 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSNAPS: Audio-Visual Separation of Speech and Background Noise with Diffusion Inverse Sampling
Feb 01, 2026This paper addresses the challenge of audio-visual single-microphone speech separation and enhancement in the presence of real-world environmental noise. Our approach is based on generative inverse sampling, where we model clean speech and ambient noise with dedicated diffusion priors and jointly leverage them to recover all underlying sources. To achieve this, we reformulate a recent inverse sampler to match our setting. We evaluate on mixtures of 1, 2, and 3 speakers with noise and show that, despite being entirely unsupervised, our method consistently outperforms leading supervised baselines in \ac{WER} across all conditions. We further extend our framework to handle off-screen speaker separation. Moreover, the high fidelity of the separated noise component makes it suitable for downstream acoustic scene detection. Demo page: https://ssnapsicml.github.io/ssnapsicml2026/
LR-DWM: Efficient Watermarking for Diffusion Language Models
Jan 18, 2026Watermarking (WM) is a critical mechanism for detecting and attributing AI-generated content. Current WM methods for Large Language Models (LLMs) are predominantly tailored for autoregressive (AR) models: They rely on tokens being generated sequentially, and embed stable signals within the generated sequence based on the previously sampled text. Diffusion Language Models (DLMs) generate text via non-sequential iterative denoising, which requires significant modification to use WM methods designed for AR models. Recent work proposed to watermark DLMs by inverting the process when needed, but suffers significant computational or memory overhead. We introduce Left-Right Diffusion Watermarking (LR-DWM), a scheme that biases the generated token based on both left and right neighbors, when they are available. LR-DWM incurs minimal runtime and memory overhead, remaining close to the non-watermarked baseline DLM while enabling reliable statistical detection under standard evaluation settings. Our results demonstrate that DLMs can be watermarked efficiently, achieving high detectability with negligible computational and memory overhead.
Questioning the Stability of Visual Question Answering
Nov 14, 2025Visual Language Models (VLMs) have achieved remarkable progress, yet their reliability under small, meaning-preserving input changes remains poorly understood. We present the first large-scale, systematic study of VLM robustness to benign visual and textual perturbations: pixel-level shifts, light geometric transformations, padded rescaling, paraphrasing, and multilingual rewrites that do not alter the underlying semantics of an image-question pair. Across a broad set of models and datasets, we find that modern VLMs are highly sensitive to such minor perturbations: a substantial fraction of samples change their predicted answer under at least one visual or textual modification. We characterize how this instability varies across perturbation types, question categories, and models, revealing that even state-of-the-art systems (e.g., GPT-4o, Gemini 2.0 Flash) frequently fail under shifts as small as a few pixels or harmless rephrasings. We further show that sample-level stability serves as a strong indicator of correctness: stable samples are consistently far more likely to be answered correctly. Leveraging this, we demonstrate that the stability patterns of small, accessible open-source models can be used to predict the correctness of much larger closed-source models with high precision. Our findings expose a fundamental fragility in current VLMs and highlight the need for robustness evaluations that go beyond adversarial perturbations, focusing instead on invariances that models should reliably uphold.
Few-Shot Speech Deepfake Detection Adaptation with Gaussian Processes
May 29, 2025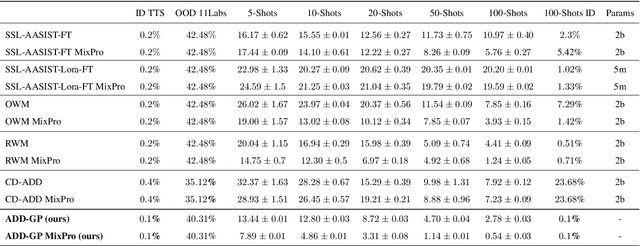

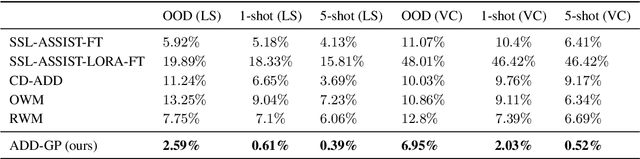
Recent advancements in Text-to-Speech (TTS) models, particularly in voice cloning, have intensified the demand for adaptable and efficient deepfake detection methods. As TTS systems continue to evolve, detection models must be able to efficiently adapt to previously unseen generation models with minimal data. This paper introduces ADD-GP, a few-shot adaptive framework based on a Gaussian Process (GP) classifier for Audio Deepfake Detection (ADD). We show how the combination of a powerful deep embedding model with the Gaussian processes flexibility can achieve strong performance and adaptability. Additionally, we show this approach can also be used for personalized detection, with greater robustness to new TTS models and one-shot adaptability. To support our evaluation, a benchmark dataset is constructed for this task using new state-of-the-art voice cloning models.
Go Beyond Your Means: Unlearning with Per-Sample Gradient Orthogonalization
Mar 04, 2025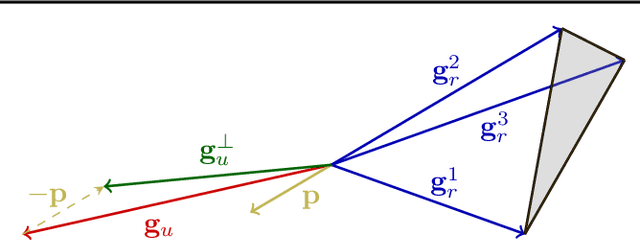
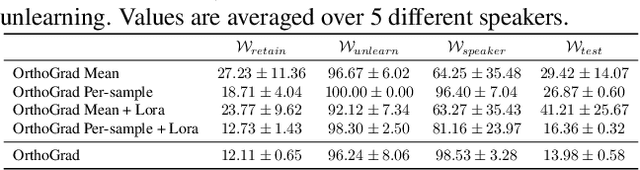

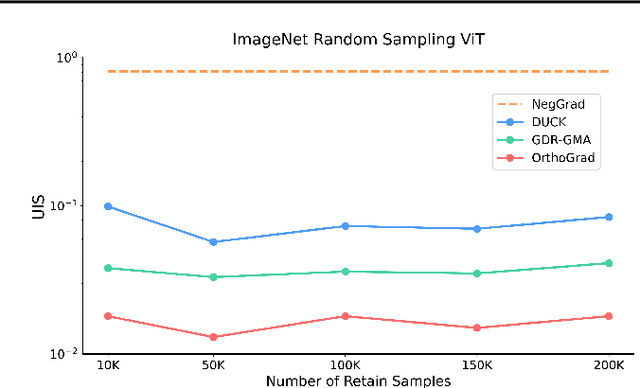
Machine unlearning aims to remove the influence of problematic training data after a model has been trained. The primary challenge in machine unlearning is ensuring that the process effectively removes specified data without compromising the model's overall performance on the remaining dataset. Many existing machine unlearning methods address this challenge by carefully balancing gradient ascent on the unlearn data with the gradient descent on a retain set representing the training data. Here, we propose OrthoGrad, a novel approach that mitigates interference between the unlearn set and the retain set rather than competing ascent and descent processes. Our method projects the gradient of the unlearn set onto the subspace orthogonal to all gradients in the retain batch, effectively avoiding any gradient interference. We demonstrate the effectiveness of OrthoGrad on multiple machine unlearning benchmarks, including automatic speech recognition, outperforming competing methods.
Adversarial Robustness in Parameter-Space Classifiers
Feb 27, 2025Implicit Neural Representations (INRs) have been recently garnering increasing interest in various research fields, mainly due to their ability to represent large, complex data in a compact and continuous manner. Past work further showed that numerous popular downstream tasks can be performed directly in the INR parameter-space. Doing so can substantially reduce the computational resources required to process the represented data in their native domain. A major difficulty in using modern machine-learning approaches, is their high susceptibility to adversarial attacks, which have been shown to greatly limit the reliability and applicability of such methods in a wide range of settings. In this work, we show that parameter-space models trained for classification are inherently robust to adversarial attacks -- without the need of any robust training. To support our claims, we develop a novel suite of adversarial attacks targeting parameter-space classifiers, and furthermore analyze practical considerations of attacking parameter-space classifiers. Code for reproducing all experiments and implementation of all proposed methods will be released upon publication.
Inverse Problem Sampling in Latent Space Using Sequential Monte Carlo
Feb 09, 2025



In image processing, solving inverse problems is the task of finding plausible reconstructions of an image that was corrupted by some (usually known) degradation model. Commonly, this process is done using a generative image model that can guide the reconstruction towards solutions that appear natural. The success of diffusion models over the last few years has made them a leading candidate for this task. However, the sequential nature of diffusion models makes this conditional sampling process challenging. Furthermore, since diffusion models are often defined in the latent space of an autoencoder, the encoder-decoder transformations introduce additional difficulties. Here, we suggest a novel sampling method based on sequential Monte Carlo (SMC) in the latent space of diffusion models. We use the forward process of the diffusion model to add additional auxiliary observations and then perform an SMC sampling as part of the backward process. Empirical evaluations on ImageNet and FFHQ show the benefits of our approach over competing methods on various inverse problem tasks.
Multi Task Inverse Reinforcement Learning for Common Sense Reward
Feb 17, 2024One of the challenges in applying reinforcement learning in a complex real-world environment lies in providing the agent with a sufficiently detailed reward function. Any misalignment between the reward and the desired behavior can result in unwanted outcomes. This may lead to issues like "reward hacking" where the agent maximizes rewards by unintended behavior. In this work, we propose to disentangle the reward into two distinct parts. A simple task-specific reward, outlining the particulars of the task at hand, and an unknown common-sense reward, indicating the expected behavior of the agent within the environment. We then explore how this common-sense reward can be learned from expert demonstrations. We first show that inverse reinforcement learning, even when it succeeds in training an agent, does not learn a useful reward function. That is, training a new agent with the learned reward does not impair the desired behaviors. We then demonstrate that this problem can be solved by training simultaneously on multiple tasks. That is, multi-task inverse reinforcement learning can be applied to learn a useful reward function.
Improved Generalization of Weight Space Networks via Augmentations
Feb 06, 2024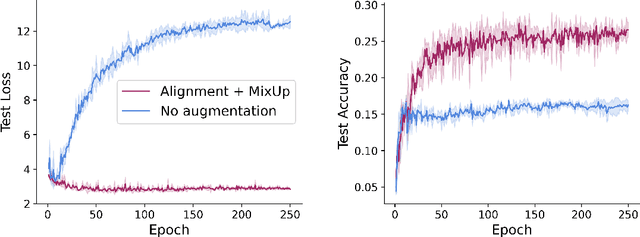
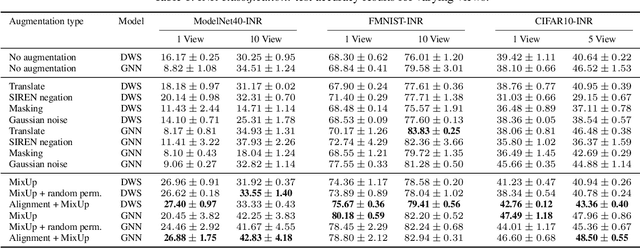
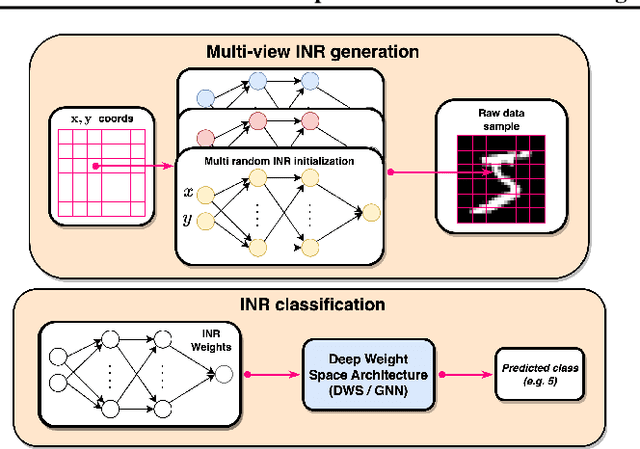

Learning in deep weight spaces (DWS), where neural networks process the weights of other neural networks, is an emerging research direction, with applications to 2D and 3D neural fields (INRs, NeRFs), as well as making inferences about other types of neural networks. Unfortunately, weight space models tend to suffer from substantial overfitting. We empirically analyze the reasons for this overfitting and find that a key reason is the lack of diversity in DWS datasets. While a given object can be represented by many different weight configurations, typical INR training sets fail to capture variability across INRs that represent the same object. To address this, we explore strategies for data augmentation in weight spaces and propose a MixUp method adapted for weight spaces. We demonstrate the effectiveness of these methods in two setups. In classification, they improve performance similarly to having up to 10 times more data. In self-supervised contrastive learning, they yield substantial 5-10% gains in downstream classification.
Bayesian Uncertainty for Gradient Aggregation in Multi-Task Learning
Feb 06, 2024



As machine learning becomes more prominent there is a growing demand to perform several inference tasks in parallel. Running a dedicated model for each task is computationally expensive and therefore there is a great interest in multi-task learning (MTL). MTL aims at learning a single model that solves several tasks efficiently. Optimizing MTL models is often achieved by computing a single gradient per task and aggregating them for obtaining a combined update direction. However, these approaches do not consider an important aspect, the sensitivity in the gradient dimensions. Here, we introduce a novel gradient aggregation approach using Bayesian inference. We place a probability distribution over the task-specific parameters, which in turn induce a distribution over the gradients of the tasks. This additional valuable information allows us to quantify the uncertainty in each of the gradients dimensions, which can then be factored in when aggregating them. We empirically demonstrate the benefits of our approach in a variety of datasets, achieving state-of-the-art performance.