 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIJIT: A Robotic Head for an Active Observer
Dec 08, 2025We present DIJIT, a novel binocular robotic head expressly designed for mobile agents that behave as active observers. DIJIT's unique breadth of functionality enables active vision research and the study of human-like eye and head-neck motions, their interrelationships, and how each contributes to visual ability. DIJIT is also being used to explore the differences between how human vision employs eye/head movements to solve visual tasks and current computer vision methods. DIJIT's design features nine mechanical degrees of freedom, while the cameras and lenses provide an additional four optical degrees of freedom. The ranges and speeds of the mechanical design are comparable to human performance. Our design includes the ranges of motion required for convergent stereo, namely, vergence, version, and cyclotorsion. The exploration of the utility of these to both human and machine vision is ongoing. Here, we present the design of DIJIT and evaluate aspects of its performance. We present a new method for saccadic camera movements. In this method, a direct relationship between camera orientation and motor values is developed. The resulting saccadic camera movements are close to human movements in terms of their accuracy.
The Psychophysics of Human Three-Dimensional Active Visuospatial Problem-Solving
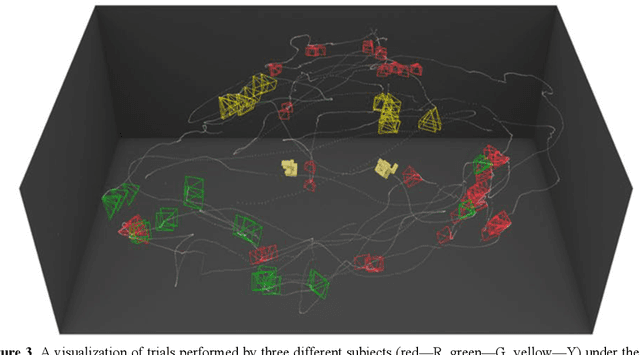
Jun 19, 2023Our understanding of how visual systems detect, analyze and interpret visual stimuli has advanced greatly. However, the visual systems of all animals do much more; they enable visual behaviours. How well the visual system performs while interacting with the visual environment and how vision is used in the real world have not been well studied, especially in humans. It has been suggested that comparison is the most primitive of psychophysical tasks. Thus, as a probe into these active visual behaviours, we use a same-different task: are two physical 3D objects visually the same? This task seems to be a fundamental cognitive ability. We pose this question to human subjects who are free to move about and examine two real objects in an actual 3D space. Past work has dealt solely with a 2D static version of this problem. We have collected detailed, first-of-its-kind data of humans performing a visuospatial task in hundreds of trials. Strikingly, humans are remarkably good at this task without any training, with a mean accuracy of 93.82%. No learning effect was observed on accuracy after many trials, but some effect was seen for response time, number of fixations and extent of head movement. Subjects demonstrated a variety of complex strategies involving a range of movement and eye fixation changes, suggesting that solutions were developed dynamically and tailored to the specific task.
Next-Best-View Estimation based on Deep Reinforcement Learning for Active Object Classification
Oct 14, 2021
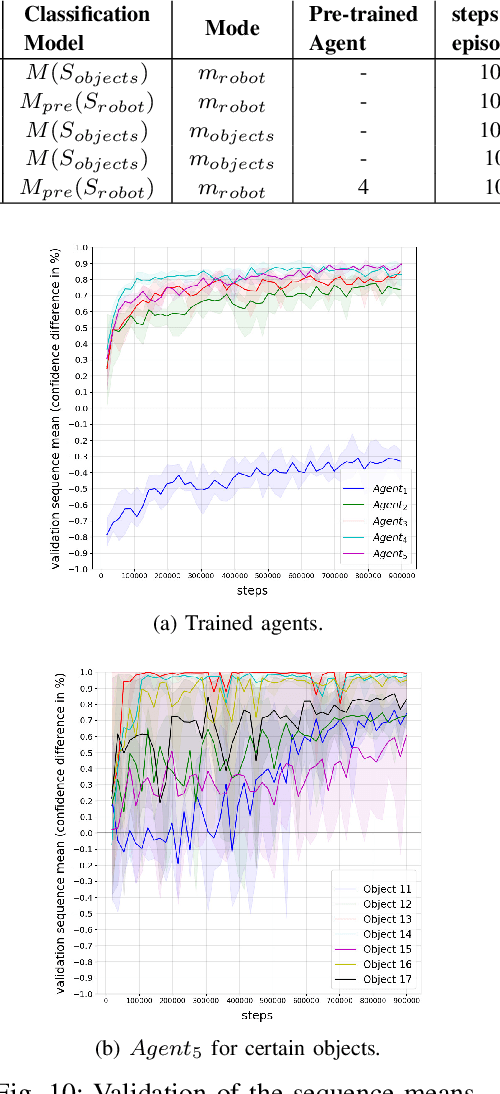
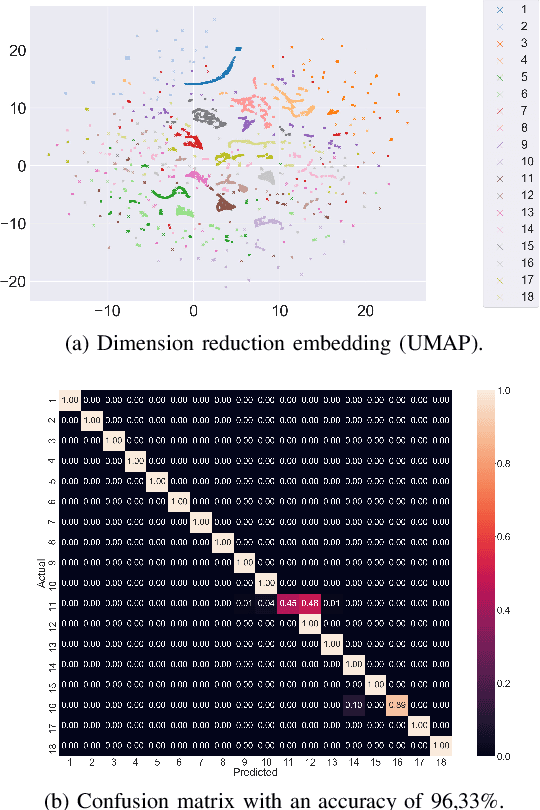
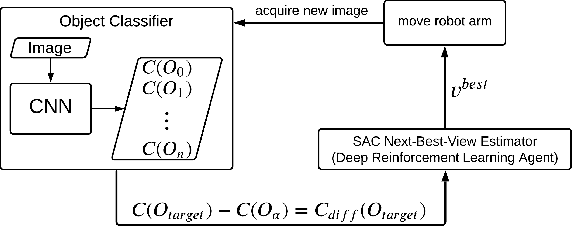
The presentation and analysis of image data from a single viewpoint are often not sufficient to solve a task. Several viewpoints are necessary to obtain more information. The next-best-view problem attempts to find the optimal viewpoint with the greatest information gain for the underlying task. In this work, a robot arm holds an object in its end-effector and searches for a sequence of next-best-view to explicitly identify the object. We use Soft Actor-Critic (SAC), a method of deep reinforcement learning, to learn these next-best-views for a specific set of objects. The evaluation shows that an agent can learn to determine an object pose to which the robot arm should move an object. This leads to a viewpoint that provides a more accurate prediction to distinguish such an object from other objects better. We make the code publicly available for the scientific community and for reproducibility.
Active Observer Visual Problem-Solving Methods are Dynamically Hypothesized, Deployed and Tested
Aug 18, 2021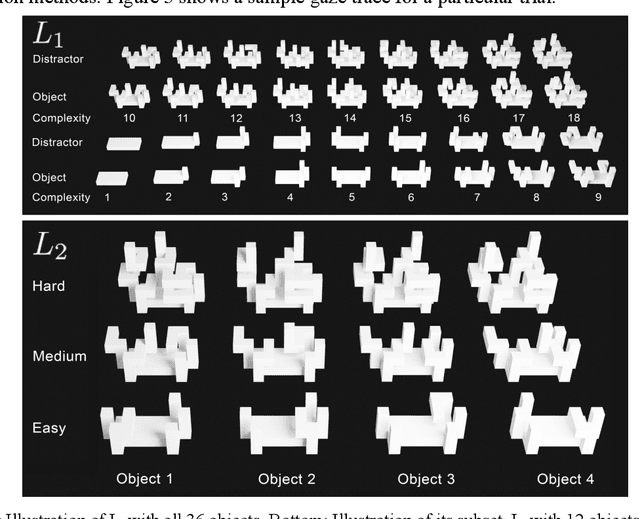
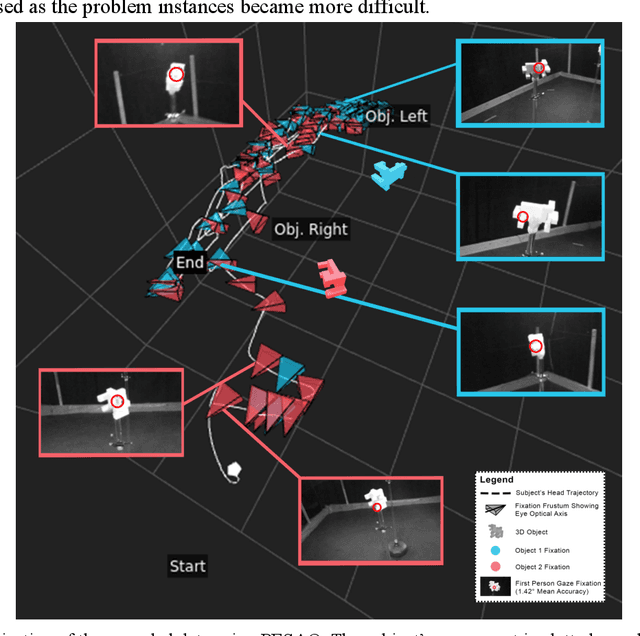
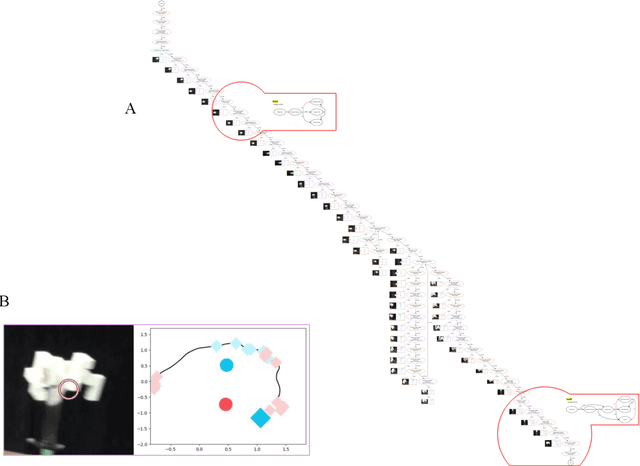
The STAR architecture was designed to test the value of the full Selective Tuning model of visual attention for complex real-world visuospatial tasks and behaviors. However, knowledge of how humans solve such tasks in 3D as active observers is lean. We thus devised a novel experimental setup and examined such behavior. We discovered that humans exhibit a variety of problem-solving strategies whose breadth and complexity are surprising and not easily handled by current methodologies. It is apparent that solution methods are dynamically composed by hypothesizing sequences of actions, testing them, and if they fail, trying different ones. The importance of active observation is striking as is the lack of any learning effect. These results inform our Cognitive Program representation of STAR extending its relevance to real-world tasks.
Blocks World Revisited: The Effect of Self-Occlusion on Classification by Convolutional Neural Networks
Feb 25, 2021


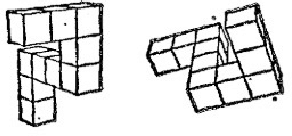
Despite the recent successes in computer vision, there remain new avenues to explore. In this work, we propose a new dataset to investigate the effect of self-occlusion on deep neural networks. With TEOS (The Effect of Self-Occlusion), we propose a 3D blocks world dataset that focuses on the geometric shape of 3D objects and their omnipresent challenge of self-occlusion. We designed TEOS to investigate the role of self-occlusion in the context of object classification. Even though remarkable progress has been seen in object classification, self-occlusion is a challenge. In the real-world, self-occlusion of 3D objects still presents significant challenges for deep learning approaches. However, humans deal with this by deploying complex strategies, for instance, by changing the viewpoint or manipulating the scene to gather necessary information. With TEOS, we present a dataset of two difficulty levels (L1 and L2 ), containing 36 and 12 objects, respectively. We provide 738 uniformly sampled views of each object, their mask, object and camera position, orientation, amount of self-occlusion, as well as the CAD model of each object. We present baseline evaluations with five well-known classification deep neural networks and show that TEOS poses a significant challenge for all of them. The dataset, as well as the pre-trained models, are made publicly available for the scientific community under https://nvision2.data.eecs.yorku.ca/TEOS.
On the Control of Attentional Processes in Vision
Jan 05, 2021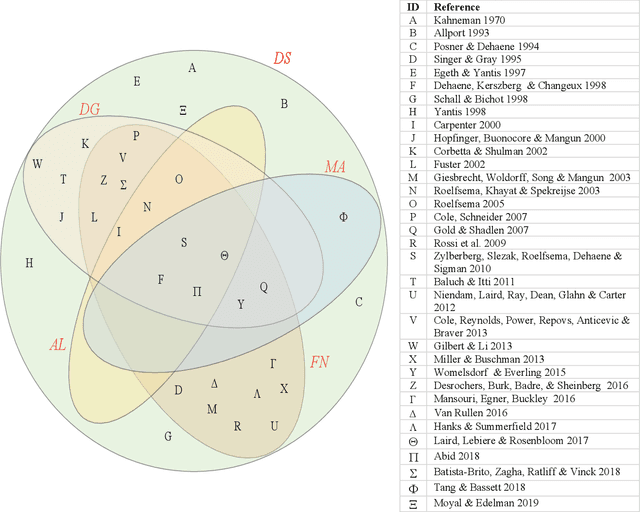
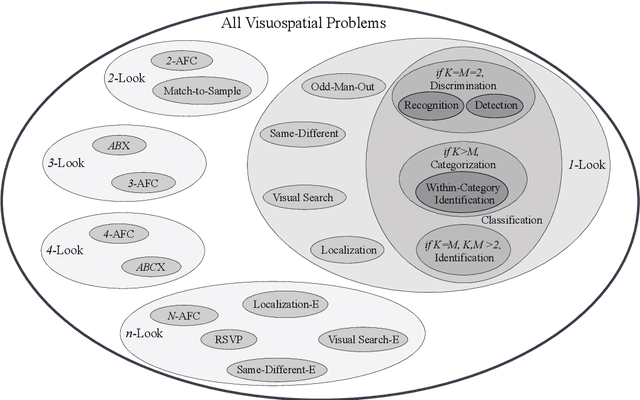

The study of attentional processing in vision has a long and deep history. Recently, several papers have presented insightful perspectives into how the coordination of multiple attentional functions in the brain might occur. These begin with experimental observations and the authors propose structures, processes, and computations that might explain those observations. Here, we consider a perspective that past works have not, as a complementary approach to the experimentally-grounded ones. We approach the same problem as past authors but from the other end of the computational spectrum, from the problem nature, as Marr's Computational Level would prescribe. What problem must the brain solve when orchestrating attentional processes in order to successfully complete one of the myriad possible visuospatial tasks at which we as humans excel? The hope, of course, is for the approaches to eventually meet and thus form a complete theory, but this is likely not soon. We make the first steps towards this by addressing the necessity of attentional control, examining the breadth and computational difficulty of the visuospatial and attentional tasks seen in human behavior, and suggesting a sketch of how attentional control might arise in the brain. The key conclusions of this paper are that an executive controller is necessary for human attentional function in vision, and that there is a 'first principles' computational approach to its understanding that is complementary to the previous approaches that focus on modelling or learning from experimental observations directly.
PESAO: Psychophysical Experimental Setup for Active Observers
Sep 30, 2020
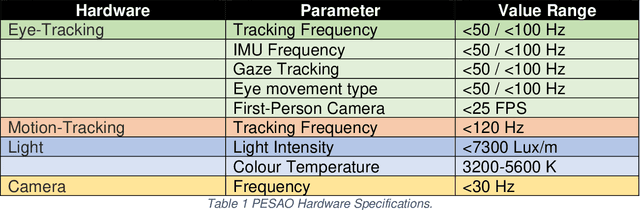


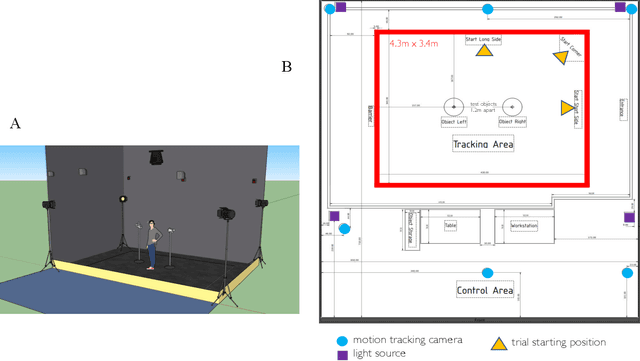
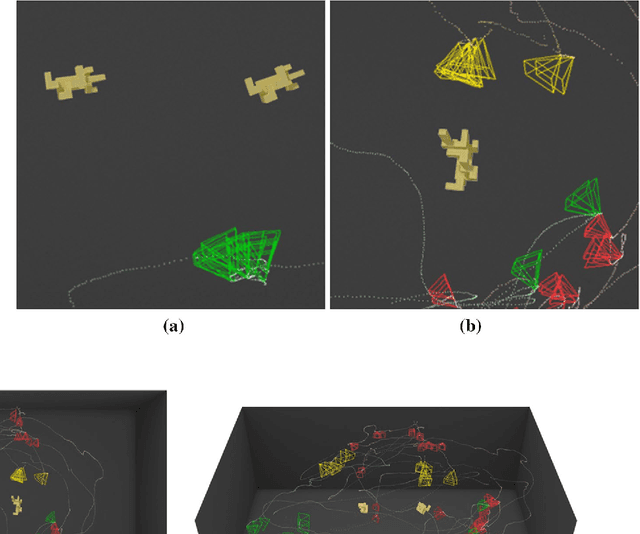
Most past and present research in computer vision involves passively observed data. Humans, however, are active observers outside the lab; they explore, search, select what and how to look. Nonetheless, how exactly active observation occurs in humans so that it can inform the design of active computer vision systems is an open problem. PESAO is designed for investigating active, visual observation in a 3D world. The goal was to build an experimental setup for various active perception tasks with human subjects (active observers) in mind that is capable of tracking the head and gaze. While many studies explore human performances, usually, they use line drawings portrayed in 2D, and no active observer is involved. PESAO allows us to bring many studies to the three-dimensional world, even involving active observers. In our instantiation, it spans an area of 400cm x 300cm and can track active observers at a frequency of 120Hz. Furthermore, PESAO provides tracking and recording of 6D head motion, gaze, eye movement-type, first-person video, head-mounted IMU sensor, birds-eye video, and experimenter notes. All are synchronized at microsecond resolution.
Totally Looks Like - How Humans Compare, Compared to Machines
Oct 18, 2018

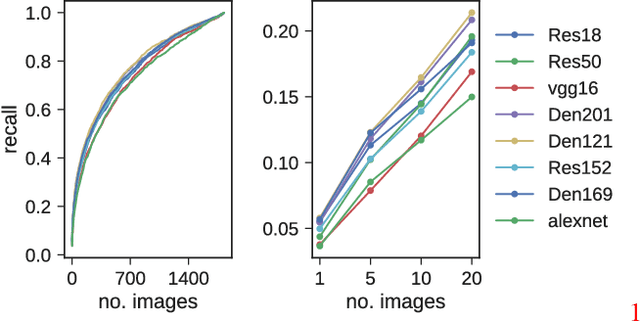
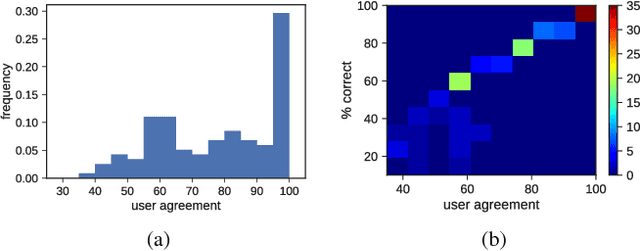
Perceptual judgment of image similarity by humans relies on rich internal representations ranging from low-level features to high-level concepts, scene properties and even cultural associations. However, existing methods and datasets attempting to explain perceived similarity use stimuli which arguably do not cover the full breadth of factors that affect human similarity judgments, even those geared toward this goal. We introduce a new dataset dubbed Totally-Looks-Like (TLL) after a popular entertainment website, which contains images paired by humans as being visually similar. The dataset contains 6016 image-pairs from the wild, shedding light upon a rich and diverse set of criteria employed by human beings. We conduct experiments to try to reproduce the pairings via features extracted from state-of-the-art deep convolutional neural networks, as well as additional human experiments to verify the consistency of the collected data. Though we create conditions to artificially make the matching task increasingly easier, we show that machine-extracted representations perform very poorly in terms of reproducing the matching selected by humans. We discuss and analyze these results, suggesting future directions for improvement of learned image representations.
Visual Attention and its Intimate Links to Spatial Cognition
Jun 29, 2018
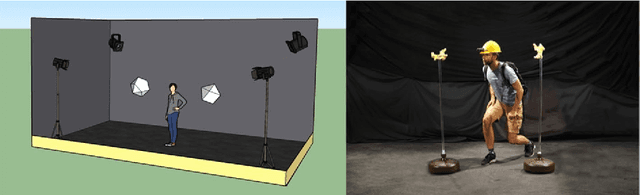

It is almost universal to regard attention as the facility that permits an agent, human or machine, to give priority processing resources to relevant stimuli while ignoring the irrelevant. The reality of how this might manifest itself throughout all the forms of perceptual and cognitive processes possessed by humans, however, is not as clear. Here we examine this reality with a broad perspective in order to highlight the myriad ways that attentional processes impact both perception and cognition. The paper concludes by showing two real world problems that exhibit sufficient complexity to illustrate the ways in which attention and cognition connect. These then point to new avenues of research that might illuminate the overall cognitive architecture of spatial cognition.
Random Polyhedral Scenes: An Image Generator for Active Vision System Experiments
Mar 27, 2018



We present a Polyhedral Scene Generator system which creates a random scene based on a few user parameters, renders the scene from random view points and creates a dataset containing the renderings and corresponding annotation files. We hope that this generator will enable research on how a program could parse a scene if it had multiple viewpoints to consider. For ambiguous scenes, typically people move their head or change their position to see the scene from different angles as well as seeing how it changes while they move; this research field is called active perception. The random scene generator presented is designed to support research in this field by generating images of scenes with known complexity characteristics and with verifiable properties with respect to the distribution of features across a population. Thus, it is well-suited for research in active perception without the requirement of a live 3D environment and mobile sensing agent, including comparative performance evaluations. The system is publicly available at https://polyhedral.eecs.yorku.ca.