 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Infants to AI: Incorporating Infant-like Learning in Models Boosts Efficiency and Generalization in Learning Social Prediction Tasks
Mar 05, 2025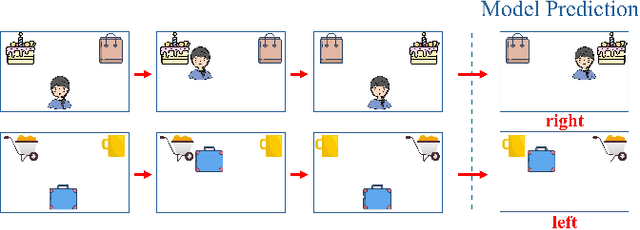
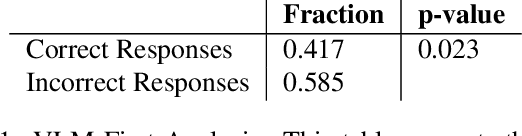
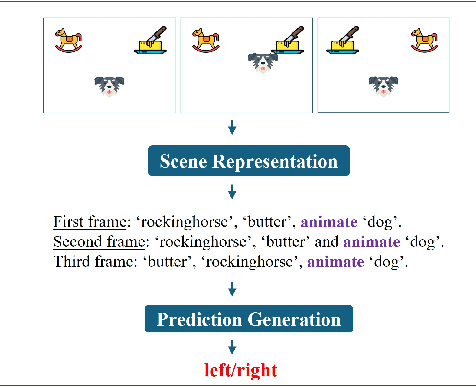

Early in development, infants learn a range of useful concepts, which can be challenging from a computational standpoint. This early learning comes together with an initial understanding of aspects of the meaning of concepts, e.g., their implications, causality, and using them to predict likely future events. All this is accomplished in many cases with little or no supervision, and from relatively few examples, compared with current network models. In learning about objects and human-object interactions, early acquired and possibly innate concepts are often used in the process of learning additional, more complex concepts. In the current work, we model how early-acquired concepts are used in the learning of subsequent concepts, and compare the results with standard deep network modeling. We focused in particular on the use of the concepts of animacy and goal attribution in learning to predict future events. We show that the use of early concepts in the learning of new concepts leads to better learning (higher accuracy) and more efficient learning (requiring less data). We further show that this integration of early and new concepts shapes the representation of the concepts acquired by the model. The results show that when the concepts were learned in a human-like manner, the emerging representation was more useful, as measured in terms of generalization to novel data and tasks. On a more general level, the results suggest that there are likely to be basic differences in the conceptual structures acquired by current network models compared to human learning.
Teaching VLMs to Localize Specific Objects from In-context Examples
Nov 20, 2024



Vision-Language Models (VLMs) have shown remarkable capabilities across diverse visual tasks, including image recognition, video understanding, and Visual Question Answering (VQA) when explicitly trained for these tasks. Despite these advances, we find that current VLMs lack a fundamental cognitive ability: learning to localize objects in a scene by taking into account the context. In this work, we focus on the task of few-shot personalized localization, where a model is given a small set of annotated images (in-context examples) -- each with a category label and bounding box -- and is tasked with localizing the same object type in a query image. To provoke personalized localization abilities in models, we present a data-centric solution that fine-tunes them using carefully curated data from video object tracking datasets. By leveraging sequences of frames tracking the same object across multiple shots, we simulate instruction-tuning dialogues that promote context awareness. To reinforce this, we introduce a novel regularization technique that replaces object labels with pseudo-names, ensuring the model relies on visual context rather than prior knowledge. Our method significantly enhances few-shot localization performance without sacrificing generalization, as demonstrated on several benchmarks tailored to personalized localization. This work is the first to explore and benchmark personalized few-shot localization for VLMs, laying a foundation for future research in context-driven vision-language applications. The code for our project is available at https://github.com/SivanDoveh/IPLoc
Towards Multimodal In-Context Learning for Vision & Language Models
Mar 19, 2024



Inspired by the emergence of Large Language Models (LLMs) that can truly understand human language, significant progress has been made in aligning other, non-language, modalities to be `understandable' by an LLM, primarily via converting their samples into a sequence of embedded language-like tokens directly fed into the LLM (decoder) input stream. However, so far limited attention has been given to transferring (and evaluating) one of the core LLM capabilities to the emerging VLMs, namely the In-Context Learning (ICL) ability, or in other words to guide VLMs to desired target downstream tasks or output structure using in-context image+text demonstrations. In this work, we dive deeper into analyzing the capabilities of some of the state-of-the-art VLMs to follow ICL instructions, discovering them to be somewhat lacking. We discover that even models that underwent large-scale mixed modality pre-training and were implicitly guided to make use of interleaved image and text information (intended to consume helpful context from multiple images) under-perform when prompted with few-shot (ICL) demonstrations, likely due to their lack of `direct' ICL instruction tuning. To test this conjecture, we propose a simple, yet surprisingly effective, strategy of extending a common VLM alignment framework with ICL support, methodology, and curriculum. We explore, analyze, and provide insights into effective data mixes, leading up to a significant 21.03% (and 11.3% on average) ICL performance boost over the strongest VLM baselines and a variety of ICL benchmarks. We also contribute new benchmarks for ICL evaluation in VLMs and discuss their advantages over the prior art.
Efficient Rehearsal Free Zero Forgetting Continual Learning using Adaptive Weight Modulation
Nov 26, 2023



Artificial neural networks encounter a notable challenge known as continual learning, which involves acquiring knowledge of multiple tasks over an extended period. This challenge arises due to the tendency of previously learned weights to be adjusted to suit the objectives of new tasks, resulting in a phenomenon called catastrophic forgetting. Most approaches to this problem seek a balance between maximizing performance on the new tasks and minimizing the forgetting of previous tasks. In contrast, our approach attempts to maximize the performance of the new task, while ensuring zero forgetting. This is accomplished by creating a task-specific modulation parameters for each task. Only these would be learnable parameters during learning of consecutive tasks. Through comprehensive experimental evaluations, our model demonstrates superior performance in acquiring and retaining novel tasks that pose difficulties for other multi-task models. This emphasizes the efficacy of our approach in preventing catastrophic forgetting while accommodating the acquisition of new tasks
Top-Down Processing: Top-Down Network Combines Back-Propagation with Attention
Jun 04, 2023



Early neural network models relied exclusively on bottom-up processing going from the input signals to higher-level representations. Many recent models also incorporate top-down networks going in the opposite direction. Top-down processing in deep learning models plays two primary roles: learning and directing attention. These two roles are accomplished in current models through distinct mechanisms. While top-down attention is often implemented by extending the model's architecture with additional units that propagate information from high to low levels of the network, learning is typically accomplished by an external learning algorithm such as back-propagation. In the current work, we present an integration of the two functions above, which appear unrelated, using a single unified mechanism. We propose a novel symmetric bottom-up top-down network structure that can integrate standard bottom-up networks with a symmetric top-down counterpart, allowing each network to guide and influence the other. The same top-down network is being used for both learning, via back-propagating feedback signals, and at the same time also for top-down attention, by guiding the bottom-up network to perform a selected task. We show that our method achieves competitive performance on a standard multi-task learning benchmark. Yet, we rely on standard single-task architectures and optimizers, without any task-specific parameters. Additionally, our learning algorithm addresses in a new way some neuroscience issues that arise in biological modeling of learning in the brain.
Dense and Aligned Captions (DAC) Promote Compositional Reasoning in VL Models
Jun 01, 2023



Vision and Language (VL) models offer an effective method for aligning representation spaces of images and text, leading to numerous applications such as cross-modal retrieval, visual question answering, captioning, and more. However, the aligned image-text spaces learned by all the popular VL models are still suffering from the so-called `object bias' - their representations behave as `bags of nouns', mostly ignoring or downsizing the attributes, relations, and states of objects described/appearing in texts/images. Although some great attempts at fixing these `compositional reasoning' issues were proposed in the recent literature, the problem is still far from being solved. In this paper, we uncover two factors limiting the VL models' compositional reasoning performance. These two factors are properties of the paired VL dataset used for finetuning and pre-training the VL model: (i) the caption quality, or in other words `image-alignment', of the texts; and (ii) the `density' of the captions in the sense of mentioning all the details appearing on the image. We propose a fine-tuning approach for automatically treating these factors leveraging a standard VL dataset (CC3M). Applied to CLIP, we demonstrate its significant compositional reasoning performance increase of up to $\sim27\%$ over the base model, up to $\sim20\%$ over the strongest baseline, and by $6.7\%$ on average.
Teaching Structured Vision&Language Concepts to Vision&Language Models
Nov 21, 2022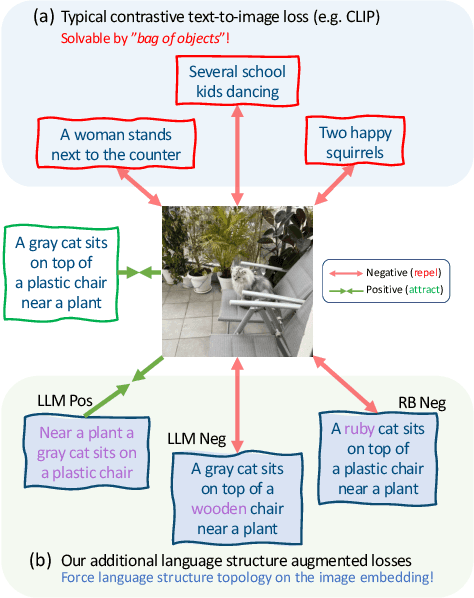
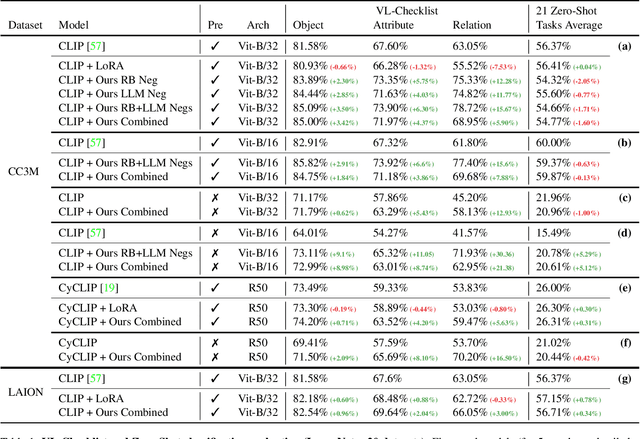
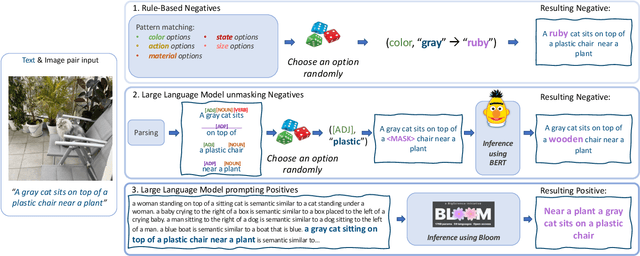

Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, some aspects of complex language understanding still remain a challenge. We introduce the collective notion of Structured Vision&Language Concepts (SVLC) which includes object attributes, relations, and states which are present in the text and visible in the image. Recent studies have shown that even the best VL models struggle with SVLC. A possible way of fixing this issue is by collecting dedicated datasets for teaching each SVLC type, yet this might be expensive and time-consuming. Instead, we propose a more elegant data-driven approach for enhancing VL models' understanding of SVLCs that makes more effective use of existing VL pre-training datasets and does not require any additional data. While automatic understanding of image structure still remains largely unsolved, language structure is much better modeled and understood, allowing for its effective utilization in teaching VL models. In this paper, we propose various techniques based on language structure understanding that can be used to manipulate the textual part of off-the-shelf paired VL datasets. VL models trained with the updated data exhibit a significant improvement of up to 15% in their SVLC understanding with only a mild degradation in their zero-shot capabilities both when training from scratch or fine-tuning a pre-trained model.
A model for full local image interpretation
Oct 17, 2021



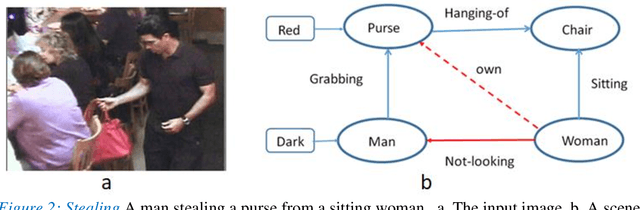
We describe a computational model of humans' ability to provide a detailed interpretation of components in a scene. Humans can identify in an image meaningful components almost everywhere, and identifying these components is an essential part of the visual process, and of understanding the surrounding scene and its potential meaning to the viewer. Detailed interpretation is beyond the scope of current models of visual recognition. Our model suggests that this is a fundamental limitation, related to the fact that existing models rely on feed-forward but limited top-down processing. In our model, a first recognition stage leads to the initial activation of class candidates, which is incomplete and with limited accuracy. This stage then triggers the application of class-specific interpretation and validation processes, which recover richer and more accurate interpretation of the visible scene. We discuss implications of the model for visual interpretation by humans and by computer vision models.
* Published in the Proceedings of the 37th Annual Meeting of the Cognitive Science Society (CogSci), 2015
Image interpretation by iterative bottom-up top-down processing
May 12, 2021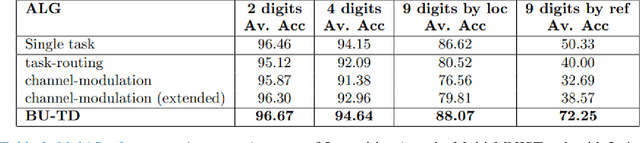

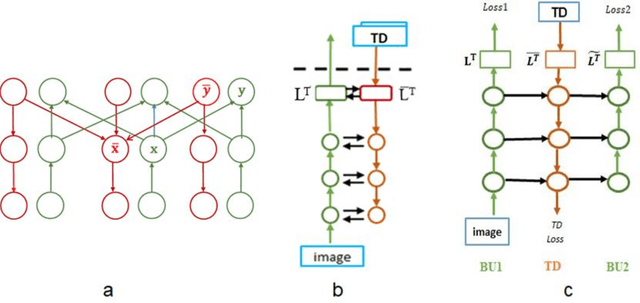
Scene understanding requires the extraction and representation of scene components together with their properties and inter-relations. We describe a model in which meaningful scene structures are extracted from the image by an iterative process, combining bottom-up (BU) and top-down (TD) networks, interacting through a symmetric bi-directional communication between them (counter-streams structure). The model constructs a scene representation by the iterative use of three components. The first model component is a BU stream that extracts selected scene elements, properties and relations. The second component (cognitive augmentation) augments the extracted visual representation based on relevant non-visual stored representations. It also provides input to the third component, the TD stream, in the form of a TD instruction, instructing the model what task to perform next. The TD stream then guides the BU visual stream to perform the selected task in the next cycle. During this process, the visual representations extracted from the image can be combined with relevant non-visual representations, so that the final scene representation is based on both visual information extracted from the scene and relevant stored knowledge of the world. We describe how a sequence of TD-instructions is used to extract from the scene structures of interest, including an algorithm to automatically select the next TD-instruction in the sequence. The extraction process is shown to have favorable properties in terms of combinatorial generalization, generalizing well to novel scene structures and new combinations of objects, properties and relations not seen during training. Finally, we compare the model with relevant aspects of the human vision, and suggest directions for using the BU-TD scheme for integrating visual and cognitive components in the process of scene understanding.
Detector-Free Weakly Supervised Grounding by Separation
Apr 20, 2021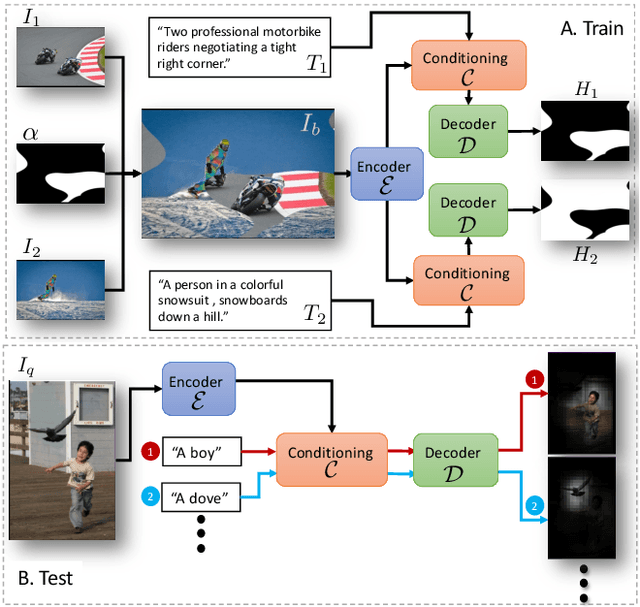
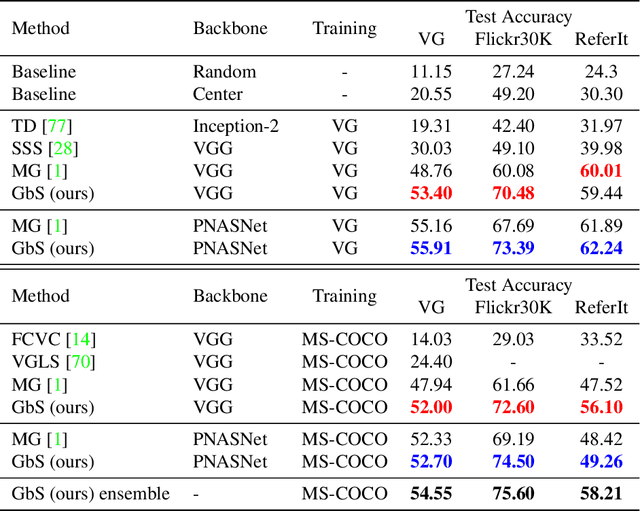
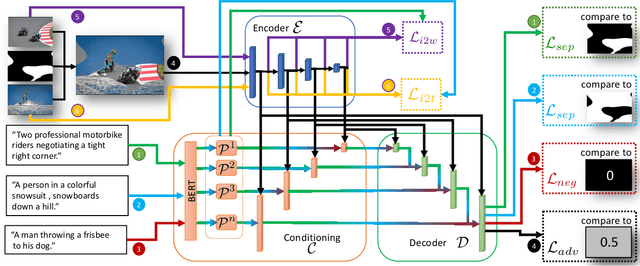
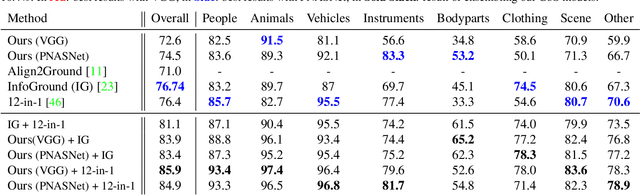
Nowadays, there is an abundance of data involving images and surrounding free-form text weakly corresponding to those images. Weakly Supervised phrase-Grounding (WSG) deals with the task of using this data to learn to localize (or to ground) arbitrary text phrases in images without any additional annotations. However, most recent SotA methods for WSG assume the existence of a pre-trained object detector, relying on it to produce the ROIs for localization. In this work, we focus on the task of Detector-Free WSG (DF-WSG) to solve WSG without relying on a pre-trained detector. We directly learn everything from the images and associated free-form text pairs, thus potentially gaining an advantage on the categories unsupported by the detector. The key idea behind our proposed Grounding by Separation (GbS) method is synthesizing `text to image-regions' associations by random alpha-blending of arbitrary image pairs and using the corresponding texts of the pair as conditions to recover the alpha map from the blended image via a segmentation network. At test time, this allows using the query phrase as a condition for a non-blended query image, thus interpreting the test image as a composition of a region corresponding to the phrase and the complement region. Using this approach we demonstrate a significant accuracy improvement, of up to $8.5\%$ over previous DF-WSG SotA, for a range of benchmarks including Flickr30K, Visual Genome, and ReferIt, as well as a significant complementary improvement (above $7\%$) over the detector-based approaches for WSG.