 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHS3-Bench: A Benchmark and Strong Baseline for Hyperspectral Semantic Segmentation in Driving Scenarios
Sep 17, 2024



Semantic segmentation is an essential step for many vision applications in order to understand a scene and the objects within. Recent progress in hyperspectral imaging technology enables the application in driving scenarios and the hope is that the devices perceptive abilities provide an advantage over RGB-cameras. Even though some datasets exist, there is no standard benchmark available to systematically measure progress on this task and evaluate the benefit of hyperspectral data. In this paper, we work towards closing this gap by providing the HyperSpectral Semantic Segmentation benchmark (HS3-Bench). It combines annotated hyperspectral images from three driving scenario datasets and provides standardized metrics, implementations, and evaluation protocols. We use the benchmark to derive two strong baseline models that surpass the previous state-of-the-art performances with and without pre-training on the individual datasets. Further, our results indicate that the existing learning-based methods benefit more from leveraging additional RGB training data than from leveraging the additional hyperspectral channels. This poses important questions for future research on hyperspectral imaging for semantic segmentation in driving scenarios. Code to run the benchmark and the strong baseline approaches are available under https://github.com/nickstheisen/hyperseg.
FETCH: A Memory-Efficient Replay Approach for Continual Learning in Image Classification
Jul 17, 2024Class-incremental continual learning is an important area of research, as static deep learning methods fail to adapt to changing tasks and data distributions. In previous works, promising results were achieved using replay and compressed replay techniques. In the field of regular replay, GDumb achieved outstanding results but requires a large amount of memory. This problem can be addressed by compressed replay techniques. The goal of this work is to evaluate compressed replay in the pipeline of GDumb. We propose FETCH, a two-stage compression approach. First, the samples from the continual datastream are encoded by the early layers of a pre-trained neural network. Second, the samples are compressed before being stored in the episodic memory. Following GDumb, the remaining classification head is trained from scratch using only the decompressed samples from the reply memory. We evaluate FETCH in different scenarios and show that this approach can increase accuracy on CIFAR10 and CIFAR100. In our experiments, simple compression methods (e.g., quantization of tensors) outperform deep autoencoders. In the future, FETCH could serve as a baseline for benchmarking compressed replay learning in constrained memory scenarios.
* Submitted Version for IDEAL 2023
Towards Revisiting Visual Place Recognition for Joining Submaps in Multimap SLAM
Jul 17, 2024Visual SLAM is a key technology for many autonomous systems. However, tracking loss can lead to the creation of disjoint submaps in multimap SLAM systems like ORB-SLAM3. Because of that, these systems employ submap merging strategies. As we show, these strategies are not always successful. In this paper, we investigate the impact of using modern VPR approaches for submap merging in visual SLAM. We argue that classical evaluation metrics are not sufficient to estimate the impact of a modern VPR component on the overall system. We show that naively replacing the VPR component does not leverage its full potential without requiring substantial interference in the original system. Because of that, we present a post-processing pipeline along with a set of metrics that allow us to estimate the impact of modern VPR components. We evaluate our approach on the NCLT and Newer College datasets using ORB-SLAM3 with NetVLAD and HDC-DELF as VPR components. Additionally, we present a simple approach for combining VPR with temporal consistency for map merging. We show that the map merging performance of ORB-SLAM3 can be improved. Building on these results, researchers in VPR can assess the potential of their approaches for SLAM systems.
Local positional graphs and attentive local features for a data and runtime-efficient hierarchical place recognition pipeline
Mar 15, 2024Large-scale applications of Visual Place Recognition (VPR) require computationally efficient approaches. Further, a well-balanced combination of data-based and training-free approaches can decrease the required amount of training data and effort and can reduce the influence of distribution shifts between the training and application phases. This paper proposes a runtime and data-efficient hierarchical VPR pipeline that extends existing approaches and presents novel ideas. There are three main contributions: First, we propose Local Positional Graphs (LPG), a training-free and runtime-efficient approach to encode spatial context information of local image features. LPG can be combined with existing local feature detectors and descriptors and considerably improves the image-matching quality compared to existing techniques in our experiments. Second, we present Attentive Local SPED (ATLAS), an extension of our previous local features approach with an attention module that improves the feature quality while maintaining high data efficiency. The influence of the proposed modifications is evaluated in an extensive ablation study. Third, we present a hierarchical pipeline that exploits hyperdimensional computing to use the same local features as holistic HDC-descriptors for fast candidate selection and for candidate reranking. We combine all contributions in a runtime and data-efficient VPR pipeline that shows benefits over the state-of-the-art method Patch-NetVLAD on a large collection of standard place recognition datasets with 15$\%$ better performance in VPR accuracy, 54$\times$ faster feature comparison speed, and 55$\times$ less descriptor storage occupancy, making our method promising for real-world high-performance large-scale VPR in changing environments. Code will be made available with publication of this paper.
HealthWalk: Promoting Health and Mobility through Sensor-Based Rollator Walker Assistance
Oct 11, 2023

Rollator walkers allow people with physical limitations to increase their mobility and give them the confidence and independence to participate in society for longer. However, rollator walker users often have poor posture, leading to further health problems and, in the worst case, falls. Integrating sensors into rollator walker designs can help to address this problem and results in a platform that allows several other interesting use cases. This paper briefly overviews existing systems and the current research directions and challenges in this field. We also present our early HealthWalk rollator walker prototype for data collection with older people, rheumatism, multiple sclerosis and Parkinson patients, and individuals with visual impairments.
Visual Place Recognition: A Tutorial
Mar 06, 2023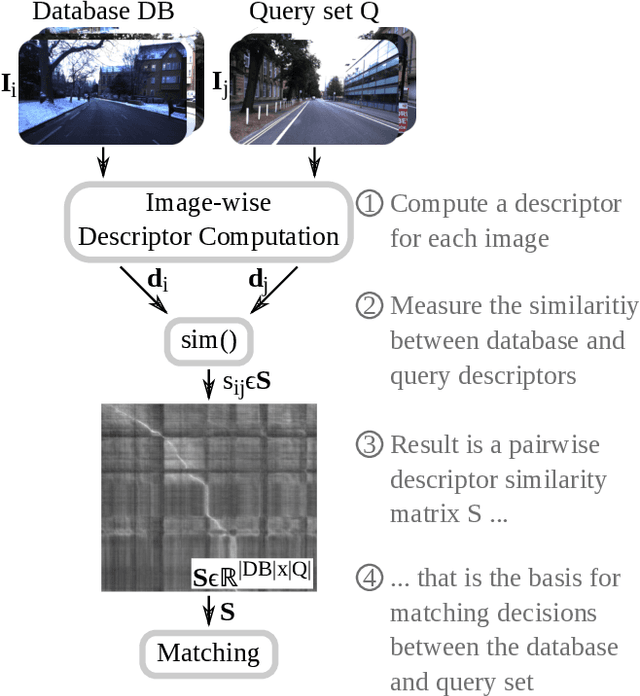
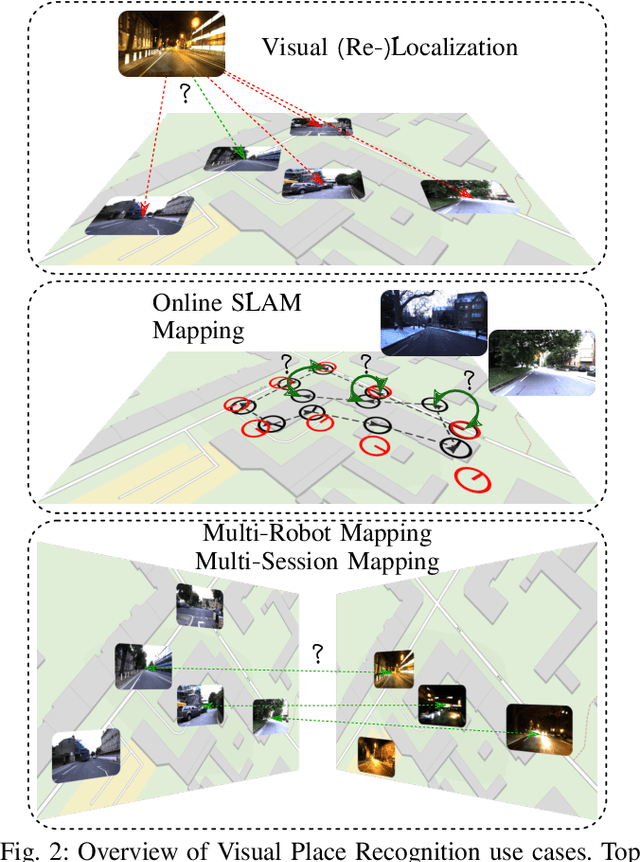
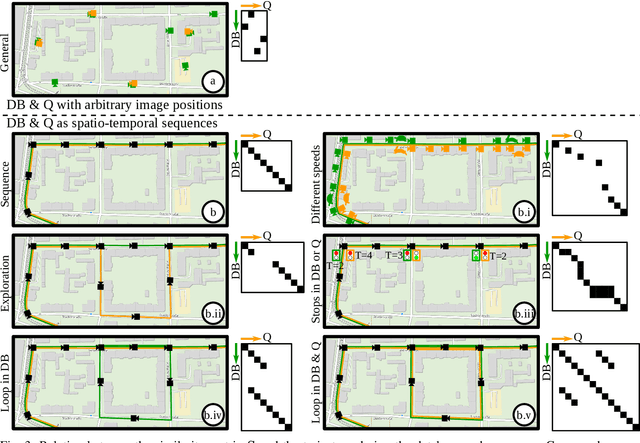

Localization is an essential capability for mobile robots. A rapidly growing field of research in this area is Visual Place Recognition (VPR), which is the ability to recognize previously seen places in the world based solely on images. This present work is the first tutorial paper on visual place recognition. It unifies the terminology of VPR and complements prior research in two important directions: 1) It provides a systematic introduction for newcomers to the field, covering topics such as the formulation of the VPR problem, a general-purpose algorithmic pipeline, an evaluation methodology for VPR approaches, and the major challenges for VPR and how they may be addressed. 2) As a contribution for researchers acquainted with the VPR problem, it examines the intricacies of different VPR problem types regarding input, data processing, and output. The tutorial also discusses the subtleties behind the evaluation of VPR algorithms, e.g., the evaluation of a VPR system that has to find all matching database images per query, as opposed to just a single match. Practical code examples in Python illustrate to prospective practitioners and researchers how VPR is implemented and evaluated.
HDC-MiniROCKET: Explicit Time Encoding in Time Series Classification with Hyperdimensional Computing
Feb 16, 2022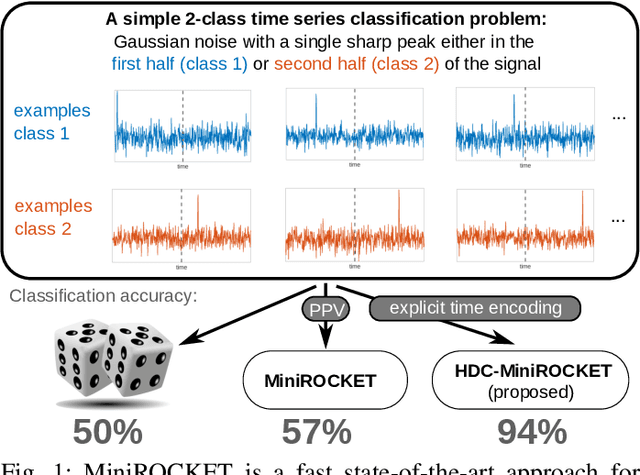
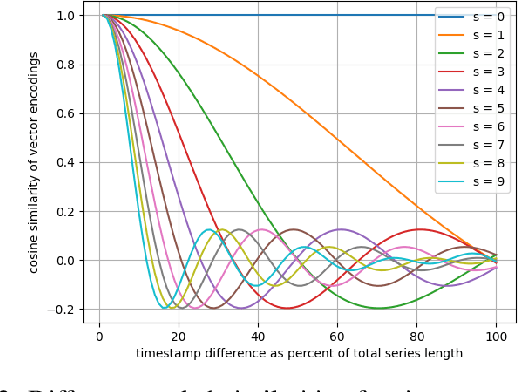
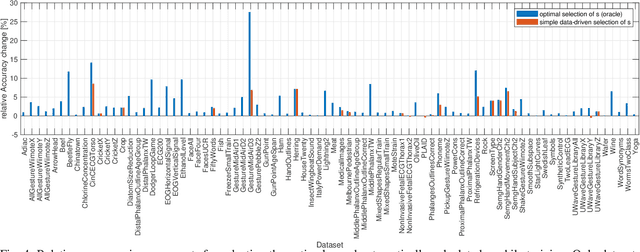
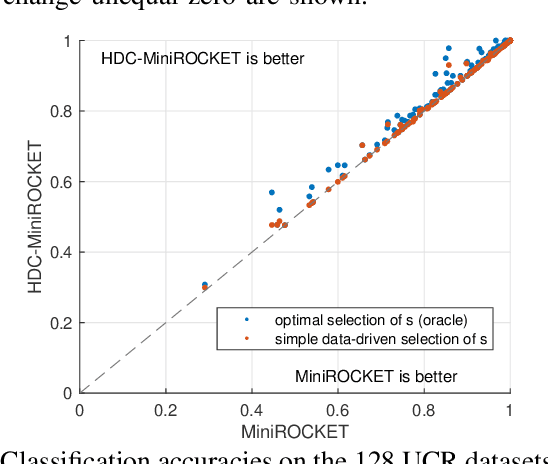
Classification of time series data is an important task for many application domains. One of the best existing methods for this task, in terms of accuracy and computation time, is MiniROCKET. In this work, we extend this approach to provide better global temporal encodings using hyperdimensional computing (HDC) mechanisms. HDC (also known as Vector Symbolic Architectures, VSA) is a general method to explicitly represent and process information in high-dimensional vectors. It has previously been used successfully in combination with deep neural networks and other signal processing algorithms. We argue that the internal high-dimensional representation of MiniROCKET is well suited to be complemented by the algebra of HDC. This leads to a more general formulation, HDC-MiniROCKET, where the original algorithm is only a special case. We will discuss and demonstrate that HDC-MiniROCKET can systematically overcome catastrophic failures of MiniROCKET on simple synthetic datasets. These results are confirmed by experiments on the 128 datasets from the UCR time series classification benchmark. The extension with HDC can achieve considerably better results on datasets with high temporal dependence without increasing the computational effort for inference.
What makes visual place recognition easy or hard?
Jun 23, 2021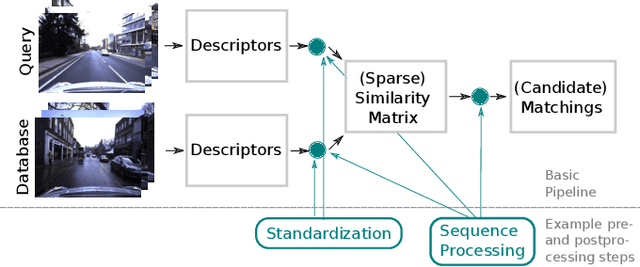

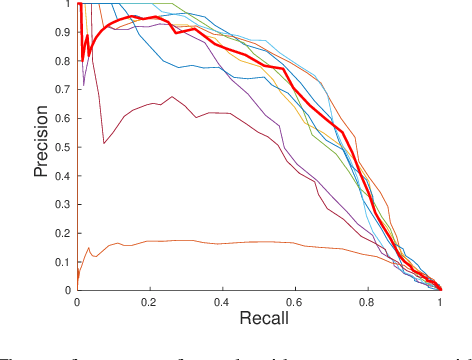
Visual place recognition is a fundamental capability for the localization of mobile robots. It places image retrieval in the practical context of physical agents operating in a physical world. It is an active field of research and many different approaches have been proposed and evaluated in many different experiments. In the following, we argue that due to variations of this practical context and individual design decisions, place recognition experiments are barely comparable across different papers and that there is a variety of properties that can change from one experiment to another. We provide an extensive list of such properties and give examples how they can be used to setup a place recognition experiment easier or harder. This might be interesting for different involved parties: (1) people who just want to select a place recognition approach that is suitable for the properties of their particular task at hand, (2) researchers that look for open research questions and are interested in particularly difficult instances, (3) authors that want to create reproducible papers on this topic, and (4) also reviewers that have the task to identify potential problems in papers under review.
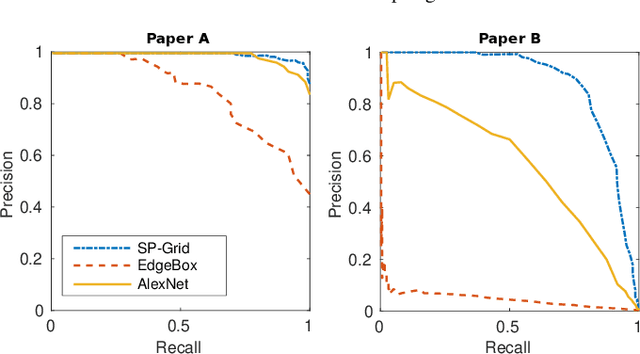
Beyond ANN: Exploiting Structural Knowledge for Efficient Place Recognition
Mar 15, 2021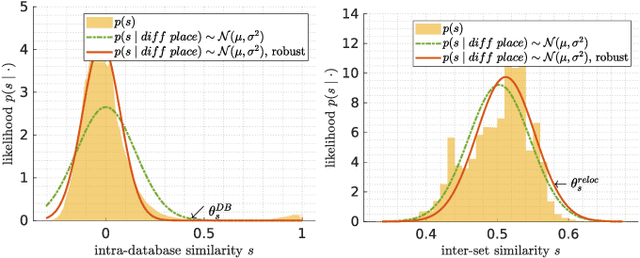
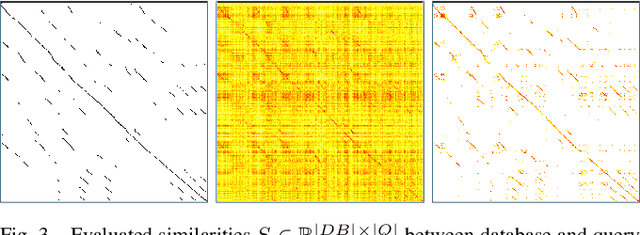
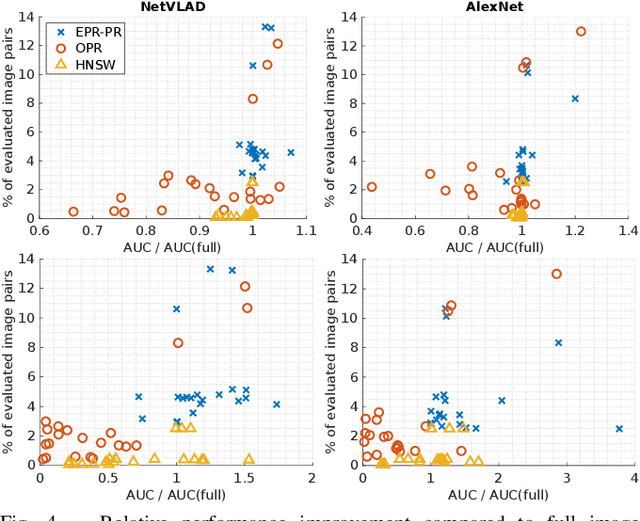
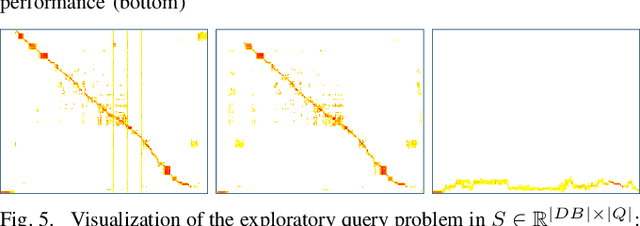
Visual place recognition is the task of recognizing same places of query images in a set of database images, despite potential condition changes due to time of day, weather or seasons. It is important for loop closure detection in SLAM and candidate selection for global localization. Many approaches in the literature perform computationally inefficient full image comparisons between queries and all database images. There is still a lack of suited methods for efficient place recognition that allow a fast, sparse comparison of only the most promising image pairs without any loss in performance. While this is partially given by ANN-based methods, they trade speed for precision and additional memory consumption, and many cannot find arbitrary numbers of matching database images in case of loops in the database. In this paper, we propose a novel fast sequence-based method for efficient place recognition that can be applied online. It uses relocalization to recover from sequence losses, and exploits usually available but often unused intra-database similarities for a potential detection of all matching database images for each query in case of loops or stops in the database. We performed extensive experimental evaluations over five datasets and 21 sequence combinations, and show that our method outperforms two state-of-the-art approaches and even full image comparisons in many cases, while providing a good tradeoff between performance and percentage of evaluated image pairs. Source code for Matlab will be provided with publication of this paper.
Hyperdimensional computing as a framework for systematic aggregation of image descriptors
Jan 19, 2021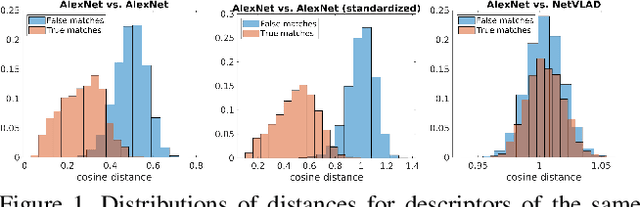
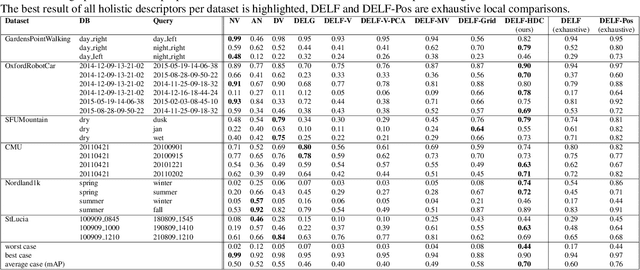
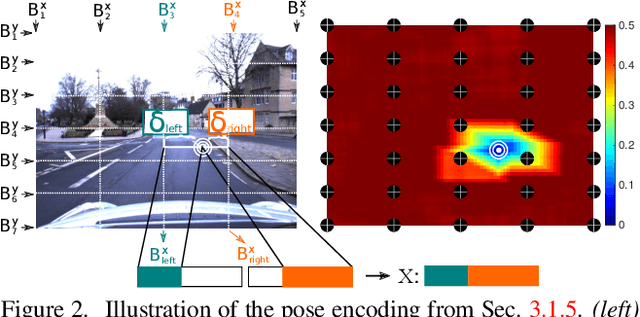
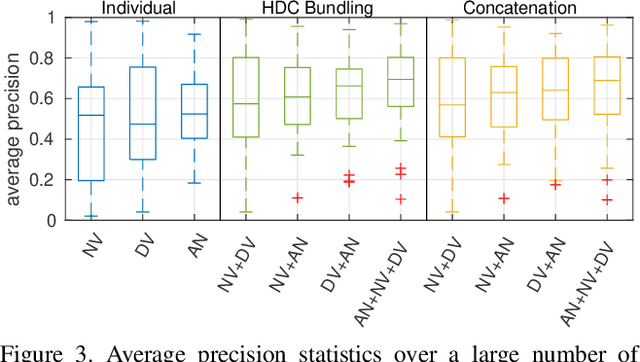
Image and video descriptors are an omnipresent tool in computer vision and its application fields like mobile robotics. Many hand-crafted and in particular learned image descriptors are numerical vectors with a potentially (very) large number of dimensions. Practical considerations like memory consumption or time for comparisons call for the creation of compact representations. In this paper, we use hyperdimensional computing (HDC) as an approach to systematically combine information from a set of vectors in a single vector of the same dimensionality. HDC is a known technique to perform symbolic processing with distributed representation in numerical vectors with thousands of dimensions. We present a HDC implementation that is suitable for processing the output of existing and future (deep-learning based) image descriptors. We discuss how this can be used as a framework to process descriptors together with additional knowledge by simple and fast vector operations. A concrete outcome is a novel HDC-based approach to aggregate a set of local image descriptors together with their image positions in a single holistic descriptor. The comparison to available holistic descriptors and aggregation methods on a series of standard mobile robotics place recognition experiments shows a 20% improvement in average performance compared to runner-up and 3.6x better worst-case performance.