 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHS3-Bench: A Benchmark and Strong Baseline for Hyperspectral Semantic Segmentation in Driving Scenarios
Sep 17, 2024



Semantic segmentation is an essential step for many vision applications in order to understand a scene and the objects within. Recent progress in hyperspectral imaging technology enables the application in driving scenarios and the hope is that the devices perceptive abilities provide an advantage over RGB-cameras. Even though some datasets exist, there is no standard benchmark available to systematically measure progress on this task and evaluate the benefit of hyperspectral data. In this paper, we work towards closing this gap by providing the HyperSpectral Semantic Segmentation benchmark (HS3-Bench). It combines annotated hyperspectral images from three driving scenario datasets and provides standardized metrics, implementations, and evaluation protocols. We use the benchmark to derive two strong baseline models that surpass the previous state-of-the-art performances with and without pre-training on the individual datasets. Further, our results indicate that the existing learning-based methods benefit more from leveraging additional RGB training data than from leveraging the additional hyperspectral channels. This poses important questions for future research on hyperspectral imaging for semantic segmentation in driving scenarios. Code to run the benchmark and the strong baseline approaches are available under https://github.com/nickstheisen/hyperseg.
Skeleton-DML: Deep Metric Learning for Skeleton-Based One-Shot Action Recognition
Dec 26, 2020

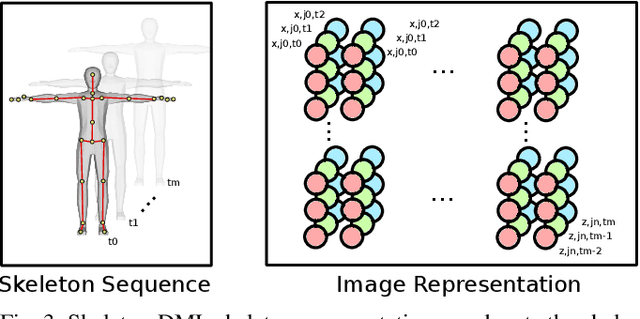
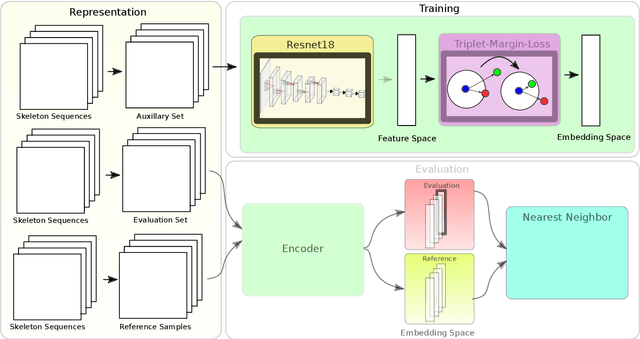
One-shot action recognition allows the recognition of human-performed actions with only a single training example. This can influence human-robot-interaction positively by enabling the robot to react to previously unseen behaviour. We formulate the one-shot action recognition problem as a deep metric learning problem and propose a novel image-based skeleton representation that performs well in a metric learning setting. Therefore, we train a model that projects the image representations into an embedding space. In embedding space the similar actions have a low euclidean distance while dissimilar actions have a higher distance. The one-shot action recognition problem becomes a nearest-neighbor search in a set of activity reference samples. We evaluate the performance of our proposed representation against a variety of other skeleton-based image representations. In addition, we present an ablation study that shows the influence of different embedding vector sizes, losses and augmentation. Our approach lifts the state-of-the-art by 3.3% for the one-shot action recognition protocol on the NTU RGB+D 120 dataset under a comparable training setup. With additional augmentation our result improved over 7.7%.
Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
Apr 28, 2020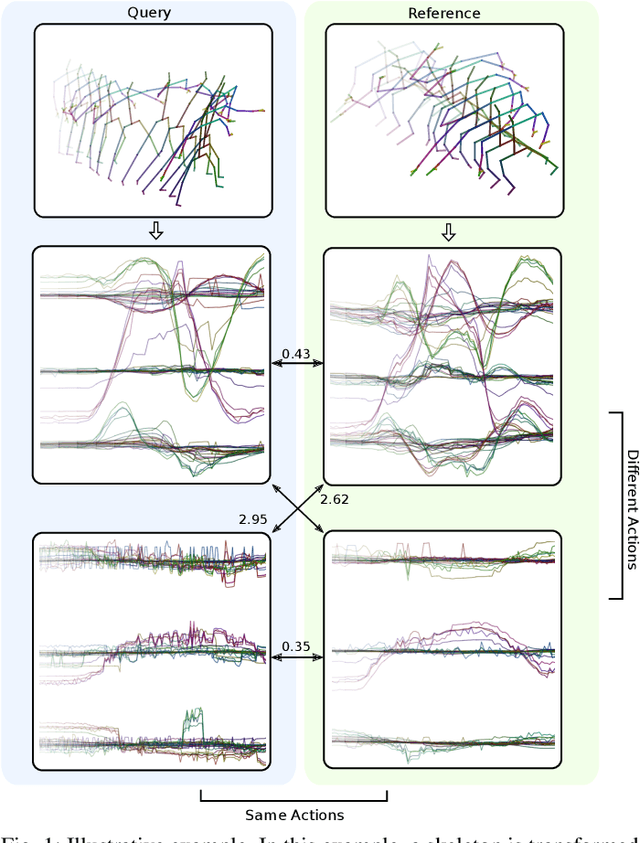

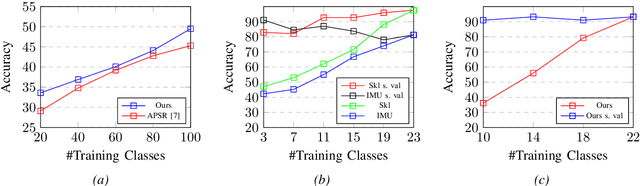
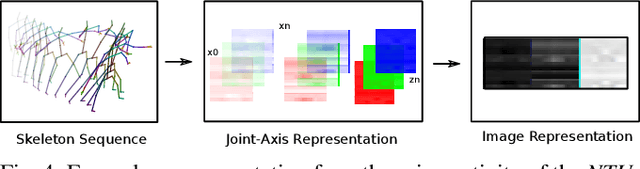
Recognizing an activity with a single reference sample using metric learning approaches is a promising research field. The majority of few-shot methods focus on object recognition or face-identification. We follow a metric learning approach to reduce the action recognition problem to a nearest neighbor search in embedding space. We encode signals on a signal level into images and then extract features using a deep residual CNN. Using triplet loss, we learn a feature embedding. The resulting encoder transforms features into an embedding space in which closer distances encode similar actions while higher distances encode different actions. Our approach based on a signal-level formulation remains flexible across a variety of modalities while outperforming the baseline on the large scale NTU RGB+D 120 dataset for the One-Shot action recognition protocol by 4.2%. Further, we show generalization on experiments using the UTD-MHAD dataset for inertial data and the Simitate dataset for motion capturing data. Furthermore, our inter-joint and inter-sensor experiments suggest good capabilities on previously unseen joint and sensor setups.
Gimme Signals: Discriminative signal encoding for multimodal activity recognition
Apr 09, 2020



We present a simple, yet effective and flexible method for action recognition supporting multiple sensor modalities. Multivariate signal sequences are encoded in an image and are then classified using a recently proposed EfficientNet CNN architecture. Our focus was to find an approach that generalizes well across different sensor modalities without specific adaptions while still achieving good results. We apply our method to 4 action recognition datasets containing skeleton sequences, inertial and motion capturing measurements as well as \wifi fingerprints that range up to 120 action classes. Our method defines the current best CNN-based approach on the NTU RGB+D 120 dataset, lifts the state of the art on the ARIL Wi-Fi dataset by +6.78%, improves the UTD-MHAD inertial baseline by +14.4%, the UTD-MHAD skeleton baseline by 1.13% and achieves 96.11% on the Simitate motion capturing data (80/20 split). We further demonstrate experiments on both, modality fusion on a signal level and signal reduction to prevent the representation from overloading.
Markerless Visual Robot Programming by Demonstration
Jul 30, 2018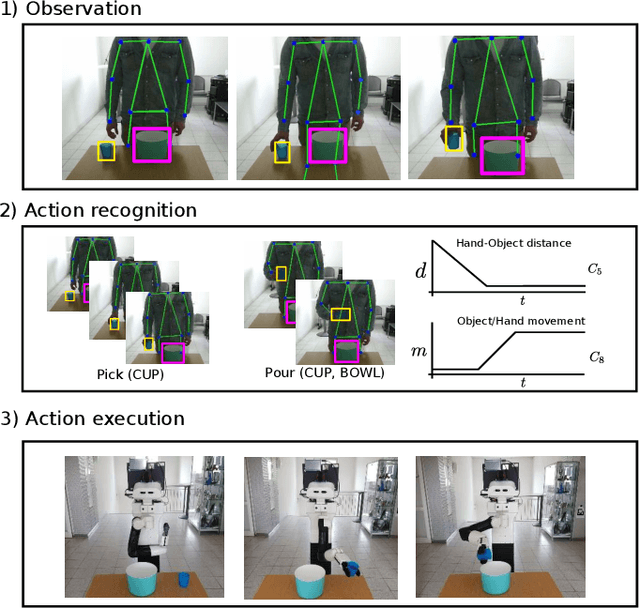
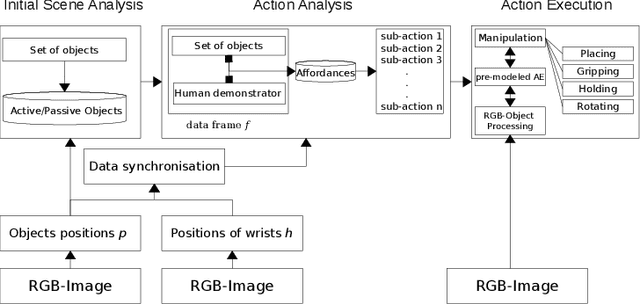
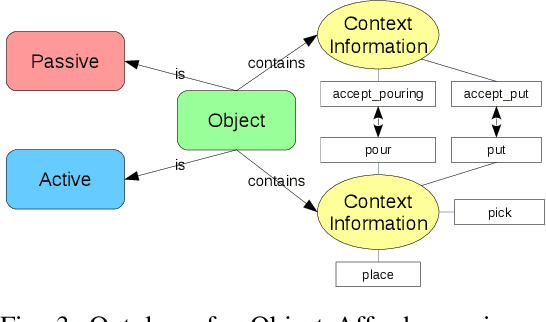

In this paper we present an approach for learning to imitate human behavior on a semantic level by markerless visual observation. We analyze a set of spatial constraints on human pose data extracted using convolutional pose machines and object informations extracted from 2D image sequences. A scene analysis, based on an ontology of objects and affordances, is combined with continuous human pose estimation and spatial object relations. Using a set of constraints we associate the observed human actions with a set of executable robot commands. We demonstrate our approach in a kitchen task, where the robot learns to prepare a meal.