 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimitate: A Hybrid Imitation Learning Benchmark
May 15, 2019

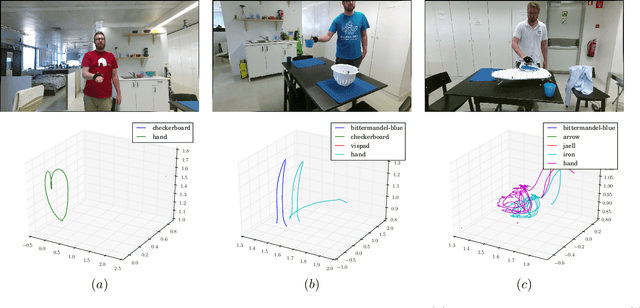
We present Simitate --- a hybrid benchmarking suite targeting the evaluation of approaches for imitation learning. A dataset containing 1938 sequences where humans perform daily activities in a realistic environment is presented. The dataset is strongly coupled with an integration into a simulator. RGB and depth streams with a resolution of 960$\mathbb{\times}$540 at 30Hz and accurate ground truth poses for the demonstrator's hand, as well as the object in 6 DOF at 120Hz are provided. Along with our dataset we provide the 3D model of the used environment, labeled object images and pre-trained models. A benchmarking suite that aims at fostering comparability and reproducibility supports the development of imitation learning approaches. Further, we propose and integrate evaluation metrics on assessing the quality of effect and trajectory of the imitation performed in simulation. Simitate is available on our project website: \url{https://agas.uni-koblenz.de/data/simitate/}.
Markerless Visual Robot Programming by Demonstration
Jul 30, 2018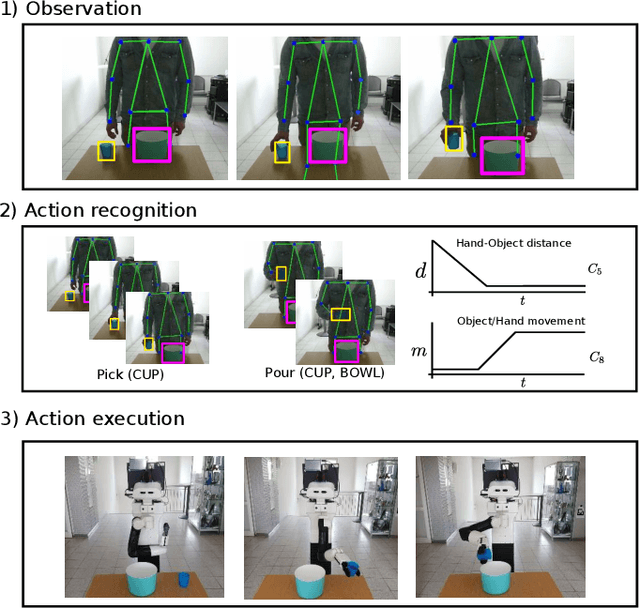
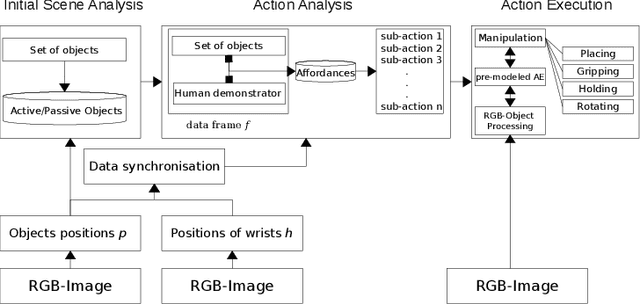
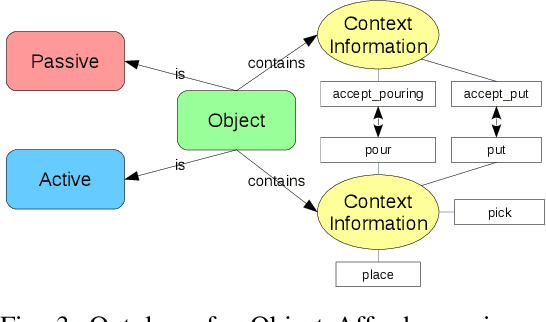

In this paper we present an approach for learning to imitate human behavior on a semantic level by markerless visual observation. We analyze a set of spatial constraints on human pose data extracted using convolutional pose machines and object informations extracted from 2D image sequences. A scene analysis, based on an ontology of objects and affordances, is combined with continuous human pose estimation and spatial object relations. Using a set of constraints we associate the observed human actions with a set of executable robot commands. We demonstrate our approach in a kitchen task, where the robot learns to prepare a meal.