 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIJIT: A Robotic Head for an Active Observer
Dec 08, 2025We present DIJIT, a novel binocular robotic head expressly designed for mobile agents that behave as active observers. DIJIT's unique breadth of functionality enables active vision research and the study of human-like eye and head-neck motions, their interrelationships, and how each contributes to visual ability. DIJIT is also being used to explore the differences between how human vision employs eye/head movements to solve visual tasks and current computer vision methods. DIJIT's design features nine mechanical degrees of freedom, while the cameras and lenses provide an additional four optical degrees of freedom. The ranges and speeds of the mechanical design are comparable to human performance. Our design includes the ranges of motion required for convergent stereo, namely, vergence, version, and cyclotorsion. The exploration of the utility of these to both human and machine vision is ongoing. Here, we present the design of DIJIT and evaluate aspects of its performance. We present a new method for saccadic camera movements. In this method, a direct relationship between camera orientation and motor values is developed. The resulting saccadic camera movements are close to human movements in terms of their accuracy.
SNAP: A Benchmark for Testing the Effects of Capture Conditions on Fundamental Vision Tasks
May 21, 2025



Generalization of deep-learning-based (DL) computer vision algorithms to various image perturbations is hard to establish and remains an active area of research. The majority of past analyses focused on the images already captured, whereas effects of the image formation pipeline and environment are less studied. In this paper, we address this issue by analyzing the impact of capture conditions, such as camera parameters and lighting, on DL model performance on 3 vision tasks -- image classification, object detection, and visual question answering (VQA). To this end, we assess capture bias in common vision datasets and create a new benchmark, SNAP (for $\textbf{S}$hutter speed, ISO se$\textbf{N}$sitivity, and $\textbf{AP}$erture), consisting of images of objects taken under controlled lighting conditions and with densely sampled camera settings. We then evaluate a large number of DL vision models and show the effects of capture conditions on each selected vision task. Lastly, we conduct an experiment to establish a human baseline for the VQA task. Our results show that computer vision datasets are significantly biased, the models trained on this data do not reach human accuracy even on the well-exposed images, and are susceptible to both major exposure changes and minute variations of camera settings. Code and data can be found at https://github.com/ykotseruba/SNAP
Statistical Challenges with Dataset Construction: Why You Will Never Have Enough Images
Aug 20, 2024Deep neural networks have achieved impressive performance on many computer vision benchmarks in recent years. However, can we be confident that impressive performance on benchmarks will translate to strong performance in real-world environments? Many environments in the real world are safety critical, and even slight model failures can be catastrophic. Therefore, it is crucial to test models rigorously before deployment. We argue, through both statistical theory and empirical evidence, that selecting representative image datasets for testing a model is likely implausible in many domains. Furthermore, performance statistics calculated with non-representative image datasets are highly unreliable. As a consequence, we cannot guarantee that models which perform well on withheld test images will also perform well in the real world. Creating larger and larger datasets will not help, and bias aware datasets cannot solve this problem either. Ultimately, there is little statistical foundation for evaluating models using withheld test sets. We recommend that future evaluation methodologies focus on assessing a model's decision-making process, rather than metrics such as accuracy.
SCOUT+: Towards Practical Task-Driven Drivers' Gaze Prediction
Apr 12, 2024



Accurate prediction of drivers' gaze is an important component of vision-based driver monitoring and assistive systems. Of particular interest are safety-critical episodes, such as performing maneuvers or crossing intersections. In such scenarios, drivers' gaze distribution changes significantly and becomes difficult to predict, especially if the task and context information is represented implicitly, as is common in many state-of-the-art models. However, explicit modeling of top-down factors affecting drivers' attention often requires additional information and annotations that may not be readily available. In this paper, we address the challenge of effective modeling of task and context with common sources of data for use in practical systems. To this end, we introduce SCOUT+, a task- and context-aware model for drivers' gaze prediction, which leverages route and map information inferred from commonly available GPS data. We evaluate our model on two datasets, DR(eye)VE and BDD-A, and demonstrate that using maps improves results compared to bottom-up models and reaches performance comparable to the top-down model SCOUT which relies on privileged ground truth information. Code is available at https://github.com/ykotseruba/SCOUT.
Data Limitations for Modeling Top-Down Effects on Drivers' Attention
Apr 12, 2024



Driving is a visuomotor task, i.e., there is a connection between what drivers see and what they do. While some models of drivers' gaze account for top-down effects of drivers' actions, the majority learn only bottom-up correlations between human gaze and driving footage. The crux of the problem is lack of public data with annotations that could be used to train top-down models and evaluate how well models of any kind capture effects of task on attention. As a result, top-down models are trained and evaluated on private data and public benchmarks measure only the overall fit to human data. In this paper, we focus on data limitations by examining four large-scale public datasets, DR(eye)VE, BDD-A, MAAD, and LBW, used to train and evaluate algorithms for drivers' gaze prediction. We define a set of driving tasks (lateral and longitudinal maneuvers) and context elements (intersections and right-of-way) known to affect drivers' attention, augment the datasets with annotations based on the said definitions, and analyze the characteristics of data recording and processing pipelines w.r.t. capturing what the drivers see and do. In sum, the contributions of this work are: 1) quantifying biases of the public datasets, 2) examining performance of the SOTA bottom-up models on subsets of the data involving non-trivial drivers' actions, 3) linking shortcomings of the bottom-up models to data limitations, and 4) recommendations for future data collection and processing. The new annotations and code for reproducing the results is available at https://github.com/ykotseruba/SCOUT.
Understanding and Modeling the Effects of Task and Context on Drivers' Gaze Allocation
Oct 23, 2023



Understanding what drivers look at is important for many applications, including driver training, monitoring, and assistance, as well as self-driving. Traditionally, factors affecting human visual attention have been divided into bottom-up (involuntary attraction to salient regions) and top-down (task- and context-driven). Although both play a role in drivers' gaze allocation, most of the existing modeling approaches apply techniques developed for bottom-up saliency and do not consider task and context influences explicitly. Likewise, common driving attention benchmarks lack relevant task and context annotations. Therefore, to enable analysis and modeling of these factors for drivers' gaze prediction, we propose the following: 1) address some shortcomings of the popular DR(eye)VE dataset and extend it with per-frame annotations for driving task and context; 2) benchmark a number of baseline and SOTA models for saliency and driver gaze prediction and analyze them w.r.t. the new annotations; and finally, 3) a novel model that modulates drivers' gaze prediction with explicit action and context information, and as a result significantly improves SOTA performance on DR(eye)VE overall (by 24\% KLD and 89\% NSS) and on a subset of action and safety-critical intersection scenarios (by 10--30\% KLD). Extended annotations, code for model and evaluation will be made publicly available.
The Psychophysics of Human Three-Dimensional Active Visuospatial Problem-Solving
Jun 19, 2023Our understanding of how visual systems detect, analyze and interpret visual stimuli has advanced greatly. However, the visual systems of all animals do much more; they enable visual behaviours. How well the visual system performs while interacting with the visual environment and how vision is used in the real world have not been well studied, especially in humans. It has been suggested that comparison is the most primitive of psychophysical tasks. Thus, as a probe into these active visual behaviours, we use a same-different task: are two physical 3D objects visually the same? This task seems to be a fundamental cognitive ability. We pose this question to human subjects who are free to move about and examine two real objects in an actual 3D space. Past work has dealt solely with a 2D static version of this problem. We have collected detailed, first-of-its-kind data of humans performing a visuospatial task in hundreds of trials. Strikingly, humans are remarkably good at this task without any training, with a mean accuracy of 93.82%. No learning effect was observed on accuracy after many trials, but some effect was seen for response time, number of fixations and extent of head movement. Subjects demonstrated a variety of complex strategies involving a range of movement and eye fixation changes, suggesting that solutions were developed dynamically and tailored to the specific task.
Self-attention in Vision Transformers Performs Perceptual Grouping, Not Attention
Mar 02, 2023Recently, a considerable number of studies in computer vision involves deep neural architectures called vision transformers. Visual processing in these models incorporates computational models that are claimed to implement attention mechanisms. Despite an increasing body of work that attempts to understand the role of attention mechanisms in vision transformers, their effect is largely unknown. Here, we asked if the attention mechanisms in vision transformers exhibit similar effects as those known in human visual attention. To answer this question, we revisited the attention formulation in these models and found that despite the name, computationally, these models perform a special class of relaxation labeling with similarity grouping effects. Additionally, whereas modern experimental findings reveal that human visual attention involves both feed-forward and feedback mechanisms, the purely feed-forward architecture of vision transformers suggests that attention in these models will not have the same effects as those known in humans. To quantify these observations, we evaluated grouping performance in a family of vision transformers. Our results suggest that self-attention modules group figures in the stimuli based on similarity in visual features such as color. Also, in a singleton detection experiment as an instance of saliency detection, we studied if these models exhibit similar effects as those of feed-forward visual salience mechanisms utilized in human visual attention. We found that generally, the transformer-based attention modules assign more salience either to distractors or the ground. Together, our study suggests that the attention mechanisms in vision transformers perform similarity grouping and not attention.
Learning a model of shape selectivity in V4 cells reveals shape encoding mechanisms in the brain
Dec 13, 2021
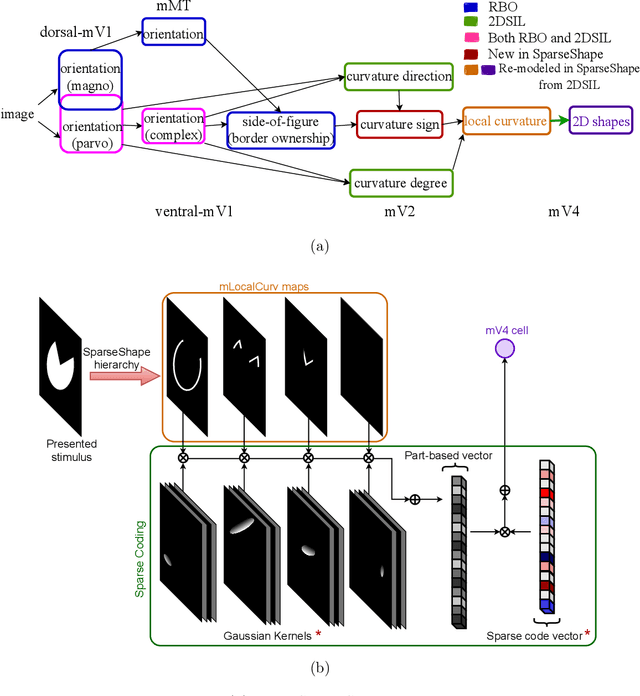
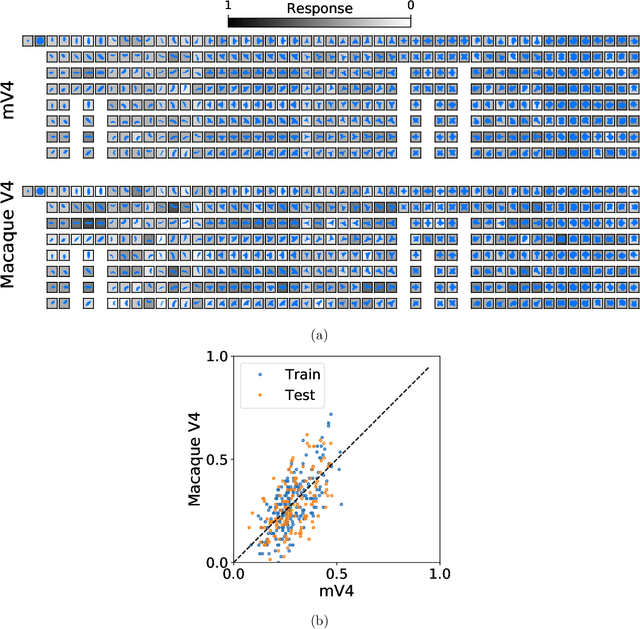
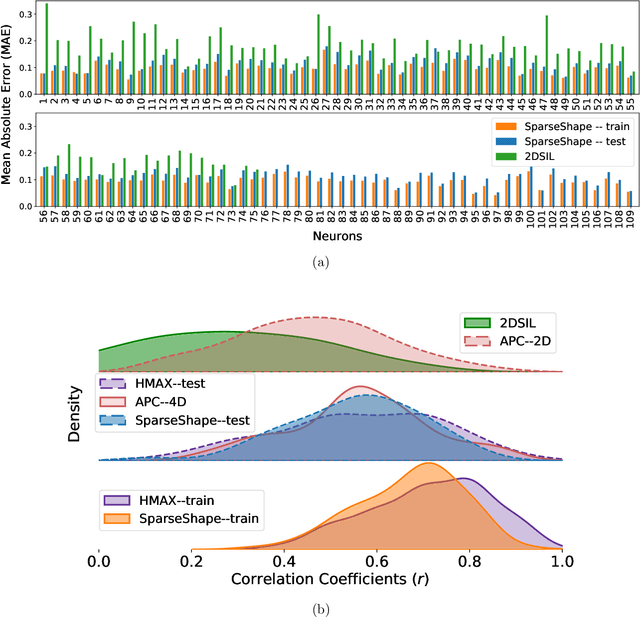
The mechanisms involved in transforming early visual signals to curvature representations in V4 are unknown. We propose a hierarchical model that reveals V1/V2 encodings that are essential components for this transformation to the reported curvature representations in V4. Then, by relaxing the often-imposed prior of a single Gaussian, V4 shape selectivity is learned in the last layer of the hierarchy from Macaque V4 responses. We found that V4 cells integrate multiple shape parts from the full spatial extent of their receptive fields with similar excitatory and inhibitory contributions. Our results uncover new details in existing data about shape selectivity in V4 neurons that with further experiments can enhance our understanding of processing in this area. Accordingly, we propose designs for a stimulus set that allow removing shape parts without disturbing the curvature signal to isolate part contributions to V4 responses.
Next-Best-View Estimation based on Deep Reinforcement Learning for Active Object Classification
Oct 14, 2021
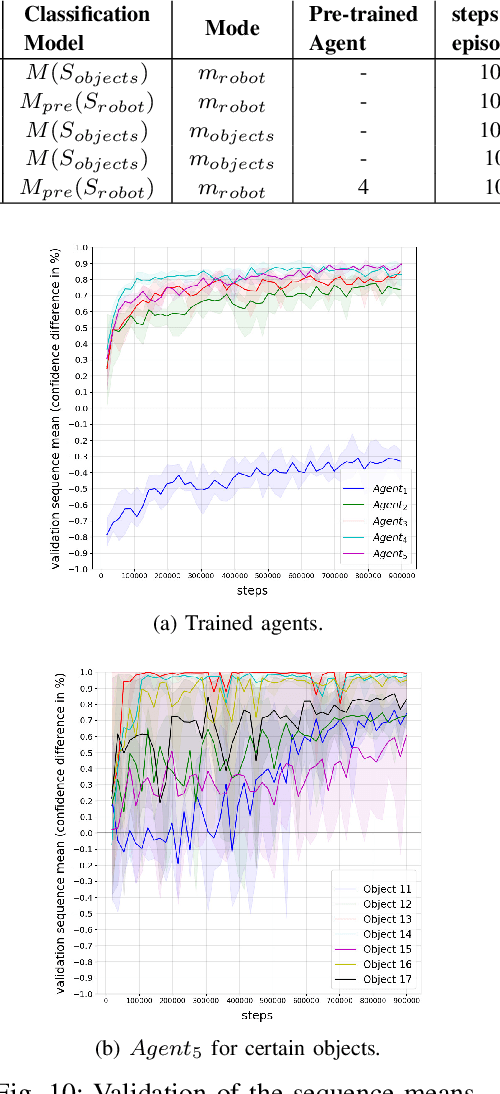
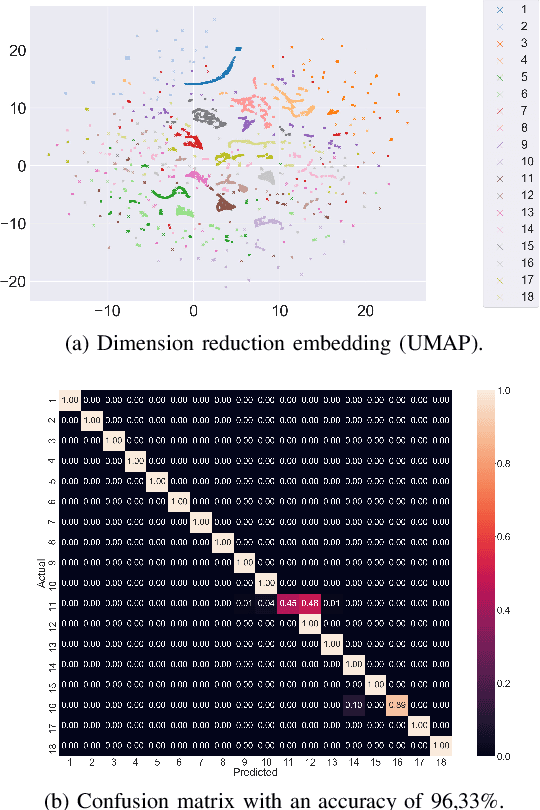
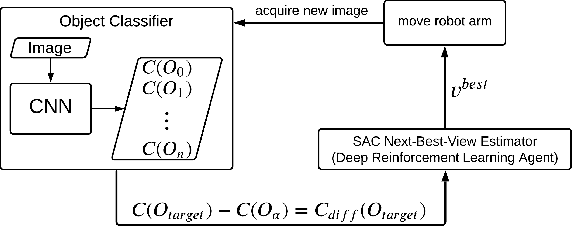
The presentation and analysis of image data from a single viewpoint are often not sufficient to solve a task. Several viewpoints are necessary to obtain more information. The next-best-view problem attempts to find the optimal viewpoint with the greatest information gain for the underlying task. In this work, a robot arm holds an object in its end-effector and searches for a sequence of next-best-view to explicitly identify the object. We use Soft Actor-Critic (SAC), a method of deep reinforcement learning, to learn these next-best-views for a specific set of objects. The evaluation shows that an agent can learn to determine an object pose to which the robot arm should move an object. This leads to a viewpoint that provides a more accurate prediction to distinguish such an object from other objects better. We make the code publicly available for the scientific community and for reproducibility.