 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeek and You Shall Fold
Nov 17, 2025



Accurate protein structures are essential for understanding biological function, yet incorporating experimental data into protein generative models remains a major challenge. Most predictors of experimental observables are non-differentiable, making them incompatible with gradient-based conditional sampling. This is especially limiting in nuclear magnetic resonance, where rich data such as chemical shifts are hard to directly integrate into generative modeling. We introduce a framework for non-differentiable guidance of protein generative models, coupling a continuous diffusion-based generator with any black-box objective via a tailored genetic algorithm. We demonstrate its effectiveness across three modalities: pairwise distance constraints, nuclear Overhauser effect restraints, and for the first time chemical shifts. These results establish chemical shift guided structure generation as feasible, expose key weaknesses in current predictors, and showcase a general strategy for incorporating diverse experimental signals. Our work points toward automated, data-conditioned protein modeling beyond the limits of differentiability.
Adversarial Robustness in Parameter-Space Classifiers
Feb 27, 2025Implicit Neural Representations (INRs) have been recently garnering increasing interest in various research fields, mainly due to their ability to represent large, complex data in a compact and continuous manner. Past work further showed that numerous popular downstream tasks can be performed directly in the INR parameter-space. Doing so can substantially reduce the computational resources required to process the represented data in their native domain. A major difficulty in using modern machine-learning approaches, is their high susceptibility to adversarial attacks, which have been shown to greatly limit the reliability and applicability of such methods in a wide range of settings. In this work, we show that parameter-space models trained for classification are inherently robust to adversarial attacks -- without the need of any robust training. To support our claims, we develop a novel suite of adversarial attacks targeting parameter-space classifiers, and furthermore analyze practical considerations of attacking parameter-space classifiers. Code for reproducing all experiments and implementation of all proposed methods will be released upon publication.
On Adversarial Attacks In Acoustic Drone Localization
Feb 27, 2025Multi-rotor aerial autonomous vehicles (MAVs, more widely known as "drones") have been generating increased interest in recent years due to their growing applicability in a vast and diverse range of fields (e.g., agriculture, commercial delivery, search and rescue). The sensitivity of visual-based methods to lighting conditions and occlusions had prompted growing study of navigation reliant on other modalities, such as acoustic sensing. A major concern in using drones in scale for tasks in non-controlled environments is the potential threat of adversarial attacks over their navigational systems, exposing users to mission-critical failures, security breaches, and compromised safety outcomes that can endanger operators and bystanders. While previous work shows impressive progress in acoustic-based drone localization, prior research in adversarial attacks over drone navigation only addresses visual sensing-based systems. In this work, we aim to compensate for this gap by supplying a comprehensive analysis of the effect of PGD adversarial attacks over acoustic drone localization. We furthermore develop an algorithm for adversarial perturbation recovery, capable of markedly diminishing the affect of such attacks in our setting. The code for reproducing all experiments will be released upon publication.
T1-PILOT: Optimized Trajectories for T1 Mapping Acceleration
Feb 27, 2025Cardiac T1 mapping provides critical quantitative insights into myocardial tissue composition, enabling the assessment of pathologies such as fibrosis, inflammation, and edema. However, the inherently dynamic nature of the heart imposes strict limits on acquisition times, making high-resolution T1 mapping a persistent challenge. Compressed sensing (CS) approaches have reduced scan durations by undersampling k-space and reconstructing images from partial data, and recent studies show that jointly optimizing the undersampling patterns with the reconstruction network can substantially improve performance. Still, most current T1 mapping pipelines rely on static, hand-crafted masks that do not exploit the full acceleration and accuracy potential. In this work, we introduce T1-PILOT: an end-to-end method that explicitly incorporates the T1 signal relaxation model into the sampling-reconstruction framework to guide the learning of non-Cartesian trajectories, crossframe alignment, and T1 decay estimation. Through extensive experiments on the CMRxRecon dataset, T1-PILOT significantly outperforms several baseline strategies (including learned single-mask and fixed radial or golden-angle sampling schemes), achieving higher T1 map fidelity at greater acceleration factors. In particular, we observe consistent gains in PSNR and VIF relative to existing methods, along with marked improvements in delineating finer myocardial structures. Our results highlight that optimizing sampling trajectories in tandem with the physical relaxation model leads to both enhanced quantitative accuracy and reduced acquisition times. Code for reproducing all results will be made publicly available upon publication.
Generative modeling of protein ensembles guided by crystallographic electron densities
Dec 17, 2024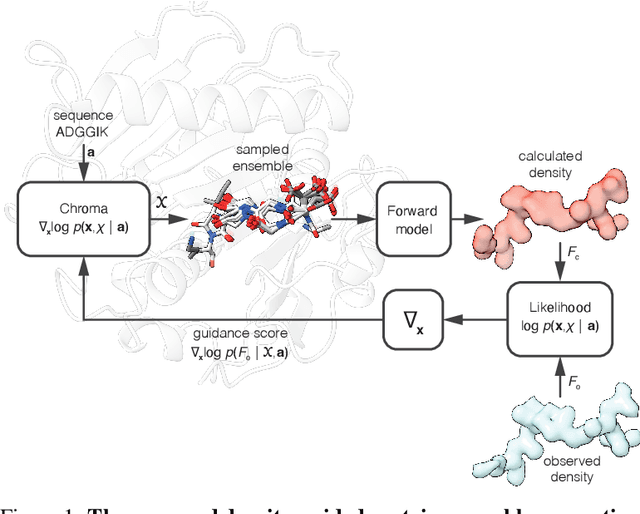
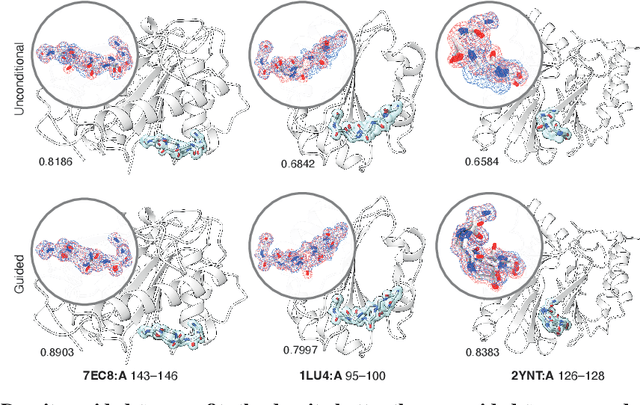
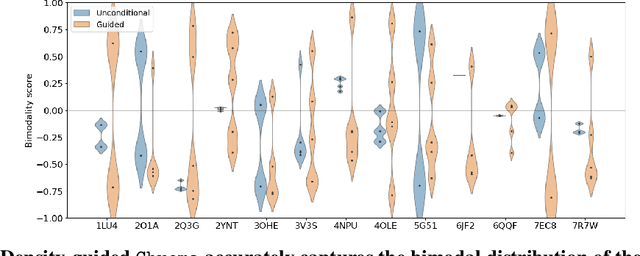
Proteins are dynamic, adopting ensembles of conformations. The nature of this conformational heterogenity is imprinted in the raw electron density measurements obtained from X-ray crystallography experiments. Fitting an ensemble of protein structures to these measurements is a challenging, ill-posed inverse problem. We propose a non-i.i.d. ensemble guidance approach to solve this problem using existing protein structure generative models and demonstrate that it accurately recovers complicated multi-modal alternate protein backbone conformations observed in certain single crystal measurements.
Sample- and Parameter-Efficient Auto-Regressive Image Models
Nov 23, 2024



We introduce XTRA, a vision model pre-trained with a novel auto-regressive objective that significantly enhances both sample and parameter efficiency compared to previous auto-regressive image models. Unlike contrastive or masked image modeling methods, which have not been demonstrated as having consistent scaling behavior on unbalanced internet data, auto-regressive vision models exhibit scalable and promising performance as model and dataset size increase. In contrast to standard auto-regressive models, XTRA employs a Block Causal Mask, where each Block represents k $\times$ k tokens rather than relying on a standard causal mask. By reconstructing pixel values block by block, XTRA captures higher-level structural patterns over larger image regions. Predicting on blocks allows the model to learn relationships across broader areas of pixels, enabling more abstract and semantically meaningful representations than traditional next-token prediction. This simple modification yields two key results. First, XTRA is sample-efficient. Despite being trained on 152$\times$ fewer samples (13.1M vs. 2B), XTRA ViT-H/14 surpasses the top-1 average accuracy of the previous state-of-the-art auto-regressive model across 15 diverse image recognition benchmarks. Second, XTRA is parameter-efficient. Compared to auto-regressive models trained on ImageNet-1k, XTRA ViT-B/16 outperforms in linear and attentive probing tasks, using 7-16$\times$ fewer parameters (85M vs. 1.36B/0.63B).
Scalable unsupervised alignment of general metric and non-metric structures
Jun 19, 2024Aligning data from different domains is a fundamental problem in machine learning with broad applications across very different areas, most notably aligning experimental readouts in single-cell multiomics. Mathematically, this problem can be formulated as the minimization of disagreement of pair-wise quantities such as distances and is related to the Gromov-Hausdorff and Gromov-Wasserstein distances. Computationally, it is a quadratic assignment problem (QAP) that is known to be NP-hard. Prior works attempted to solve the QAP directly with entropic or low-rank regularization on the permutation, which is computationally tractable only for modestly-sized inputs, and encode only limited inductive bias related to the domains being aligned. We consider the alignment of metric structures formulated as a discrete Gromov-Wasserstein problem and instead of solving the QAP directly, we propose to learn a related well-scalable linear assignment problem (LAP) whose solution is also a minimizer of the QAP. We also show a flexible extension of the proposed framework to general non-metric dissimilarities through differentiable ranks. We extensively evaluate our approach on synthetic and real datasets from single-cell multiomics and neural latent spaces, achieving state-of-the-art performance while being conceptually and computationally simple.
A Theoretical Framework for an Efficient Normalizing Flow-Based Solution to the Schrodinger Equation
May 28, 2024A central problem in quantum mechanics involves solving the Electronic Schrodinger Equation for a molecule or material. The Variational Monte Carlo approach to this problem approximates a particular variational objective via sampling, and then optimizes this approximated objective over a chosen parameterized family of wavefunctions, known as the ansatz. Recently neural networks have been used as the ansatz, with accompanying success. However, sampling from such wavefunctions has required the use of a Markov Chain Monte Carlo approach, which is inherently inefficient. In this work, we propose a solution to this problem via an ansatz which is cheap to sample from, yet satisfies the requisite quantum mechanical properties. We prove that a normalizing flow using the following two essential ingredients satisfies our requirements: (a) a base distribution which is constructed from Determinantal Point Processes; (b) flow layers which are equivariant to a particular subgroup of the permutation group. We then show how to construct both continuous and discrete normalizing flows which satisfy the requisite equivariance. We further demonstrate the manner in which the non-smooth nature ("cusps") of the wavefunction may be captured, and how the framework may be generalized to provide induction across multiple molecules. The resulting theoretical framework entails an efficient approach to solving the Electronic Schrodinger Equation.
Leveraging Latents for Efficient Thermography Classification and Segmentation
Apr 09, 2024Breast cancer is a prominent health concern worldwide, currently being the secondmost common and second-deadliest type of cancer in women. While current breast cancer diagnosis mainly relies on mammography imaging, in recent years the use of thermography for breast cancer imaging has been garnering growing popularity. Thermographic imaging relies on infrared cameras to capture body-emitted heat distributions. While these heat signatures have proven useful for computer-vision systems for accurate breast cancer segmentation and classification, prior work often relies on handcrafted feature engineering or complex architectures, potentially limiting the comparability and applicability of these methods. In this work, we present a novel algorithm for both breast cancer classification and segmentation. Rather than focusing efforts on manual feature and architecture engineering, our algorithm focuses on leveraging an informative, learned feature space, thus making our solution simpler to use and extend to other frameworks and downstream tasks, as well as more applicable to data-scarce settings. Our classification produces SOTA results, while we are the first work to produce segmentation regions studied in this paper.
Active propulsion noise shaping for multi-rotor aircraft localization
Feb 29, 2024

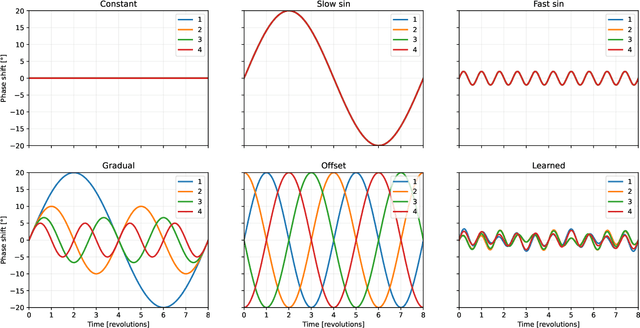
Multi-rotor aerial autonomous vehicles (MAVs) primarily rely on vision for navigation purposes. However, visual localization and odometry techniques suffer from poor performance in low or direct sunlight, a limited field of view, and vulnerability to occlusions. Acoustic sensing can serve as a complementary or even alternative modality for vision in many situations, and it also has the added benefits of lower system cost and energy footprint, which is especially important for micro aircraft. This paper proposes actively controlling and shaping the aircraft propulsion noise generated by the rotors to benefit localization tasks, rather than considering it a harmful nuisance. We present a neural network architecture for selfnoise-based localization in a known environment. We show that training it simultaneously with learning time-varying rotor phase modulation achieves accurate and robust localization. The proposed methods are evaluated using a computationally affordable simulation of MAV rotor noise in 2D acoustic environments that is fitted to real recordings of rotor pressure fields.