-to-fine fashion. The proposed architecture is composed of two main blocks, a network that recovers the coarse facial geometry (CoarseNet), followed by a CNN that refines the facial features of that geometry (FineNet). The proposed networks are connected by a novel layer which renders a depth image given a mesh in 3D. Unlike object recognition and detection problems, there are no suitable datasets for training CNNs to perform face geometry reconstruction. Therefore, our training regime begins with a supervised phase, based on synthetic images, followed by an unsupervised phase that uses only unconstrained facial images. The accuracy and robustness of the proposed model is demonstrated by both qualitative and quantitative evaluation tests.
3D Face Reconstruction by Learning from Synthetic Data
Sep 26, 2016



Fast and robust three-dimensional reconstruction of facial geometric structure from a single image is a challenging task with numerous applications. Here, we introduce a learning-based approach for reconstructing a three-dimensional face from a single image. Recent face recovery methods rely on accurate localization of key characteristic points. In contrast, the proposed approach is based on a Convolutional-Neural-Network (CNN) which extracts the face geometry directly from its image. Although such deep architectures outperform other models in complex computer vision problems, training them properly requires a large dataset of annotated examples. In the case of three-dimensional faces, currently, there are no large volume data sets, while acquiring such big-data is a tedious task. As an alternative, we propose to generate random, yet nearly photo-realistic, facial images for which the geometric form is known. The suggested model successfully recovers facial shapes from real images, even for faces with extreme expressions and under various lighting conditions.
Customized Facial Constant Positive Air Pressure (CPAP) Masks
Sep 22, 2016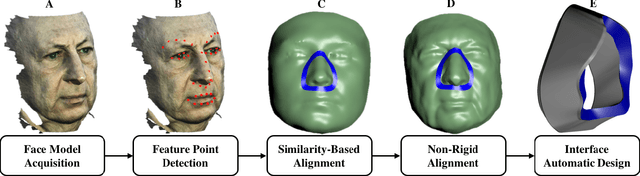
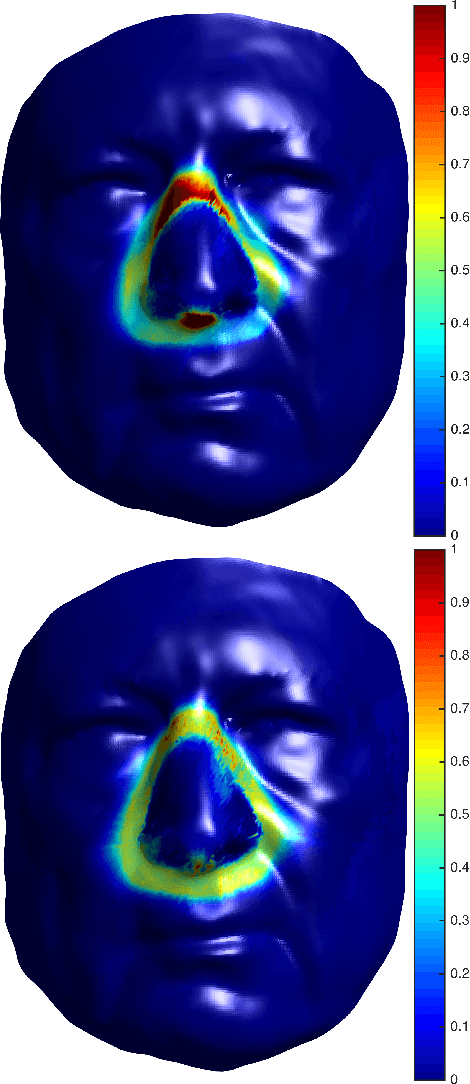
Sleep apnea is a syndrome that is characterized by sudden breathing halts while sleeping. One of the common treatments involves wearing a mask that delivers continuous air flow into the nostrils so as to maintain a steady air pressure. These masks are designed for an average facial model and are often difficult to adjust due to poor fit to the actual patient. The incompatibility is characterized by gaps between the mask and the face, which deteriorates the impermeability of the mask and leads to air leakage. We suggest a fully automatic approach for designing a personalized nasal mask interface using a facial depth scan. The interfaces generated by the proposed method accurately fit the geometry of the scanned face, and are easy to manufacture. The proposed method utilizes cheap commodity depth sensors and 3D printing technologies to efficiently design and manufacture customized masks for patients suffering from sleep apnea.
Randomized Independent Component Analysis
Sep 22, 2016


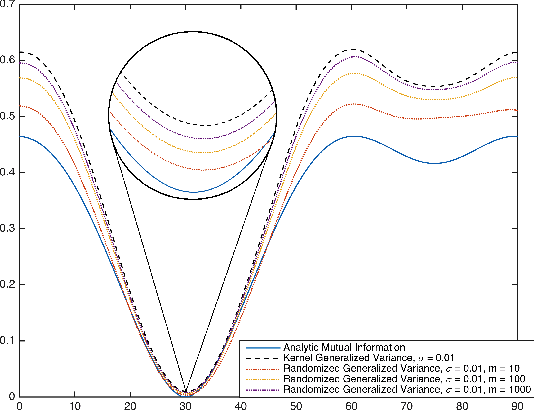
Independent component analysis (ICA) is a method for recovering statistically independent signals from observations of unknown linear combinations of the sources. Some of the most accurate ICA decomposition methods require searching for the inverse transformation which minimizes different approximations of the Mutual Information, a measure of statistical independence of random vectors. Two such approximations are the Kernel Generalized Variance or the Kernel Canonical Correlation which has been shown to reach the highest performance of ICA methods. However, the computational effort necessary just for computing these measures is cubic in the sample size. Hence, optimizing them becomes even more computationally demanding, in terms of both space and time. Here, we propose a couple of alternative novel measures based on randomized features of the samples - the Randomized Generalized Variance and the Randomized Canonical Correlation. The computational complexity of calculating the proposed alternatives is linear in the sample size and provide a controllable approximation of their Kernel-based non-random versions. We also show that optimization of the proposed statistical properties yields a comparable separation error at an order of magnitude faster compared to Kernel-based measures.
Consistent Discretization and Minimization of the L1 Norm on Manifolds
Sep 18, 2016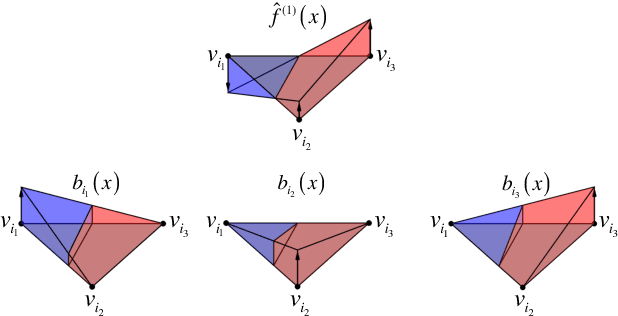


The L1 norm has been tremendously popular in signal and image processing in the past two decades due to its sparsity-promoting properties. More recently, its generalization to non-Euclidean domains has been found useful in shape analysis applications. For example, in conjunction with the minimization of the Dirichlet energy, it was shown to produce a compactly supported quasi-harmonic orthonormal basis, dubbed as compressed manifold modes. The continuous L1 norm on the manifold is often replaced by the vector l1 norm applied to sampled functions. We show that such an approach is incorrect in the sense that it does not consistently discretize the continuous norm and warn against its sensitivity to the specific sampling. We propose two alternative discretizations resulting in an iteratively-reweighed l2 norm. We demonstrate the proposed strategy on the compressed modes problem, which reduces to a sequence of simple eigendecomposition problems not requiring non-convex optimization on Stiefel manifolds and producing more stable and accurate results.