 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconciling a Centroid-Hypothesis Conflict in Source-Free Domain Adaptation
Dec 07, 2022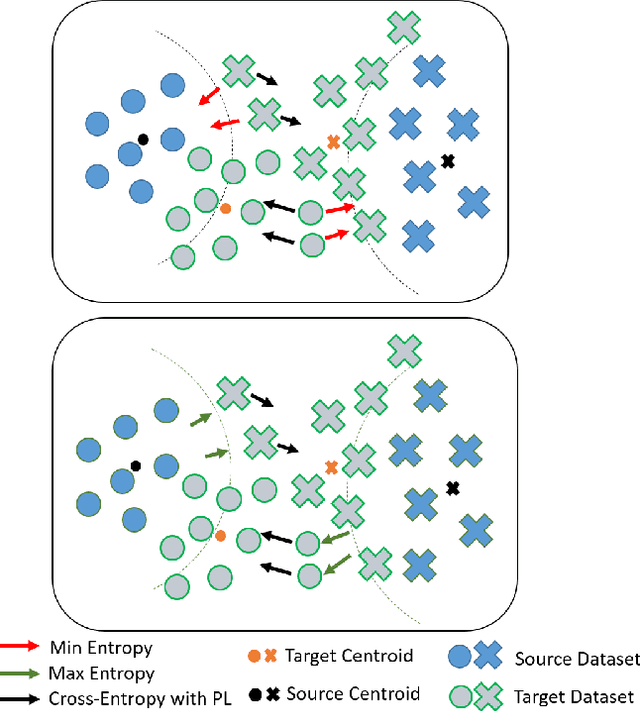
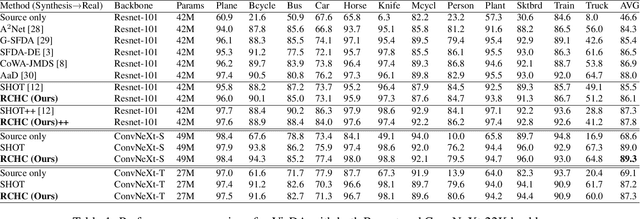
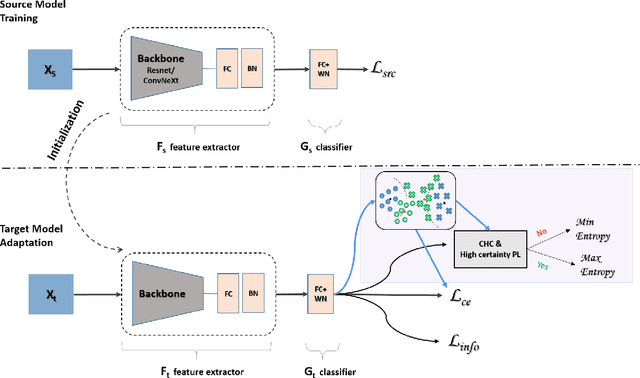
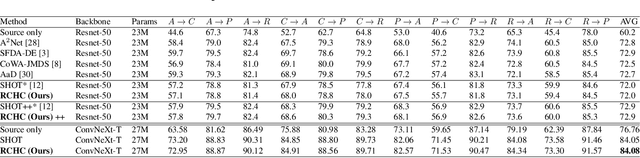
Source-free domain adaptation (SFDA) aims to transfer knowledge learned from a source domain to an unlabeled target domain, where the source data is unavailable during adaptation. Existing approaches for SFDA focus on self-training usually including well-established entropy minimization techniques. One of the main challenges in SFDA is to reduce accumulation of errors caused by domain misalignment. A recent strategy successfully managed to reduce error accumulation by pseudo-labeling the target samples based on class-wise prototypes (centroids) generated by their clustering in the representation space. However, this strategy also creates cases for which the cross-entropy of a pseudo-label and the minimum entropy have a conflict in their objectives. We call this conflict the centroid-hypothesis conflict. We propose to reconcile this conflict by aligning the entropy minimization objective with that of the pseudo labels' cross entropy. We demonstrate the effectiveness of aligning the two loss objectives on three domain adaptation datasets. In addition, we provide state-of-the-art results using up-to-date architectures also showing the consistency of our method across these architectures.
HPTQ: Hardware-Friendly Post Training Quantization
Sep 26, 2021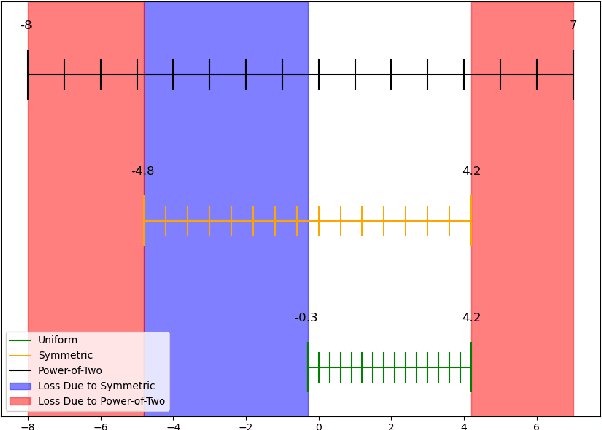

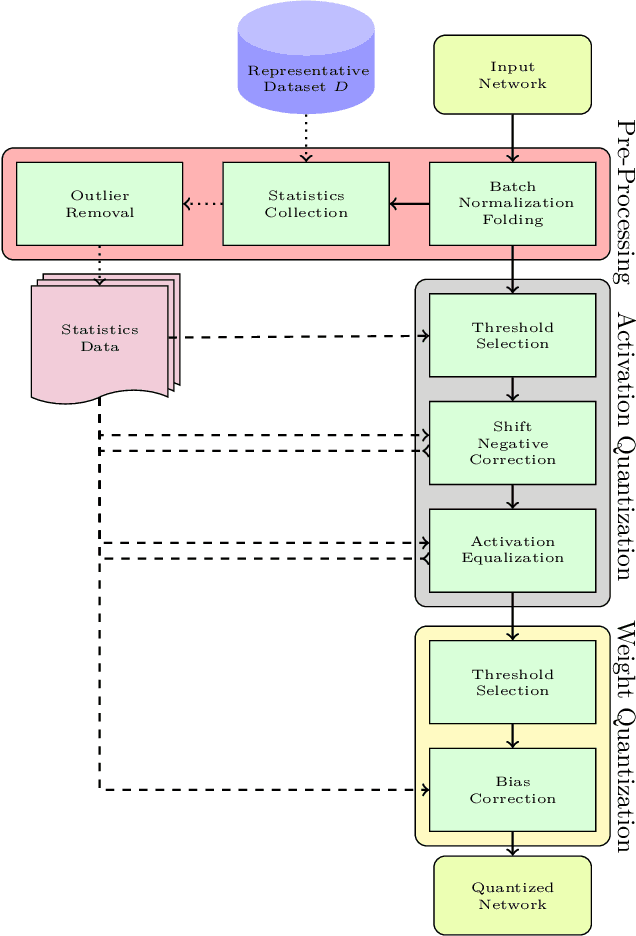
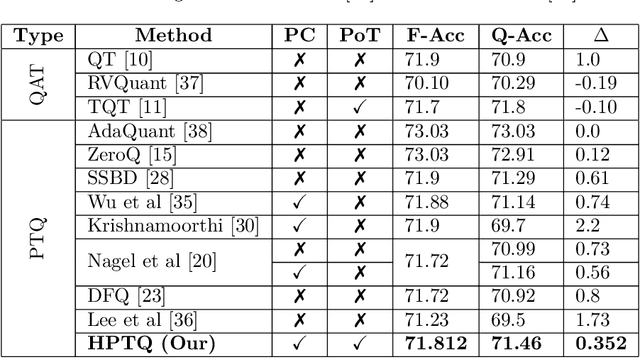
Neural network quantization enables the deployment of models on edge devices. An essential requirement for their hardware efficiency is that the quantizers are hardware-friendly: uniform, symmetric, and with power-of-two thresholds. To the best of our knowledge, current post-training quantization methods do not support all of these constraints simultaneously. In this work, we introduce a hardware-friendly post training quantization (HPTQ) framework, which addresses this problem by synergistically combining several known quantization methods. We perform a large-scale study on four tasks: classification, object detection, semantic segmentation and pose estimation over a wide variety of network architectures. Our extensive experiments show that competitive results can be obtained under hardware-friendly constraints.
Multi-View Image-to-Image Translation Supervised by 3D Pose
Apr 12, 2021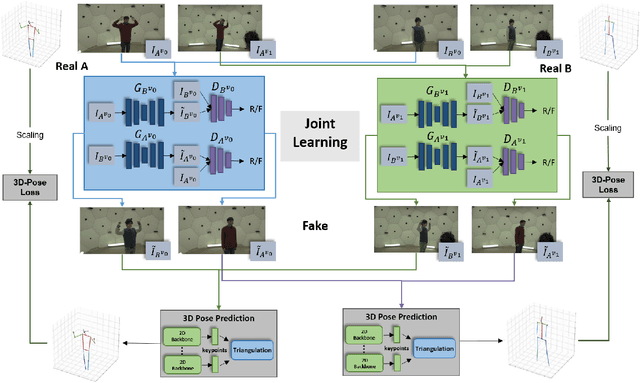



We address the task of multi-view image-to-image translation for person image generation. The goal is to synthesize photo-realistic multi-view images with pose-consistency across all views. Our proposed end-to-end framework is based on a joint learning of multiple unpaired image-to-image translation models, one per camera viewpoint. The joint learning is imposed by constraints on the shared 3D human pose in order to encourage the 2D pose projections in all views to be consistent. Experimental results on the CMU-Panoptic dataset demonstrate the effectiveness of the suggested framework in generating photo-realistic images of persons with new poses that are more consistent across all views in comparison to a standard Image-to-Image baseline. The code is available at: https://github.com/sony-si/MultiView-Img2Img