 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestioning the Stability of Visual Question Answering
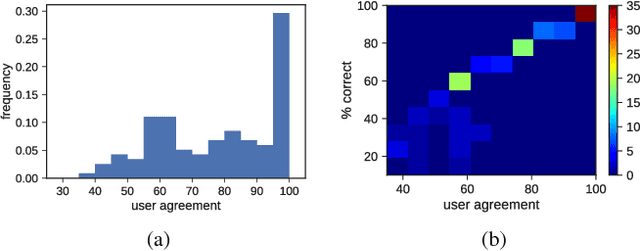
Nov 14, 2025Visual Language Models (VLMs) have achieved remarkable progress, yet their reliability under small, meaning-preserving input changes remains poorly understood. We present the first large-scale, systematic study of VLM robustness to benign visual and textual perturbations: pixel-level shifts, light geometric transformations, padded rescaling, paraphrasing, and multilingual rewrites that do not alter the underlying semantics of an image-question pair. Across a broad set of models and datasets, we find that modern VLMs are highly sensitive to such minor perturbations: a substantial fraction of samples change their predicted answer under at least one visual or textual modification. We characterize how this instability varies across perturbation types, question categories, and models, revealing that even state-of-the-art systems (e.g., GPT-4o, Gemini 2.0 Flash) frequently fail under shifts as small as a few pixels or harmless rephrasings. We further show that sample-level stability serves as a strong indicator of correctness: stable samples are consistently far more likely to be answered correctly. Leveraging this, we demonstrate that the stability patterns of small, accessible open-source models can be used to predict the correctness of much larger closed-source models with high precision. Our findings expose a fundamental fragility in current VLMs and highlight the need for robustness evaluations that go beyond adversarial perturbations, focusing instead on invariances that models should reliably uphold.
Inverse Problem Sampling in Latent Space Using Sequential Monte Carlo
Feb 09, 2025



In image processing, solving inverse problems is the task of finding plausible reconstructions of an image that was corrupted by some (usually known) degradation model. Commonly, this process is done using a generative image model that can guide the reconstruction towards solutions that appear natural. The success of diffusion models over the last few years has made them a leading candidate for this task. However, the sequential nature of diffusion models makes this conditional sampling process challenging. Furthermore, since diffusion models are often defined in the latent space of an autoencoder, the encoder-decoder transformations introduce additional difficulties. Here, we suggest a novel sampling method based on sequential Monte Carlo (SMC) in the latent space of diffusion models. We use the forward process of the diffusion model to add additional auxiliary observations and then perform an SMC sampling as part of the backward process. Empirical evaluations on ImageNet and FFHQ show the benefits of our approach over competing methods on various inverse problem tasks.
A Constructive Prediction of the Generalization Error Across Scales
Sep 27, 2019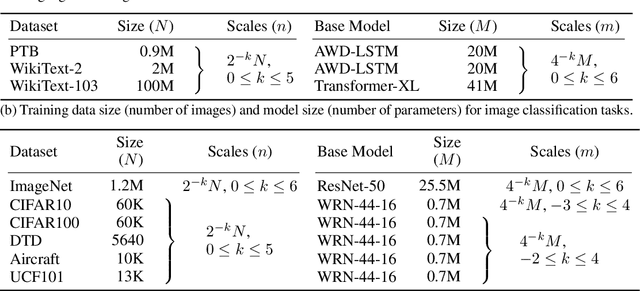
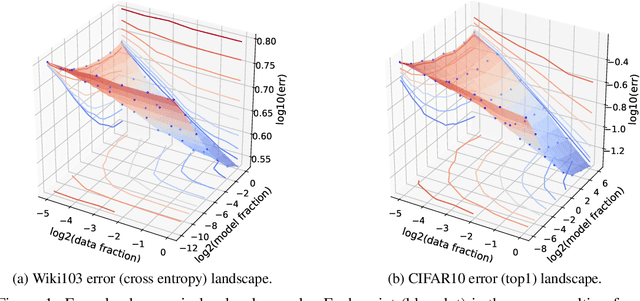
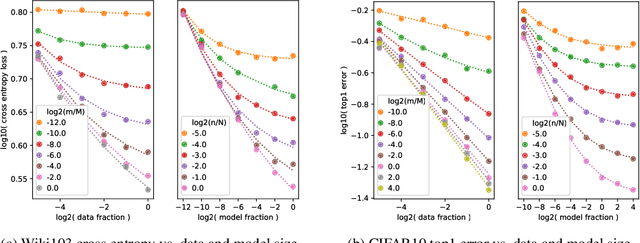
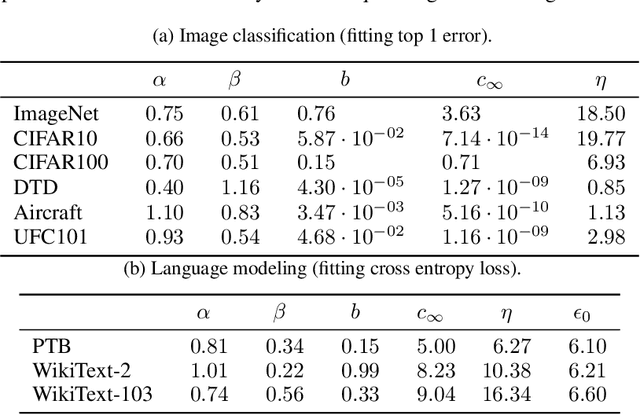
The dependency of the generalization error of neural networks on model and dataset size is of critical importance both in practice and for understanding the theory of neural networks. Nevertheless, the functional form of this dependency remains elusive. In this work, we present a functional form which approximates well the generalization error in practice. Capitalizing on the successful concept of model scaling (e.g., width, depth), we are able to simultaneously construct such a form and specify the exact models which can attain it across model/data scales. Our construction follows insights obtained from observations conducted over a range of model/data scales, in various model types and datasets, in vision and language tasks. We show that the form both fits the observations well across scales, and provides accurate predictions from small- to large-scale models and data.
High-Level Perceptual Similarity is Enabled by Learning Diverse Tasks
Mar 26, 2019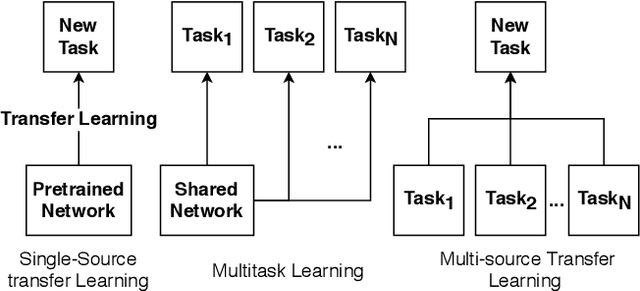
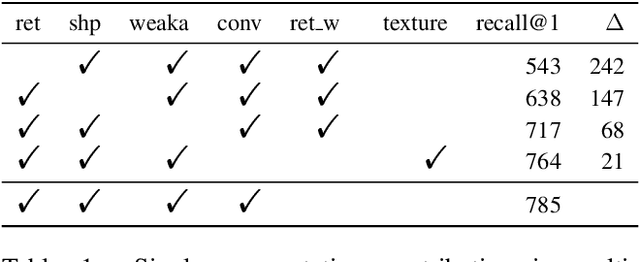

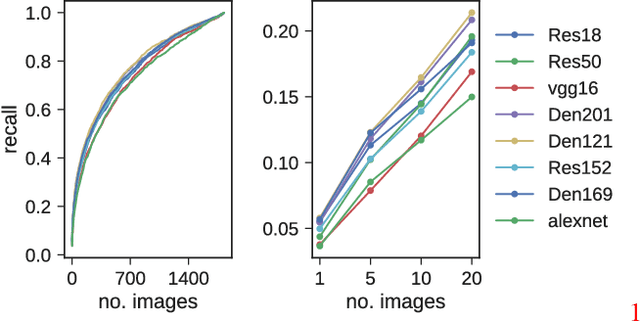
Predicting human perceptual similarity is a challenging subject of ongoing research. The visual process underlying this aspect of human vision is thought to employ multiple different levels of visual analysis (shapes, objects, texture, layout, color, etc). In this paper, we postulate that the perception of image similarity is not an explicitly learned capability, but rather one that is a byproduct of learning others. This claim is supported by leveraging representations learned from a diverse set of visual tasks and using them jointly to predict perceptual similarity. This is done via simple feature concatenation, without any further learning. Nevertheless, experiments performed on the challenging Totally-Looks-Like (TLL) benchmark significantly surpass recent baselines, closing much of the reported gap towards prediction of human perceptual similarity. We provide an analysis of these results and discuss them in a broader context of emergent visual capabilities and their implications on the course of machine-vision research.
Totally Looks Like - How Humans Compare, Compared to Machines
Oct 18, 2018

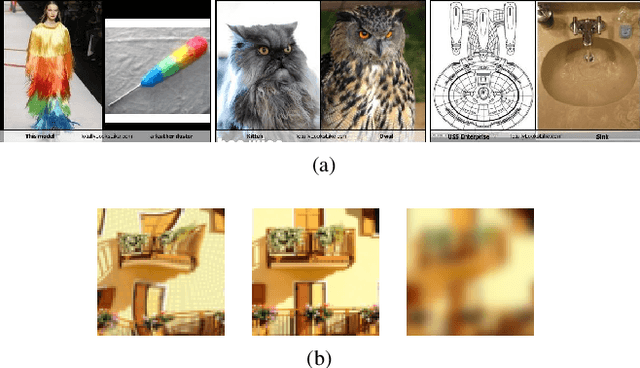
Perceptual judgment of image similarity by humans relies on rich internal representations ranging from low-level features to high-level concepts, scene properties and even cultural associations. However, existing methods and datasets attempting to explain perceived similarity use stimuli which arguably do not cover the full breadth of factors that affect human similarity judgments, even those geared toward this goal. We introduce a new dataset dubbed Totally-Looks-Like (TLL) after a popular entertainment website, which contains images paired by humans as being visually similar. The dataset contains 6016 image-pairs from the wild, shedding light upon a rich and diverse set of criteria employed by human beings. We conduct experiments to try to reproduce the pairings via features extracted from state-of-the-art deep convolutional neural networks, as well as additional human experiments to verify the consistency of the collected data. Though we create conditions to artificially make the matching task increasingly easier, we show that machine-extracted representations perform very poorly in terms of reproducing the matching selected by humans. We discuss and analyze these results, suggesting future directions for improvement of learned image representations.
The Elephant in the Room
Aug 09, 2018


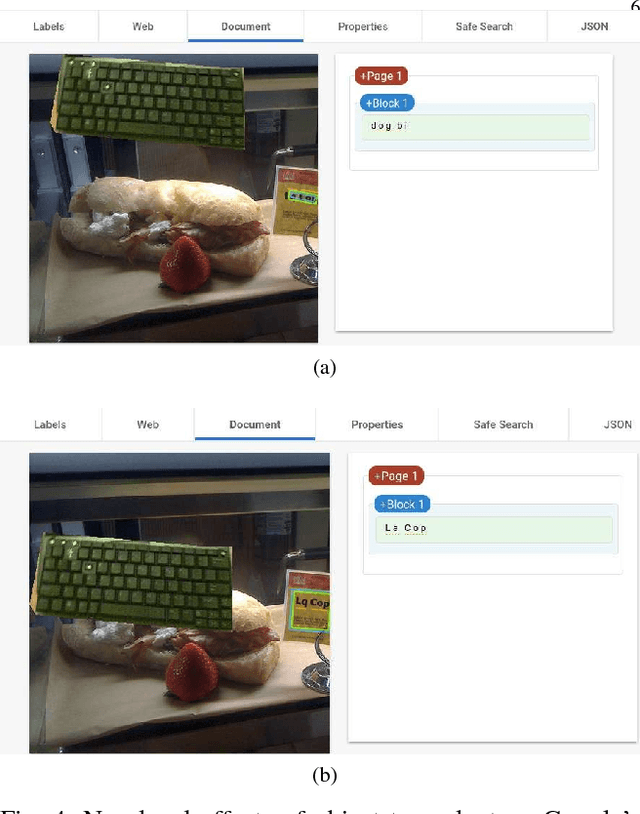
We showcase a family of common failures of state-of-the art object detectors. These are obtained by replacing image sub-regions by another sub-image that contains a trained object. We call this "object transplanting". Modifying an image in this manner is shown to have a non-local impact on object detection. Slight changes in object position can affect its identity according to an object detector as well as that of other objects in the image. We provide some analysis and suggest possible reasons for the reported phenomena.
Action Classification via Concepts and Attributes
Mar 07, 2018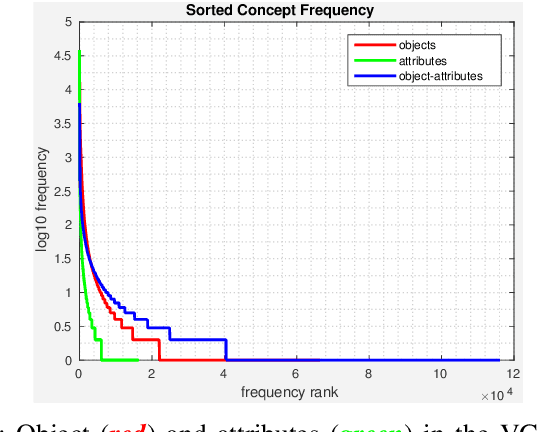
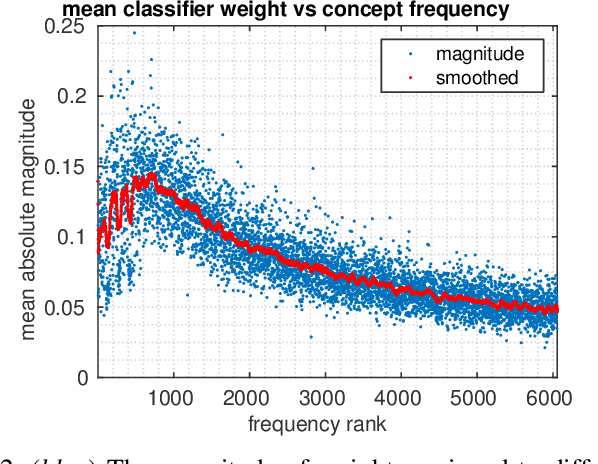
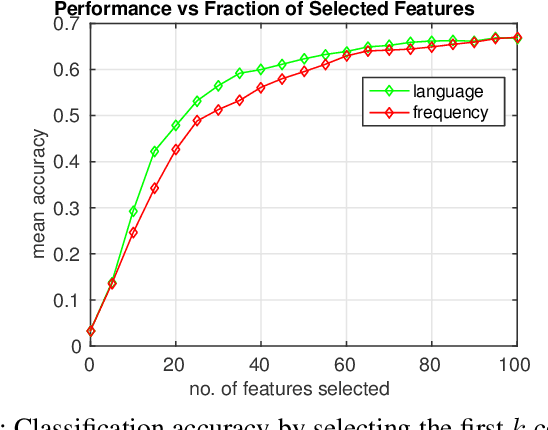
Classes in natural images tend to follow long tail distributions. This is problematic when there are insufficient training examples for rare classes. This effect is emphasized in compound classes, involving the conjunction of several concepts, such as those appearing in action-recognition datasets. In this paper, we propose to address this issue by learning how to utilize common visual concepts which are readily available. We detect the presence of prominent concepts in images and use them to infer the target labels instead of using visual features directly, combining tools from vision and natural-language processing. We validate our method on the recently introduced HICO dataset reaching a mAP of 31.54\% and on the Stanford-40 Actions dataset, where the proposed method outperforms that obtained by direct visual features, obtaining an accuracy 83.12\%. Moreover, the method provides for each class a semantically meaningful list of keywords and relevant image regions relating it to its constituent concepts.
Bridging Cognitive Programs and Machine Learning
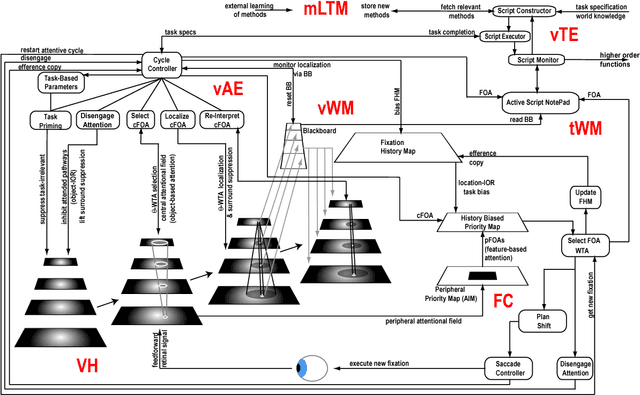
Feb 16, 2018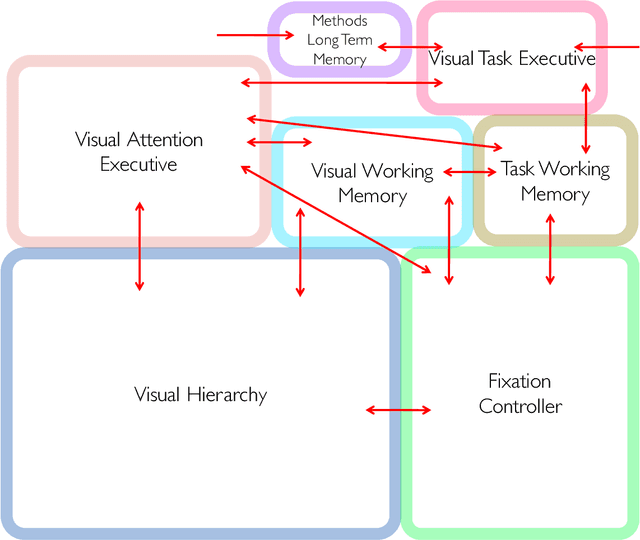

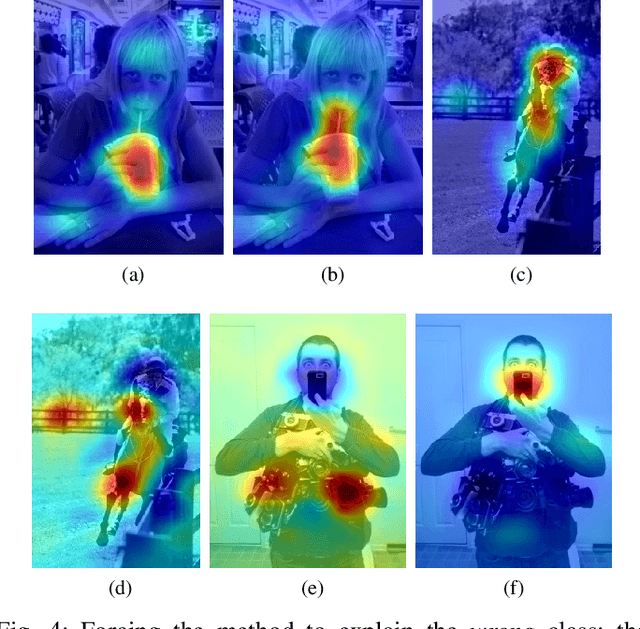
While great advances are made in pattern recognition and machine learning, the successes of such fields remain restricted to narrow applications and seem to break down when training data is scarce, a shift in domain occurs, or when intelligent reasoning is required for rapid adaptation to new environments. In this work, we list several of the shortcomings of modern machine-learning solutions, specifically in the contexts of computer vision and in reinforcement learning and suggest directions to explore in order to try to ameliorate these weaknesses.
Challenging Images For Minds and Machines
Feb 13, 2018
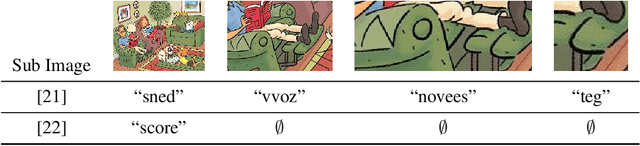
There is no denying the tremendous leap in the performance of machine learning methods in the past half-decade. Some might even say that specific sub-fields in pattern recognition, such as machine-vision, are as good as solved, reaching human and super-human levels. Arguably, lack of training data and computation power are all that stand between us and solving the remaining ones. In this position paper we underline cases in vision which are challenging to machines and even to human observers. This is to show limitations of contemporary models that are hard to ameliorate by following the current trend to increase training data, network capacity or computational power. Moreover, we claim that attempting to do so is in principle a suboptimal approach. We provide a taster of such examples in hope to encourage and challenge the machine learning community to develop new directions to solve the said difficulties.
Incremental Learning Through Deep Adaptation
Feb 13, 2018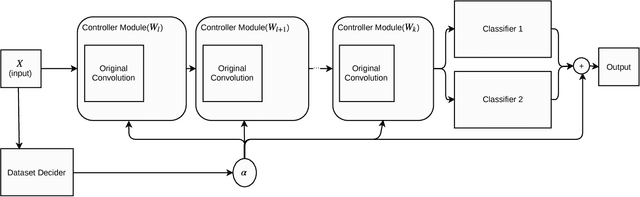

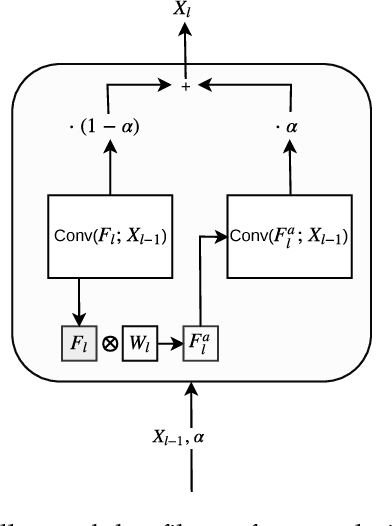
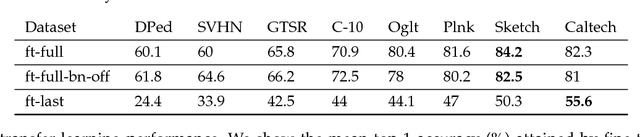
Given an existing trained neural network, it is often desirable to learn new capabilities without hindering performance of those already learned. Existing approaches either learn sub-optimal solutions, require joint training, or incur a substantial increment in the number of parameters for each added domain, typically as many as the original network. We propose a method called \emph{Deep Adaptation Networks} (DAN) that constrains newly learned filters to be linear combinations of existing ones. DANs precisely preserve performance on the original domain, require a fraction (typically 13\%, dependent on network architecture) of the number of parameters compared to standard fine-tuning procedures and converge in less cycles of training to a comparable or better level of performance. When coupled with standard network quantization techniques, we further reduce the parameter cost to around 3\% of the original with negligible or no loss in accuracy. The learned architecture can be controlled to switch between various learned representations, enabling a single network to solve a task from multiple different domains. We conduct extensive experiments showing the effectiveness of our method on a range of image classification tasks and explore different aspects of its behavior.