 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpinal ligaments detection on vertebrae meshes using registration and 3D edge detection
Dec 06, 2024



Spinal ligaments are crucial elements in the complex biomechanical simulation models as they transfer forces on the bony structure, guide and limit movements and stabilize the spine. The spinal ligaments encompass seven major groups being responsible for maintaining functional interrelationships among the other spinal components. Determination of the ligament origin and insertion points on the 3D vertebrae models is an essential step in building accurate and complex spine biomechanical models. In our paper, we propose a pipeline that is able to detect 66 spinal ligament attachment points by using a step-wise approach. Our method incorporates a fast vertebra registration that strategically extracts only 15 3D points to compute the transformation, and edge detection for a precise projection of the registered ligaments onto any given patient-specific vertebra model. Our method shows high accuracy, particularly in identifying landmarks on the anterior part of the vertebra with an average distance of 2.24 mm for anterior longitudinal ligament and 1.26 mm for posterior longitudinal ligament landmarks. The landmark detection requires approximately 3.0 seconds per vertebra, providing a substantial improvement over existing methods. Clinical relevance: using the proposed method, the required landmarks that represent origin and insertion points for forces in the biomechanical spine models can be localized automatically in an accurate and time-efficient manner.
Reconstruction of 3D lumbar spine models from incomplete segmentations using landmark detection
Dec 06, 2024



Patient-specific 3D spine models serve as a foundation for spinal treatment and surgery planning as well as analysis of loading conditions in biomechanical and biomedical research. Despite advancements in imaging technologies, the reconstruction of complete 3D spine models often faces challenges due to limitations in imaging modalities such as planar X-Ray and missing certain spinal structures, such as the spinal or transverse processes, in volumetric medical images and resulting segmentations. In this study, we present a novel accurate and time-efficient method to reconstruct complete 3D lumbar spine models from incomplete 3D vertebral bodies obtained from segmented magnetic resonance images (MRI). In our method, we use an affine transformation to align artificial vertebra models with patient-specific incomplete vertebrae. The transformation matrix is derived from vertebra landmarks, which are automatically detected on the vertebra endplates. The results of our evaluation demonstrate the high accuracy of the performed registration, achieving an average point-to-model distance of 1.95 mm. Additionally, in assessing the morphological properties of the vertebrae and intervertebral characteristics, our method demonstrated a mean absolute error (MAE) of 3.4{\deg} in the angles of functional spine units (FSUs), emphasizing its effectiveness in maintaining important spinal features throughout the transformation process of individual vertebrae. Our method achieves the registration of the entire lumbar spine, spanning segments L1 to L5, in just 0.14 seconds, showcasing its time-efficiency. Clinical relevance: the fast and accurate reconstruction of spinal models from incomplete input data such as segmentations provides a foundation for many applications in spine diagnostics, treatment planning, and the development of spinal healthcare solutions.
HS3-Bench: A Benchmark and Strong Baseline for Hyperspectral Semantic Segmentation in Driving Scenarios
Sep 17, 2024



Semantic segmentation is an essential step for many vision applications in order to understand a scene and the objects within. Recent progress in hyperspectral imaging technology enables the application in driving scenarios and the hope is that the devices perceptive abilities provide an advantage over RGB-cameras. Even though some datasets exist, there is no standard benchmark available to systematically measure progress on this task and evaluate the benefit of hyperspectral data. In this paper, we work towards closing this gap by providing the HyperSpectral Semantic Segmentation benchmark (HS3-Bench). It combines annotated hyperspectral images from three driving scenario datasets and provides standardized metrics, implementations, and evaluation protocols. We use the benchmark to derive two strong baseline models that surpass the previous state-of-the-art performances with and without pre-training on the individual datasets. Further, our results indicate that the existing learning-based methods benefit more from leveraging additional RGB training data than from leveraging the additional hyperspectral channels. This poses important questions for future research on hyperspectral imaging for semantic segmentation in driving scenarios. Code to run the benchmark and the strong baseline approaches are available under https://github.com/nickstheisen/hyperseg.
3D Vertebrae Measurements: Assessing Vertebral Dimensions in Human Spine Mesh Models Using Local Anatomical Vertebral Axes
Feb 02, 2024



Vertebral morphological measurements are important across various disciplines, including spinal biomechanics and clinical applications, pre- and post-operatively. These measurements also play a crucial role in anthropological longitudinal studies, where spinal metrics are repeatedly documented over extended periods. Traditionally, such measurements have been manually conducted, a process that is time-consuming. In this study, we introduce a novel, fully automated method for measuring vertebral morphology using 3D meshes of lumbar and thoracic spine models.Our experimental results demonstrate the method's capability to accurately measure low-resolution patient-specific vertebral meshes with mean absolute error (MAE) of 1.09 mm and those derived from artificially created lumbar spines, where the average MAE value was 0.7 mm. Our qualitative analysis indicates that measurements obtained using our method on 3D spine models can be accurately reprojected back onto the original medical images if these images are available.
Generation of Synthetic Images for Pedestrian Detection Using a Sequence of GANs
Jan 14, 2024Creating annotated datasets demands a substantial amount of manual effort. In this proof-of-concept work, we address this issue by proposing a novel image generation pipeline. The pipeline consists of three distinct generative adversarial networks (previously published), combined in a novel way to augment a dataset for pedestrian detection. Despite the fact that the generated images are not always visually pleasant to the human eye, our detection benchmark reveals that the results substantially surpass the baseline. The presented proof-of-concept work was done in 2020 and is now published as a technical report after a three years retention period.
Next-Best-View Estimation based on Deep Reinforcement Learning for Active Object Classification
Oct 14, 2021
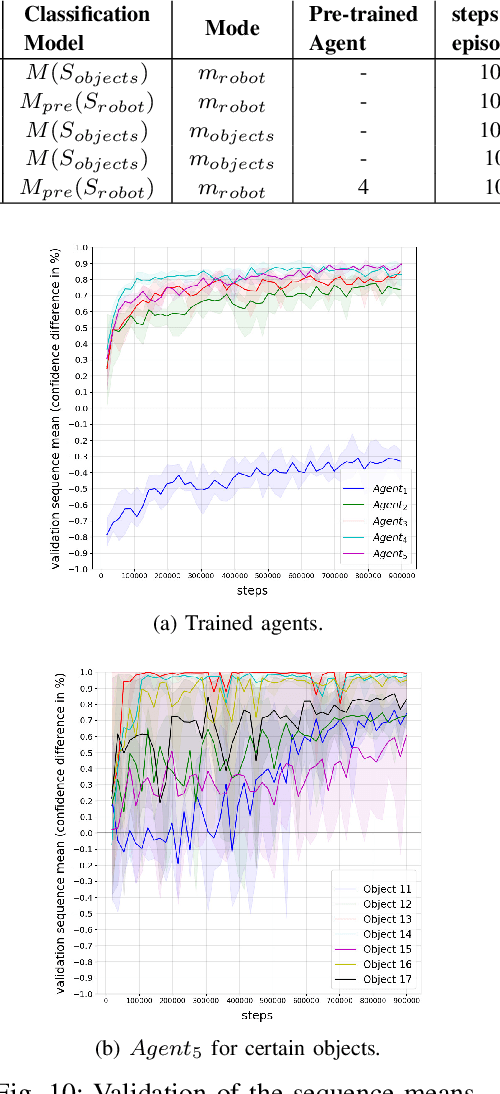
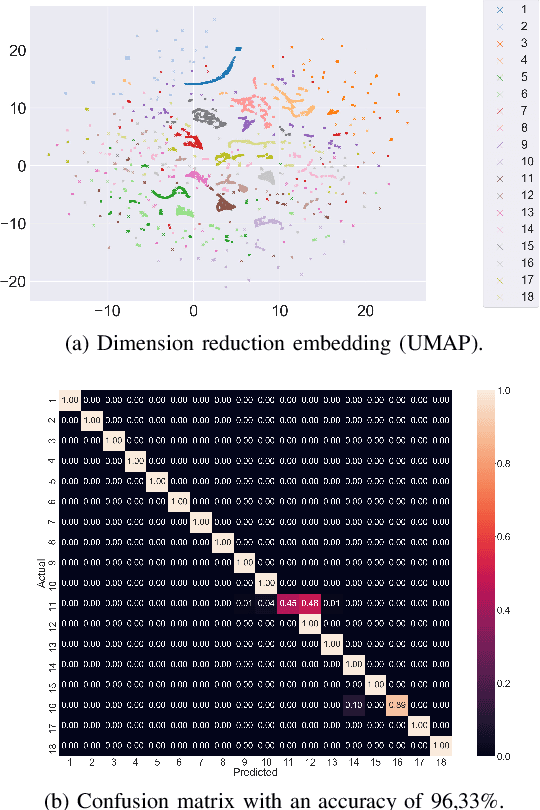
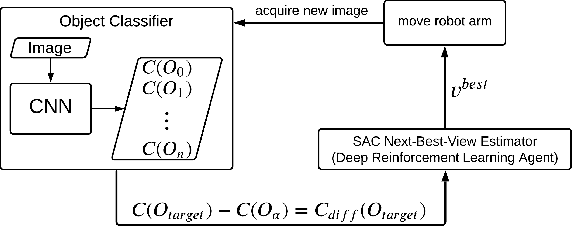
The presentation and analysis of image data from a single viewpoint are often not sufficient to solve a task. Several viewpoints are necessary to obtain more information. The next-best-view problem attempts to find the optimal viewpoint with the greatest information gain for the underlying task. In this work, a robot arm holds an object in its end-effector and searches for a sequence of next-best-view to explicitly identify the object. We use Soft Actor-Critic (SAC), a method of deep reinforcement learning, to learn these next-best-views for a specific set of objects. The evaluation shows that an agent can learn to determine an object pose to which the robot arm should move an object. This leads to a viewpoint that provides a more accurate prediction to distinguish such an object from other objects better. We make the code publicly available for the scientific community and for reproducibility.
Fusion-GCN: Multimodal Action Recognition using Graph Convolutional Networks
Sep 27, 2021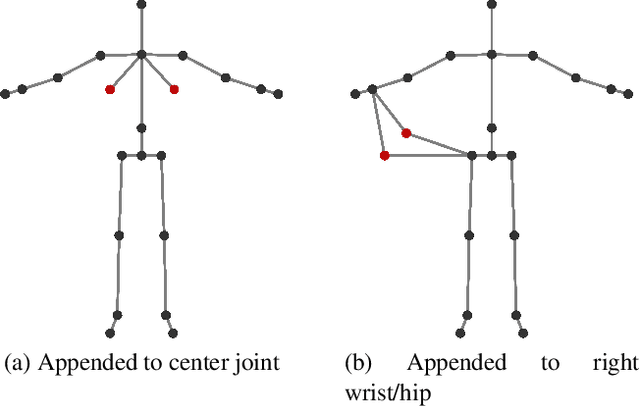
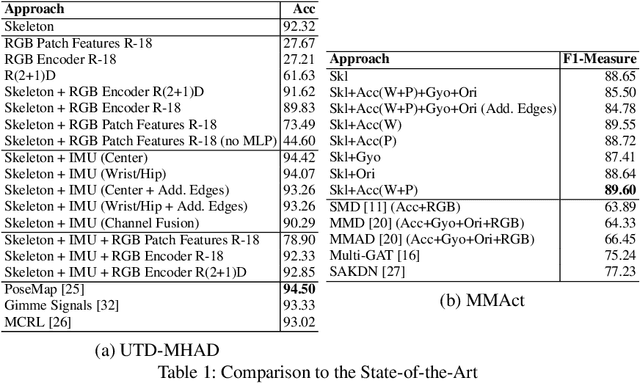
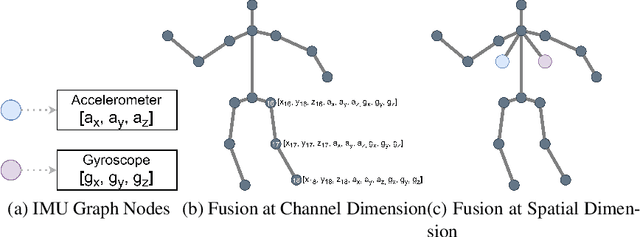
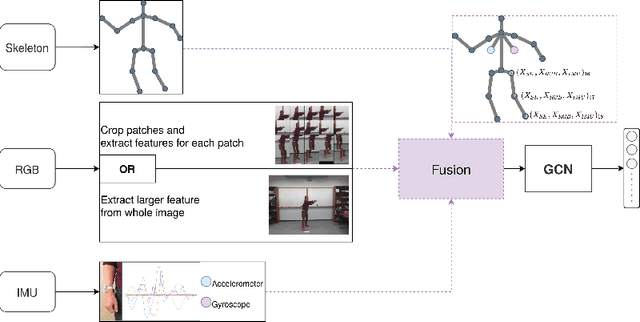
In this paper, we present Fusion-GCN, an approach for multimodal action recognition using Graph Convolutional Networks (GCNs). Action recognition methods based around GCNs recently yielded state-of-the-art performance for skeleton-based action recognition. With Fusion-GCN, we propose to integrate various sensor data modalities into a graph that is trained using a GCN model for multi-modal action recognition. Additional sensor measurements are incorporated into the graph representation, either on a channel dimension (introducing additional node attributes) or spatial dimension (introducing new nodes). Fusion-GCN was evaluated on two public available datasets, the UTD-MHAD- and MMACT datasets, and demonstrates flexible fusion of RGB sequences, inertial measurements and skeleton sequences. Our approach gets comparable results on the UTD-MHAD dataset and improves the baseline on the large-scale MMACT dataset by a significant margin of up to 12.37% (F1-Measure) with the fusion of skeleton estimates and accelerometer measurements.
Skeleton-DML: Deep Metric Learning for Skeleton-Based One-Shot Action Recognition
Dec 26, 2020

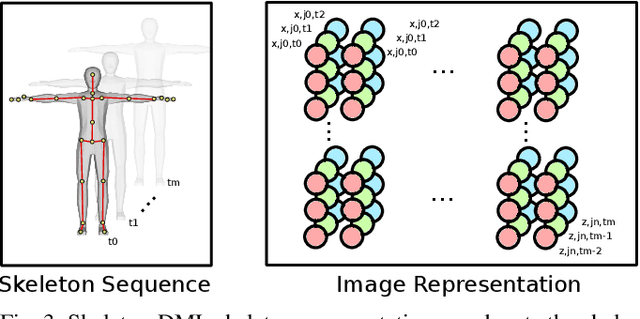
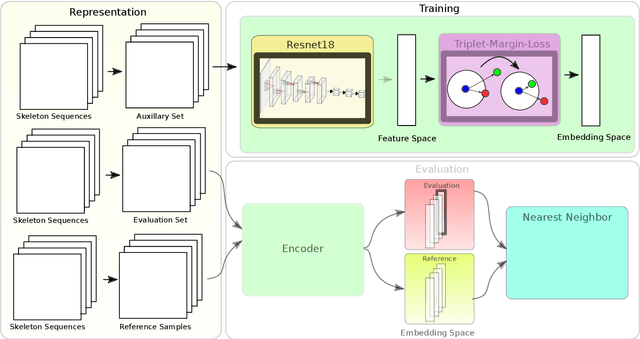
One-shot action recognition allows the recognition of human-performed actions with only a single training example. This can influence human-robot-interaction positively by enabling the robot to react to previously unseen behaviour. We formulate the one-shot action recognition problem as a deep metric learning problem and propose a novel image-based skeleton representation that performs well in a metric learning setting. Therefore, we train a model that projects the image representations into an embedding space. In embedding space the similar actions have a low euclidean distance while dissimilar actions have a higher distance. The one-shot action recognition problem becomes a nearest-neighbor search in a set of activity reference samples. We evaluate the performance of our proposed representation against a variety of other skeleton-based image representations. In addition, we present an ablation study that shows the influence of different embedding vector sizes, losses and augmentation. Our approach lifts the state-of-the-art by 3.3% for the one-shot action recognition protocol on the NTU RGB+D 120 dataset under a comparable training setup. With additional augmentation our result improved over 7.7%.
Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
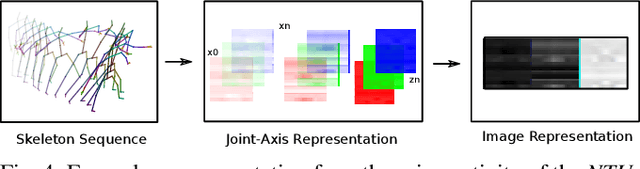
Apr 28, 2020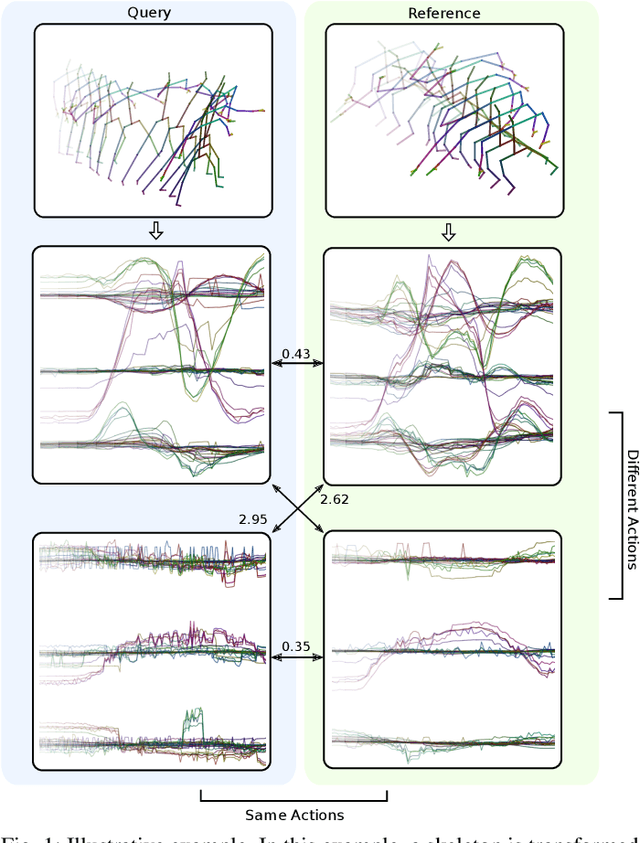

Recognizing an activity with a single reference sample using metric learning approaches is a promising research field. The majority of few-shot methods focus on object recognition or face-identification. We follow a metric learning approach to reduce the action recognition problem to a nearest neighbor search in embedding space. We encode signals on a signal level into images and then extract features using a deep residual CNN. Using triplet loss, we learn a feature embedding. The resulting encoder transforms features into an embedding space in which closer distances encode similar actions while higher distances encode different actions. Our approach based on a signal-level formulation remains flexible across a variety of modalities while outperforming the baseline on the large scale NTU RGB+D 120 dataset for the One-Shot action recognition protocol by 4.2%. Further, we show generalization on experiments using the UTD-MHAD dataset for inertial data and the Simitate dataset for motion capturing data. Furthermore, our inter-joint and inter-sensor experiments suggest good capabilities on previously unseen joint and sensor setups.
Gimme Signals: Discriminative signal encoding for multimodal activity recognition
Apr 09, 2020



We present a simple, yet effective and flexible method for action recognition supporting multiple sensor modalities. Multivariate signal sequences are encoded in an image and are then classified using a recently proposed EfficientNet CNN architecture. Our focus was to find an approach that generalizes well across different sensor modalities without specific adaptions while still achieving good results. We apply our method to 4 action recognition datasets containing skeleton sequences, inertial and motion capturing measurements as well as \wifi fingerprints that range up to 120 action classes. Our method defines the current best CNN-based approach on the NTU RGB+D 120 dataset, lifts the state of the art on the ARIL Wi-Fi dataset by +6.78%, improves the UTD-MHAD inertial baseline by +14.4%, the UTD-MHAD skeleton baseline by 1.13% and achieves 96.11% on the Simitate motion capturing data (80/20 split). We further demonstrate experiments on both, modality fusion on a signal level and signal reduction to prevent the representation from overloading.