 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Classification via Concepts and Attributes
Paper and Code
Mar 07, 2018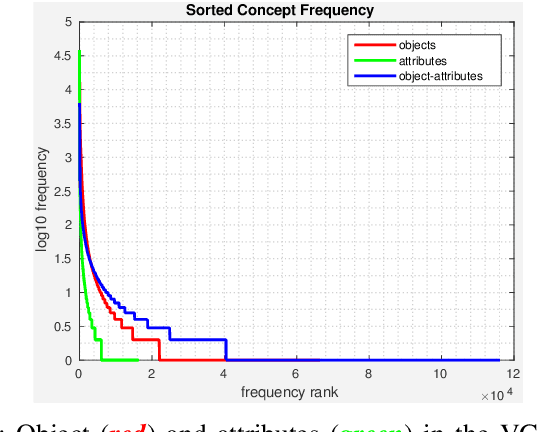
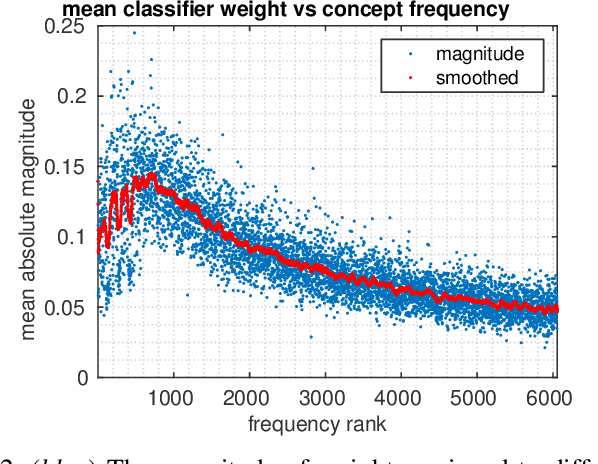
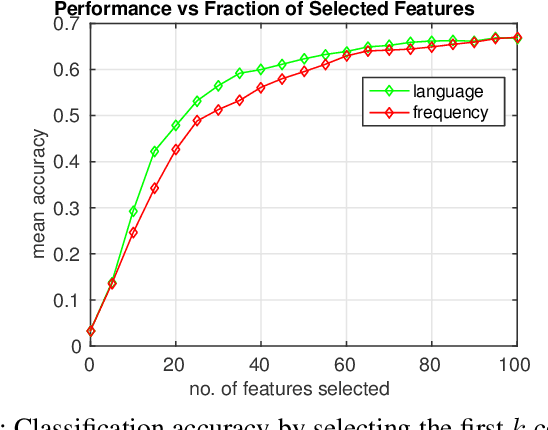
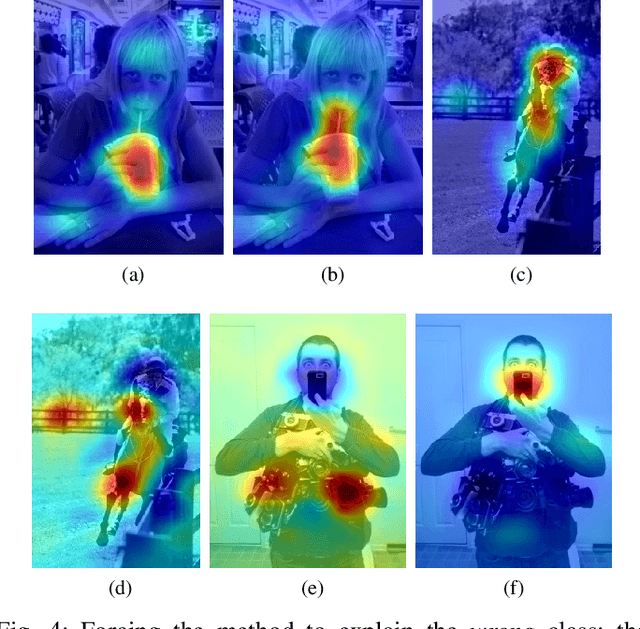
Classes in natural images tend to follow long tail distributions. This is problematic when there are insufficient training examples for rare classes. This effect is emphasized in compound classes, involving the conjunction of several concepts, such as those appearing in action-recognition datasets. In this paper, we propose to address this issue by learning how to utilize common visual concepts which are readily available. We detect the presence of prominent concepts in images and use them to infer the target labels instead of using visual features directly, combining tools from vision and natural-language processing. We validate our method on the recently introduced HICO dataset reaching a mAP of 31.54\% and on the Stanford-40 Actions dataset, where the proposed method outperforms that obtained by direct visual features, obtaining an accuracy 83.12\%. Moreover, the method provides for each class a semantically meaningful list of keywords and relevant image regions relating it to its constituent concepts.