 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Problem Sampling in Latent Space Using Sequential Monte Carlo
Feb 09, 2025



In image processing, solving inverse problems is the task of finding plausible reconstructions of an image that was corrupted by some (usually known) degradation model. Commonly, this process is done using a generative image model that can guide the reconstruction towards solutions that appear natural. The success of diffusion models over the last few years has made them a leading candidate for this task. However, the sequential nature of diffusion models makes this conditional sampling process challenging. Furthermore, since diffusion models are often defined in the latent space of an autoencoder, the encoder-decoder transformations introduce additional difficulties. Here, we suggest a novel sampling method based on sequential Monte Carlo (SMC) in the latent space of diffusion models. We use the forward process of the diffusion model to add additional auxiliary observations and then perform an SMC sampling as part of the backward process. Empirical evaluations on ImageNet and FFHQ show the benefits of our approach over competing methods on various inverse problem tasks.
Efficient Image Restoration via Latent Consistency Flow Matching
Feb 05, 2025



Recent advances in generative image restoration (IR) have demonstrated impressive results. However, these methods are hindered by their substantial size and computational demands, rendering them unsuitable for deployment on edge devices. This work introduces ELIR, an Efficient Latent Image Restoration method. ELIR operates in latent space by first predicting the latent representation of the minimum mean square error (MMSE) estimator and then transporting this estimate to high-quality images using a latent consistency flow-based model. Consequently, ELIR is more than 4x faster compared to the state-of-the-art diffusion and flow-based approaches. Moreover, ELIR is also more than 4x smaller, making it well-suited for deployment on resource-constrained edge devices. Comprehensive evaluations of various image restoration tasks show that ELIR achieves competitive results, effectively balancing distortion and perceptual quality metrics while offering improved efficiency in terms of memory and computation.
Data Generation for Hardware-Friendly Post-Training Quantization
Oct 29, 2024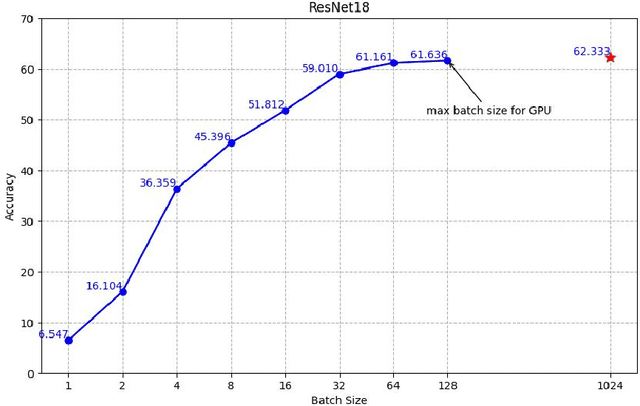



Zero-shot quantization (ZSQ) using synthetic data is a key approach for post-training quantization (PTQ) under privacy and security constraints. However, existing data generation methods often struggle to effectively generate data suitable for hardware-friendly quantization, where all model layers are quantized. We analyze existing data generation methods based on batch normalization (BN) matching and identify several gaps between synthetic and real data: 1) Current generation algorithms do not optimize the entire synthetic dataset simultaneously; 2) Data augmentations applied during training are often overlooked; and 3) A distribution shift occurs in the final model layers due to the absence of BN in those layers. These gaps negatively impact ZSQ performance, particularly in hardware-friendly quantization scenarios. In this work, we propose Data Generation for Hardware-friendly quantization (DGH), a novel method that addresses these gaps. DGH jointly optimizes all generated images, regardless of the image set size or GPU memory constraints. To address data augmentation mismatches, DGH includes a preprocessing stage that mimics the augmentation process and enhances image quality by incorporating natural image priors. Finally, we propose a new distribution-stretching loss that aligns the support of the feature map distribution between real and synthetic data. This loss is applied to the model's output and can be adapted to various tasks. DGH demonstrates significant improvements in quantization performance across multiple tasks, achieving up to a 30% increase in accuracy for hardware-friendly ZSQ in both classification and object detection, often performing on par with real data.
Bayesian Uncertainty for Gradient Aggregation in Multi-Task Learning
Feb 06, 2024



As machine learning becomes more prominent there is a growing demand to perform several inference tasks in parallel. Running a dedicated model for each task is computationally expensive and therefore there is a great interest in multi-task learning (MTL). MTL aims at learning a single model that solves several tasks efficiently. Optimizing MTL models is often achieved by computing a single gradient per task and aggregating them for obtaining a combined update direction. However, these approaches do not consider an important aspect, the sensitivity in the gradient dimensions. Here, we introduce a novel gradient aggregation approach using Bayesian inference. We place a probability distribution over the task-specific parameters, which in turn induce a distribution over the gradients of the tasks. This additional valuable information allows us to quantify the uncertainty in each of the gradients dimensions, which can then be factored in when aggregating them. We empirically demonstrate the benefits of our approach in a variety of datasets, achieving state-of-the-art performance.
De-Confusing Pseudo-Labels in Source-Free Domain Adaptation
Jan 03, 2024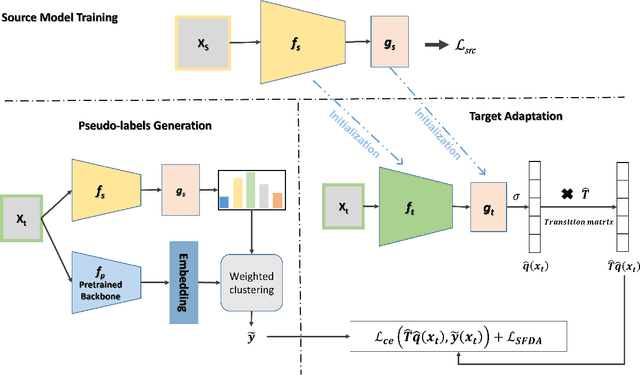
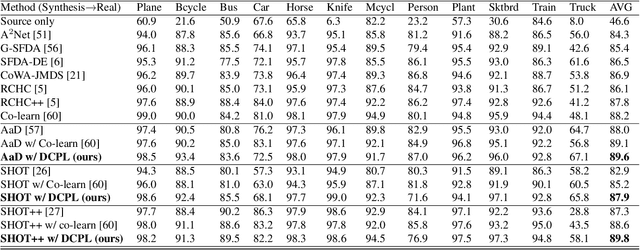
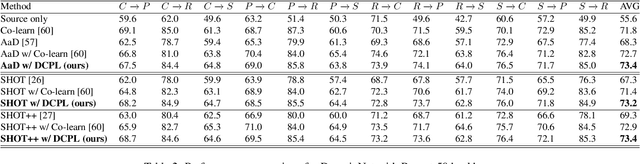
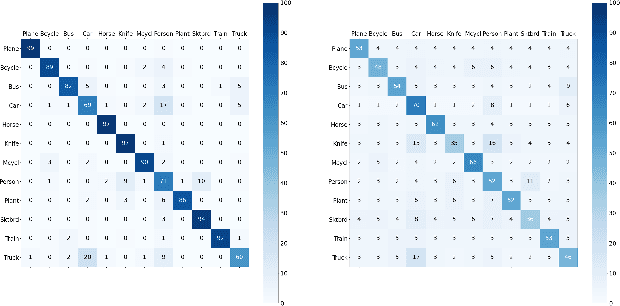
Source-free domain adaptation (SFDA) aims to transfer knowledge learned from a source domain to an unlabeled target domain, where the source data is unavailable during adaptation. Existing approaches for SFDA focus on self-training usually including well-established entropy minimization and pseudo-labeling techniques. Recent work suggested a co-learning strategy to improve the quality of the generated target pseudo-labels using robust pretrained networks such as Swin-B. However, since the generated pseudo-labels depend on the source model, they may be noisy due to domain shift. In this paper, we view SFDA from the perspective of label noise learning and learn to de-confuse the pseudo-labels. More specifically, we learn a noise transition matrix of the pseudo-labels to capture the label corruption of each class and learn the underlying true label distribution. Estimating the noise transition matrix enables a better true class-posterior estimation results with better prediction accuracy. We demonstrate the effectiveness of our approach applied with several SFDA methods: SHOT, SHOT++, and AaD. We obtain state-of-the-art results on three domain adaptation datasets: VisDA, DomainNet, and OfficeHome.
EPTQ: Enhanced Post-Training Quantization via Label-Free Hessian
Sep 20, 2023Quantization of deep neural networks (DNN) has become a key element in the efforts of embedding such networks on end-user devices. However, current quantization methods usually suffer from costly accuracy degradation. In this paper, we propose a new method for Enhanced Post Training Quantization named EPTQ. The method is based on knowledge distillation with an adaptive weighting of layers. In addition, we introduce a new label-free technique for approximating the Hessian trace of the task loss, named Label-Free Hessian. This technique removes the requirement of a labeled dataset for computing the Hessian. The adaptive knowledge distillation uses the Label-Free Hessian technique to give greater attention to the sensitive parts of the model while performing the optimization. Empirically, by employing EPTQ we achieve state-of-the-art results on a wide variety of models, tasks, and datasets, including ImageNet classification, COCO object detection, and Pascal-VOC for semantic segmentation. We demonstrate the performance and compatibility of EPTQ on an extended set of architectures, including CNNs, Transformers, hybrid, and MLP-only models.
Reconciling a Centroid-Hypothesis Conflict in Source-Free Domain Adaptation
Dec 07, 2022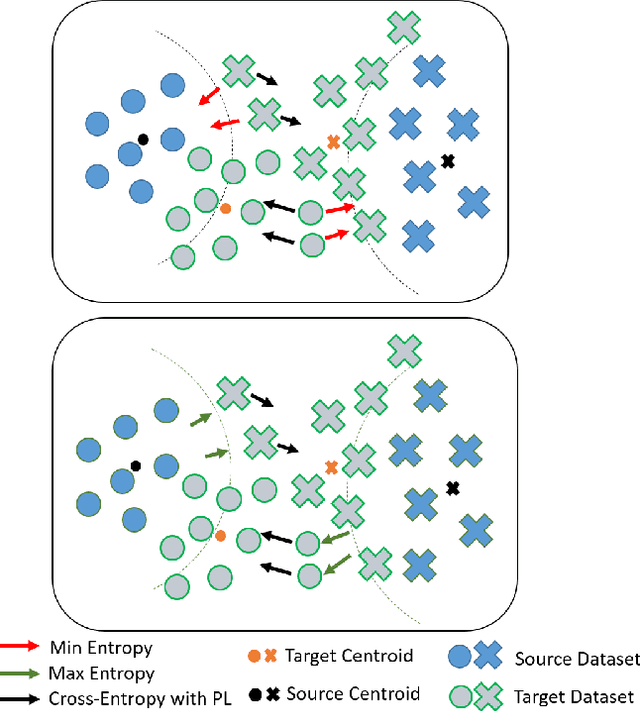
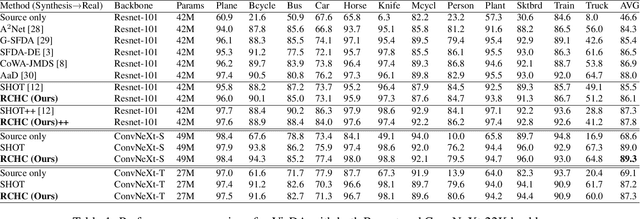
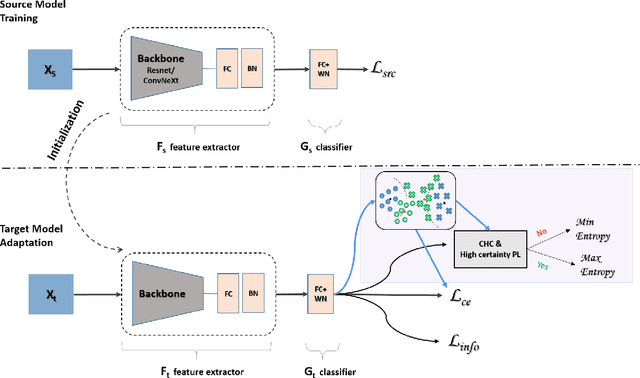
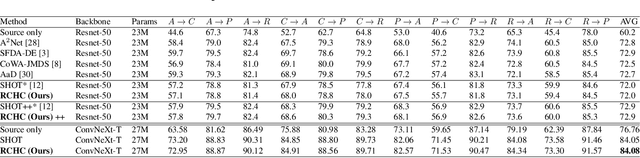
Source-free domain adaptation (SFDA) aims to transfer knowledge learned from a source domain to an unlabeled target domain, where the source data is unavailable during adaptation. Existing approaches for SFDA focus on self-training usually including well-established entropy minimization techniques. One of the main challenges in SFDA is to reduce accumulation of errors caused by domain misalignment. A recent strategy successfully managed to reduce error accumulation by pseudo-labeling the target samples based on class-wise prototypes (centroids) generated by their clustering in the representation space. However, this strategy also creates cases for which the cross-entropy of a pseudo-label and the minimum entropy have a conflict in their objectives. We call this conflict the centroid-hypothesis conflict. We propose to reconcile this conflict by aligning the entropy minimization objective with that of the pseudo labels' cross entropy. We demonstrate the effectiveness of aligning the two loss objectives on three domain adaptation datasets. In addition, we provide state-of-the-art results using up-to-date architectures also showing the consistency of our method across these architectures.
HPTQ: Hardware-Friendly Post Training Quantization
Sep 26, 2021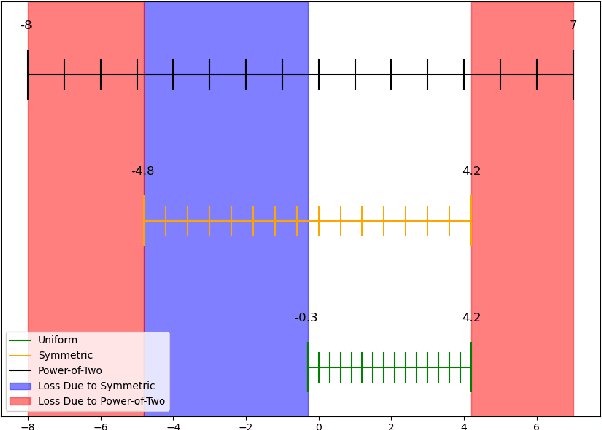

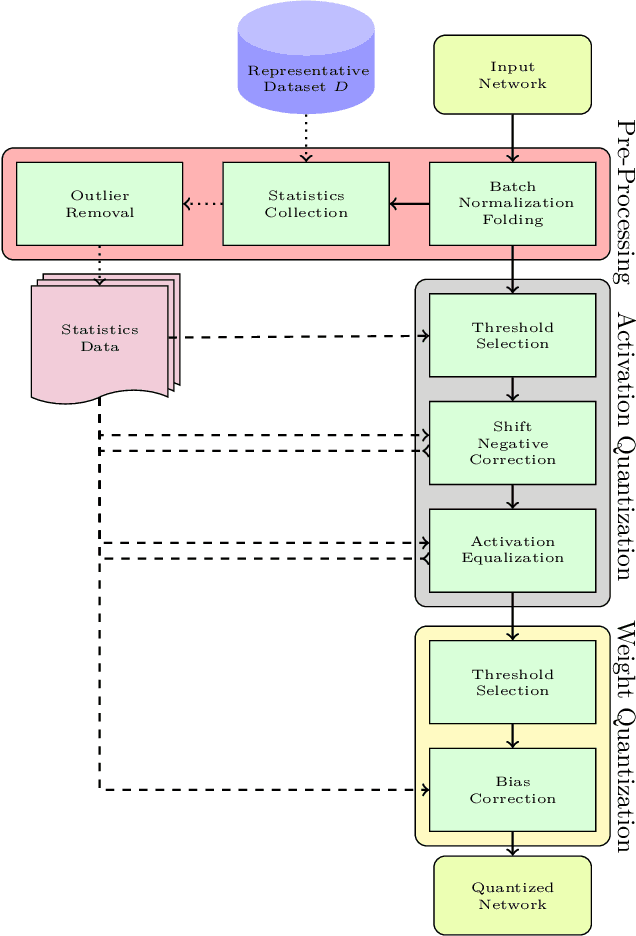
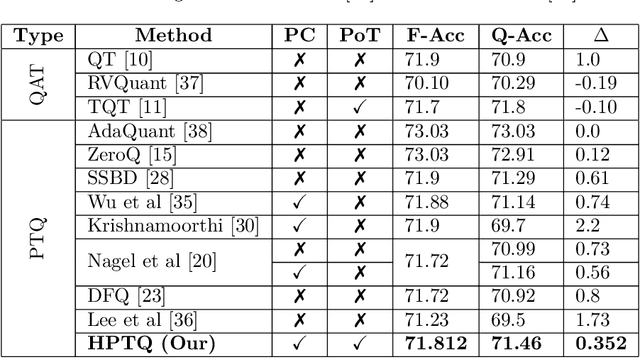
Neural network quantization enables the deployment of models on edge devices. An essential requirement for their hardware efficiency is that the quantizers are hardware-friendly: uniform, symmetric, and with power-of-two thresholds. To the best of our knowledge, current post-training quantization methods do not support all of these constraints simultaneously. In this work, we introduce a hardware-friendly post training quantization (HPTQ) framework, which addresses this problem by synergistically combining several known quantization methods. We perform a large-scale study on four tasks: classification, object detection, semantic segmentation and pose estimation over a wide variety of network architectures. Our extensive experiments show that competitive results can be obtained under hardware-friendly constraints.
Multi-View Image-to-Image Translation Supervised by 3D Pose
Apr 12, 2021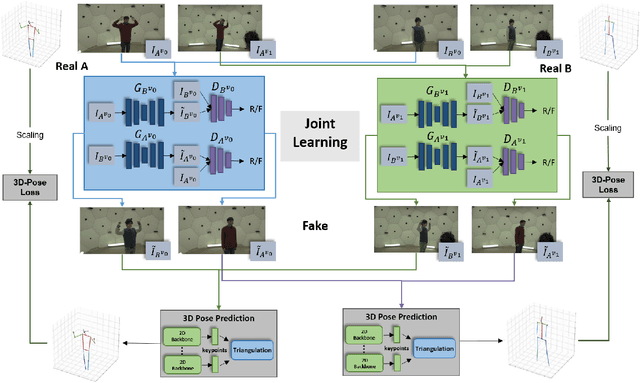



We address the task of multi-view image-to-image translation for person image generation. The goal is to synthesize photo-realistic multi-view images with pose-consistency across all views. Our proposed end-to-end framework is based on a joint learning of multiple unpaired image-to-image translation models, one per camera viewpoint. The joint learning is imposed by constraints on the shared 3D human pose in order to encourage the 2D pose projections in all views to be consistent. Experimental results on the CMU-Panoptic dataset demonstrate the effectiveness of the suggested framework in generating photo-realistic images of persons with new poses that are more consistent across all views in comparison to a standard Image-to-Image baseline. The code is available at: https://github.com/sony-si/MultiView-Img2Img
HMQ: Hardware Friendly Mixed Precision Quantization Block for CNNs
Jul 20, 2020
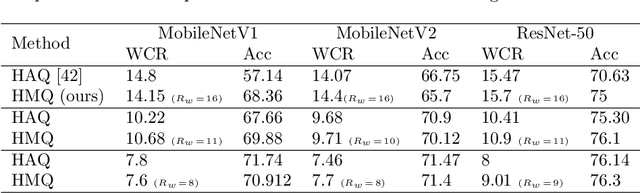
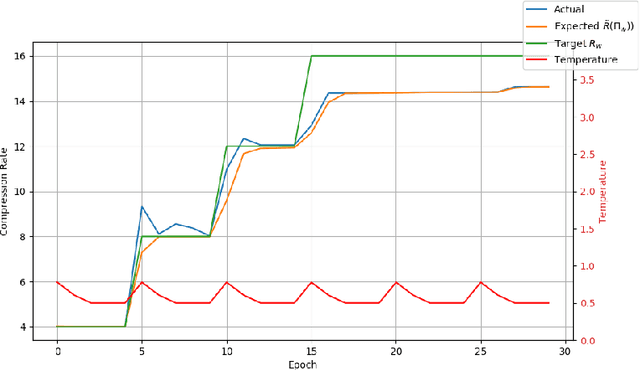

Recent work in network quantization produced state-of-the-art results using mixed precision quantization. An imperative requirement for many efficient edge device hardware implementations is that their quantizers are uniform and with power-of-two thresholds. In this work, we introduce the Hardware Friendly Mixed Precision Quantization Block (HMQ) in order to meet this requirement. The HMQ is a mixed precision quantization block that repurposes the Gumbel-Softmax estimator into a smooth estimator of a pair of quantization parameters, namely, bit-width and threshold. HMQs use this to search over a finite space of quantization schemes. Empirically, we apply HMQs to quantize classification models trained on CIFAR10 and ImageNet. For ImageNet, we quantize four different architectures and show that, in spite of the added restrictions to our quantization scheme, we achieve competitive and, in some cases, state-of-the-art results.