 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Revisiting Visual Place Recognition for Joining Submaps in Multimap SLAM
Jul 17, 2024Visual SLAM is a key technology for many autonomous systems. However, tracking loss can lead to the creation of disjoint submaps in multimap SLAM systems like ORB-SLAM3. Because of that, these systems employ submap merging strategies. As we show, these strategies are not always successful. In this paper, we investigate the impact of using modern VPR approaches for submap merging in visual SLAM. We argue that classical evaluation metrics are not sufficient to estimate the impact of a modern VPR component on the overall system. We show that naively replacing the VPR component does not leverage its full potential without requiring substantial interference in the original system. Because of that, we present a post-processing pipeline along with a set of metrics that allow us to estimate the impact of modern VPR components. We evaluate our approach on the NCLT and Newer College datasets using ORB-SLAM3 with NetVLAD and HDC-DELF as VPR components. Additionally, we present a simple approach for combining VPR with temporal consistency for map merging. We show that the map merging performance of ORB-SLAM3 can be improved. Building on these results, researchers in VPR can assess the potential of their approaches for SLAM systems.
Local positional graphs and attentive local features for a data and runtime-efficient hierarchical place recognition pipeline
Mar 15, 2024Large-scale applications of Visual Place Recognition (VPR) require computationally efficient approaches. Further, a well-balanced combination of data-based and training-free approaches can decrease the required amount of training data and effort and can reduce the influence of distribution shifts between the training and application phases. This paper proposes a runtime and data-efficient hierarchical VPR pipeline that extends existing approaches and presents novel ideas. There are three main contributions: First, we propose Local Positional Graphs (LPG), a training-free and runtime-efficient approach to encode spatial context information of local image features. LPG can be combined with existing local feature detectors and descriptors and considerably improves the image-matching quality compared to existing techniques in our experiments. Second, we present Attentive Local SPED (ATLAS), an extension of our previous local features approach with an attention module that improves the feature quality while maintaining high data efficiency. The influence of the proposed modifications is evaluated in an extensive ablation study. Third, we present a hierarchical pipeline that exploits hyperdimensional computing to use the same local features as holistic HDC-descriptors for fast candidate selection and for candidate reranking. We combine all contributions in a runtime and data-efficient VPR pipeline that shows benefits over the state-of-the-art method Patch-NetVLAD on a large collection of standard place recognition datasets with 15$\%$ better performance in VPR accuracy, 54$\times$ faster feature comparison speed, and 55$\times$ less descriptor storage occupancy, making our method promising for real-world high-performance large-scale VPR in changing environments. Code will be made available with publication of this paper.
Visual Place Recognition: A Tutorial
Mar 06, 2023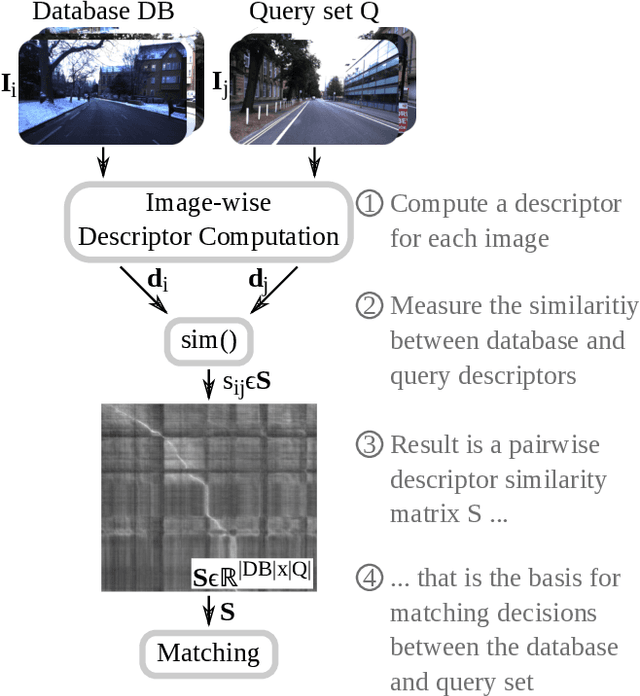
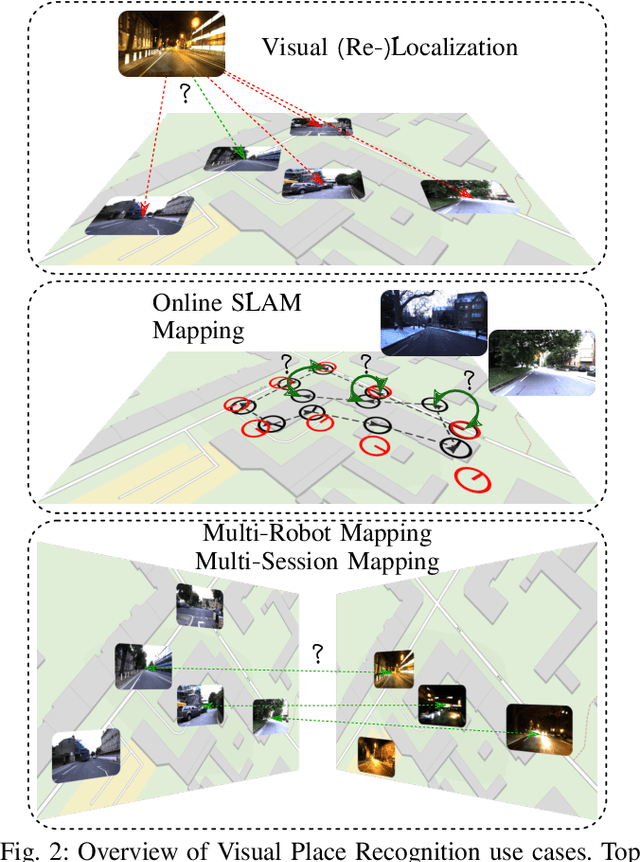

Localization is an essential capability for mobile robots. A rapidly growing field of research in this area is Visual Place Recognition (VPR), which is the ability to recognize previously seen places in the world based solely on images. This present work is the first tutorial paper on visual place recognition. It unifies the terminology of VPR and complements prior research in two important directions: 1) It provides a systematic introduction for newcomers to the field, covering topics such as the formulation of the VPR problem, a general-purpose algorithmic pipeline, an evaluation methodology for VPR approaches, and the major challenges for VPR and how they may be addressed. 2) As a contribution for researchers acquainted with the VPR problem, it examines the intricacies of different VPR problem types regarding input, data processing, and output. The tutorial also discusses the subtleties behind the evaluation of VPR algorithms, e.g., the evaluation of a VPR system that has to find all matching database images per query, as opposed to just a single match. Practical code examples in Python illustrate to prospective practitioners and researchers how VPR is implemented and evaluated.
What makes visual place recognition easy or hard?
Jun 23, 2021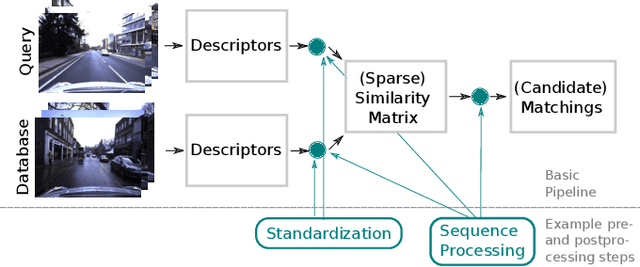

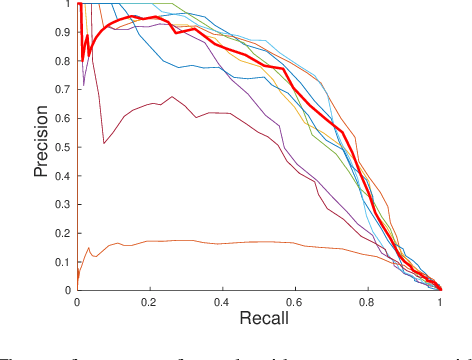
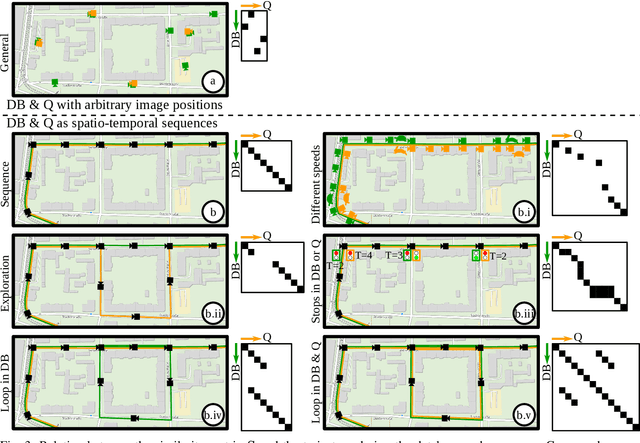
Visual place recognition is a fundamental capability for the localization of mobile robots. It places image retrieval in the practical context of physical agents operating in a physical world. It is an active field of research and many different approaches have been proposed and evaluated in many different experiments. In the following, we argue that due to variations of this practical context and individual design decisions, place recognition experiments are barely comparable across different papers and that there is a variety of properties that can change from one experiment to another. We provide an extensive list of such properties and give examples how they can be used to setup a place recognition experiment easier or harder. This might be interesting for different involved parties: (1) people who just want to select a place recognition approach that is suitable for the properties of their particular task at hand, (2) researchers that look for open research questions and are interested in particularly difficult instances, (3) authors that want to create reproducible papers on this topic, and (4) also reviewers that have the task to identify potential problems in papers under review.
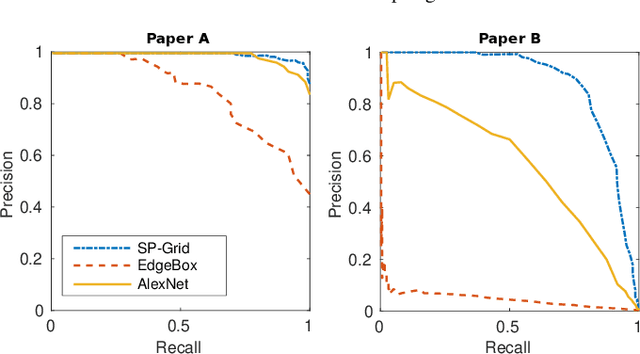
Beyond ANN: Exploiting Structural Knowledge for Efficient Place Recognition
Mar 15, 2021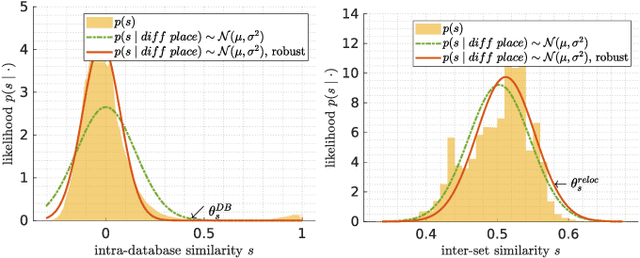
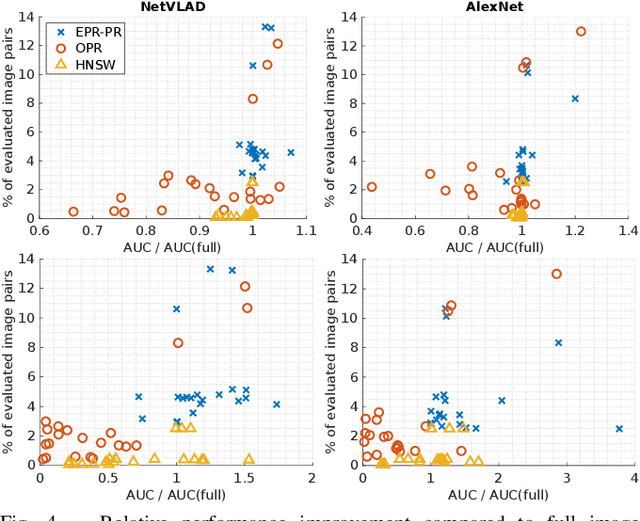
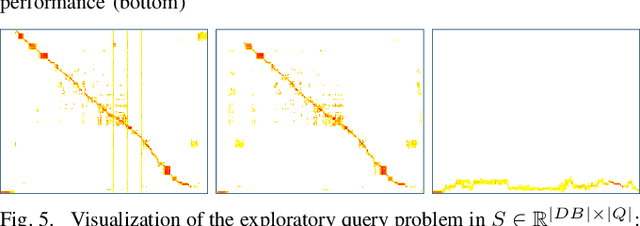
Visual place recognition is the task of recognizing same places of query images in a set of database images, despite potential condition changes due to time of day, weather or seasons. It is important for loop closure detection in SLAM and candidate selection for global localization. Many approaches in the literature perform computationally inefficient full image comparisons between queries and all database images. There is still a lack of suited methods for efficient place recognition that allow a fast, sparse comparison of only the most promising image pairs without any loss in performance. While this is partially given by ANN-based methods, they trade speed for precision and additional memory consumption, and many cannot find arbitrary numbers of matching database images in case of loops in the database. In this paper, we propose a novel fast sequence-based method for efficient place recognition that can be applied online. It uses relocalization to recover from sequence losses, and exploits usually available but often unused intra-database similarities for a potential detection of all matching database images for each query in case of loops or stops in the database. We performed extensive experimental evaluations over five datasets and 21 sequence combinations, and show that our method outperforms two state-of-the-art approaches and even full image comparisons in many cases, while providing a good tradeoff between performance and percentage of evaluated image pairs. Source code for Matlab will be provided with publication of this paper.
Hyperdimensional computing as a framework for systematic aggregation of image descriptors
Jan 19, 2021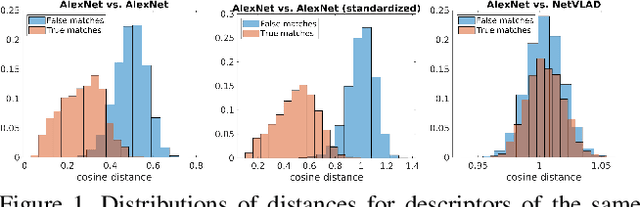
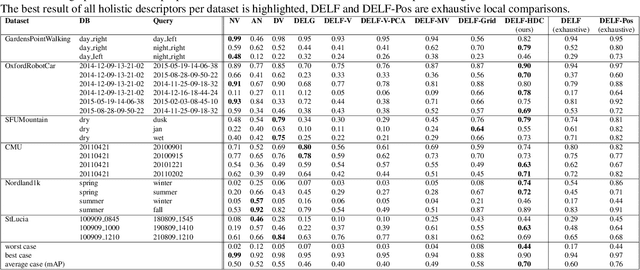
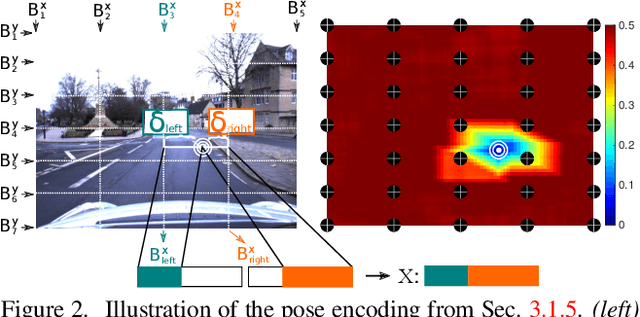
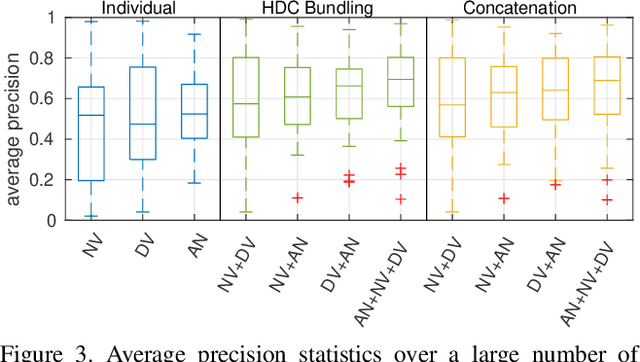
Image and video descriptors are an omnipresent tool in computer vision and its application fields like mobile robotics. Many hand-crafted and in particular learned image descriptors are numerical vectors with a potentially (very) large number of dimensions. Practical considerations like memory consumption or time for comparisons call for the creation of compact representations. In this paper, we use hyperdimensional computing (HDC) as an approach to systematically combine information from a set of vectors in a single vector of the same dimensionality. HDC is a known technique to perform symbolic processing with distributed representation in numerical vectors with thousands of dimensions. We present a HDC implementation that is suitable for processing the output of existing and future (deep-learning based) image descriptors. We discuss how this can be used as a framework to process descriptors together with additional knowledge by simple and fast vector operations. A concrete outcome is a novel HDC-based approach to aggregate a set of local image descriptors together with their image positions in a single holistic descriptor. The comparison to available holistic descriptors and aggregation methods on a series of standard mobile robotics place recognition experiments shows a 20% improvement in average performance compared to runner-up and 3.6x better worst-case performance.
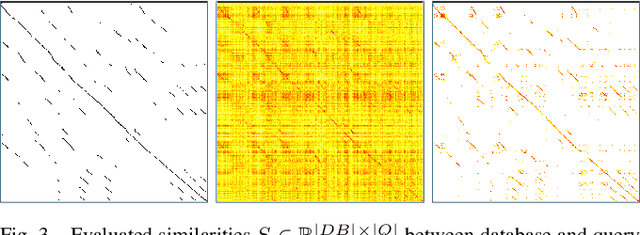
Graph-based non-linear least squares optimization for visual place recognition in changing environments
Dec 29, 2020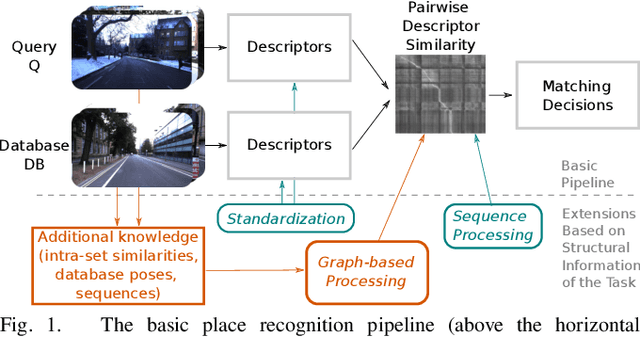

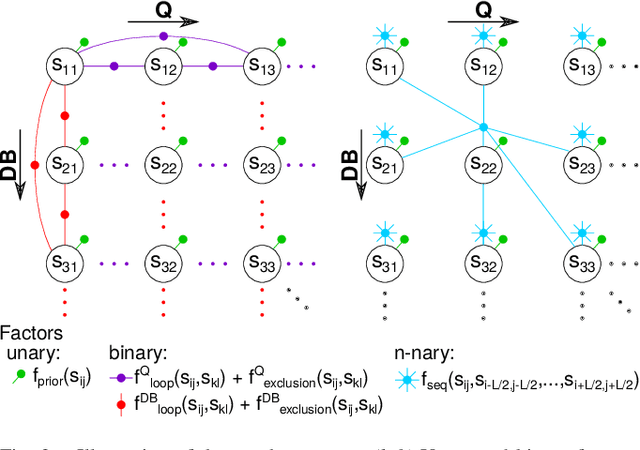

Visual place recognition is an important subproblem of mobile robot localization. Since it is a special case of image retrieval, the basic source of information is the pairwise similarity of image descriptors. However, the embedding of the image retrieval problem in this robotic task provides additional structure that can be exploited, e.g. spatio-temporal consistency. Several algorithms exist to exploit this structure, e.g., sequence processing approaches or descriptor standardization approaches for changing environments. In this paper, we propose a graph-based framework to systematically exploit different types of additional structure and information. The graphical model is used to formulate a non-linear least squares problem that can be optimized with standard tools. Beyond sequences and standardization, we propose the usage of intra-set similarities within the database and/or the query image set as additional source of information. If available, our approach also allows to seamlessly integrate additional knowledge about poses of database images. We evaluate the system on a variety of standard place recognition datasets and demonstrate performance improvements for a large number of different configurations including different sources of information, different types of constraints, and online or offline place recognition setups.
Unsupervised Learning Methods for Visual Place Recognition in Discretely and Continuously Changing Environments
Jan 24, 2020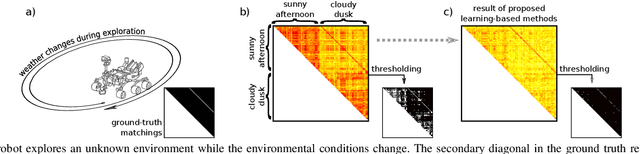
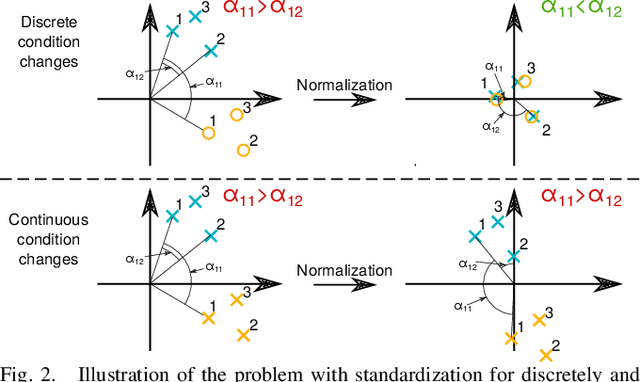
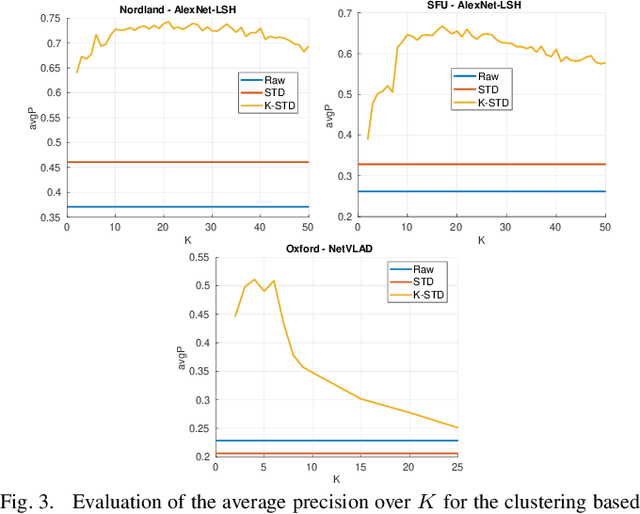
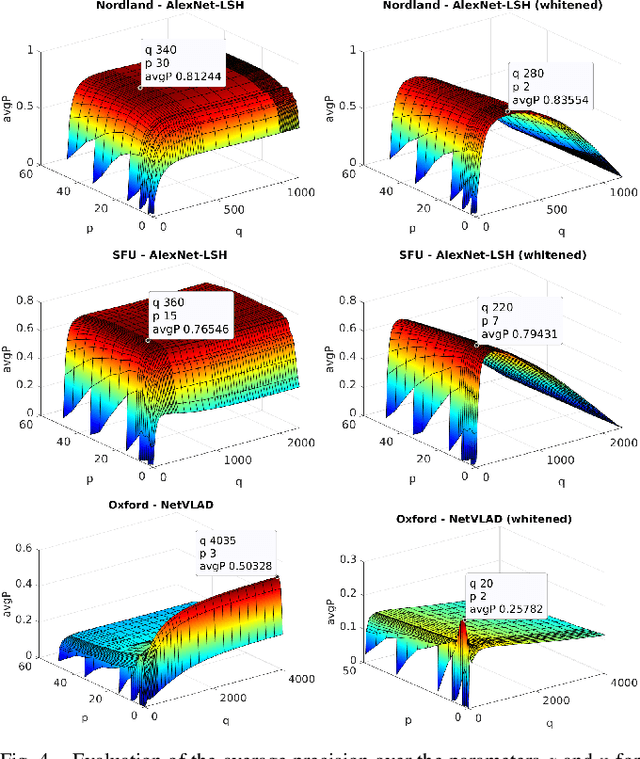
Visual place recognition in changing environments is the problem of finding matchings between two sets of observations, a query set and a reference set, despite severe appearance changes. Recently, image comparison using CNN-based descriptors showed very promising results. However, existing experiments from the literature typically assume a single distinctive condition within each set (e.g., reference: day, query: night). We demonstrate that as soon as the conditions change within one set (e.g., reference: day, query: traversal daytime-dusk-night-dawn), different places under the same condition can suddenly look more similar than same places under different conditions and state-of-the-art approaches like CNN-based descriptors fail. This paper discusses this practically very important problem of in-sequence condition changes and defines a hierarchy of problem setups from (1) no in-sequence changes, (2) discrete in-sequence changes, to (3) continuous in-sequence changes. We will experimentally evaluate the effect of these changes on two state-of-the-art CNN-descriptors. Our experiments emphasize the importance of statistical standardization of descriptors and shows its limitations in case of continuous changes. To address this practically most relevant setup, we investigate and experimentally evaluate the application of unsupervised learning methods using two available PCA-based approaches and propose a novel clustering-based extension of the statistical normalization.