 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-Down Processing: Top-Down Network Combines Back-Propagation with Attention
Jun 04, 2023



Early neural network models relied exclusively on bottom-up processing going from the input signals to higher-level representations. Many recent models also incorporate top-down networks going in the opposite direction. Top-down processing in deep learning models plays two primary roles: learning and directing attention. These two roles are accomplished in current models through distinct mechanisms. While top-down attention is often implemented by extending the model's architecture with additional units that propagate information from high to low levels of the network, learning is typically accomplished by an external learning algorithm such as back-propagation. In the current work, we present an integration of the two functions above, which appear unrelated, using a single unified mechanism. We propose a novel symmetric bottom-up top-down network structure that can integrate standard bottom-up networks with a symmetric top-down counterpart, allowing each network to guide and influence the other. The same top-down network is being used for both learning, via back-propagating feedback signals, and at the same time also for top-down attention, by guiding the bottom-up network to perform a selected task. We show that our method achieves competitive performance on a standard multi-task learning benchmark. Yet, we rely on standard single-task architectures and optimizers, without any task-specific parameters. Additionally, our learning algorithm addresses in a new way some neuroscience issues that arise in biological modeling of learning in the brain.
Topological based classification using graph convolutional networks
Oct 26, 2019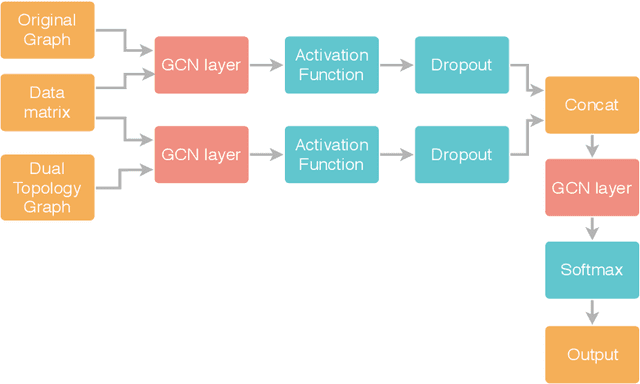
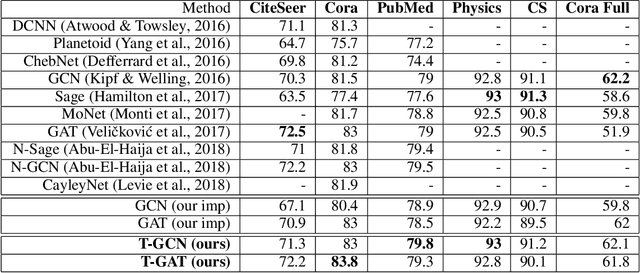
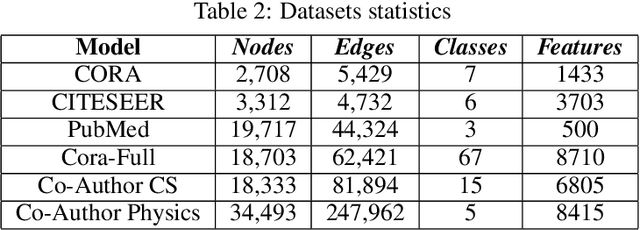
In colored graphs, node classes are often associated with either their neighbors class or with information not incorporated in the graph associated with each node. We here propose that node classes are also associated with topological features of the nodes. We use this association to improve Graph machine learning in general and specifically, Graph Convolutional Networks (GCN). First, we show that even in the absence of any external information on nodes, a good accuracy can be obtained on the prediction of the node class using either topological features, or using the neighbors class as an input to a GCN. This accuracy is slightly less than the one that can be obtained using content based GCN. Secondly, we show that explicitly adding the topology as an input to the GCN does not improve the accuracy when combined with external information on nodes. However, adding an additional adjacency matrix with edges between distant nodes with similar topology to the GCN does significantly improve its accuracy, leading to results better than all state of the art methods in multiple datasets.
Regional based query in graph active learning
Jun 20, 2019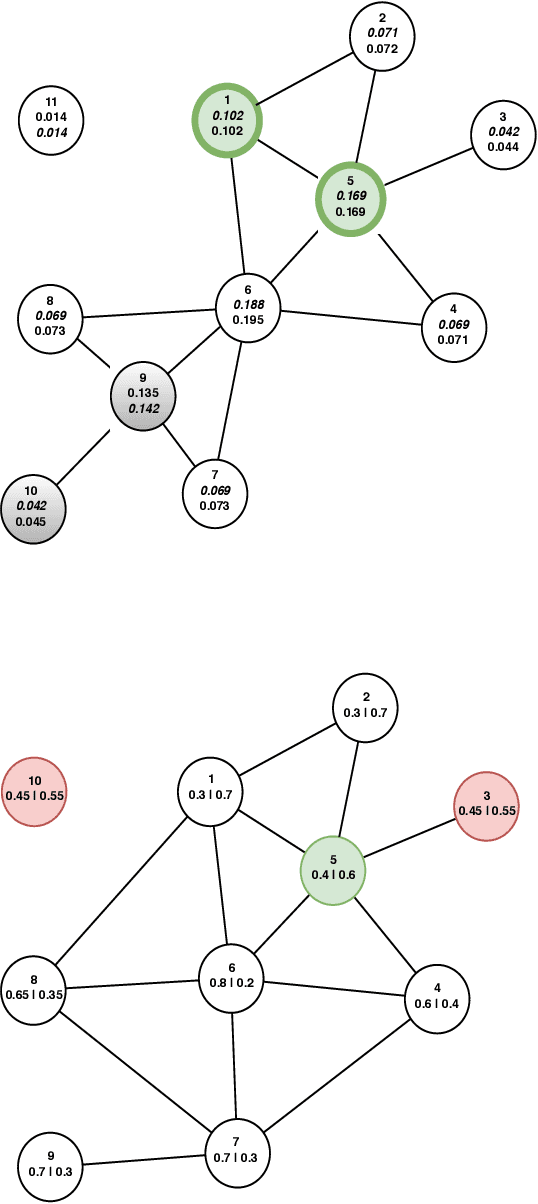
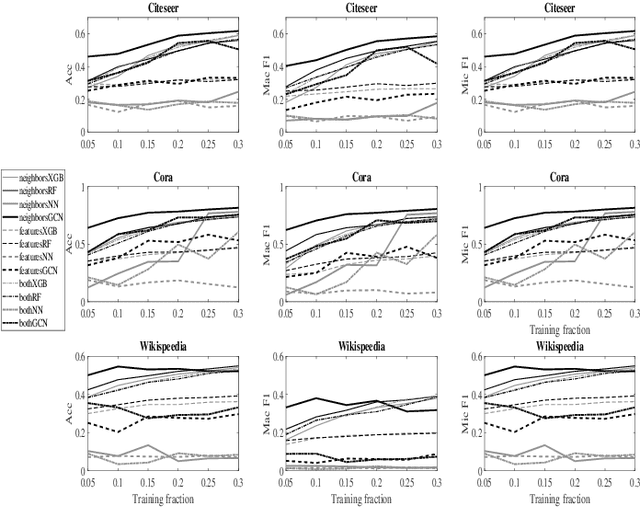
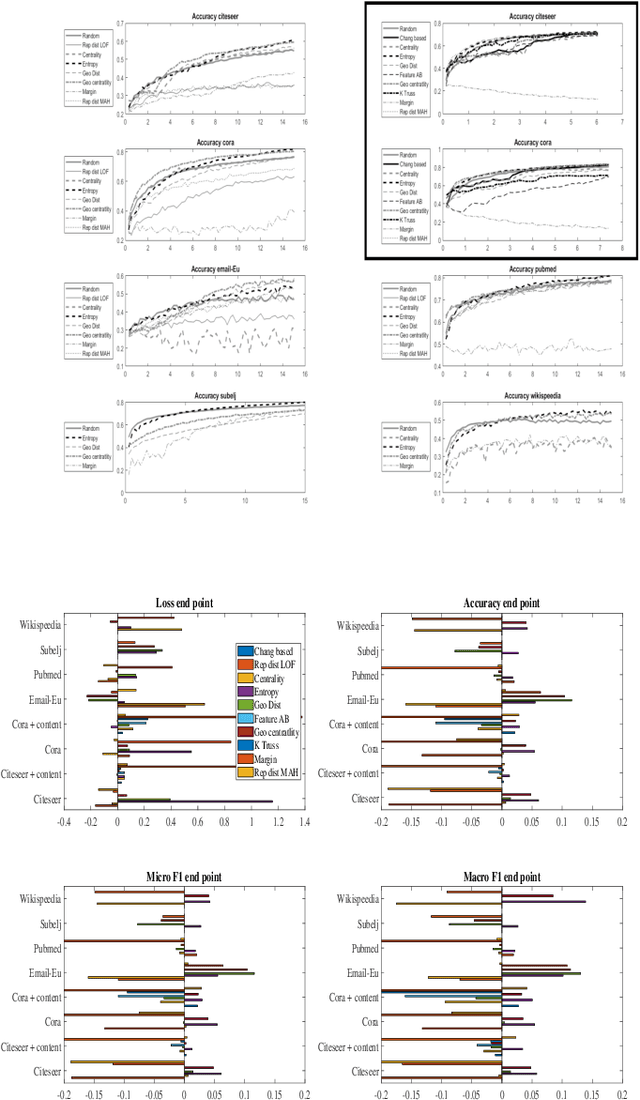
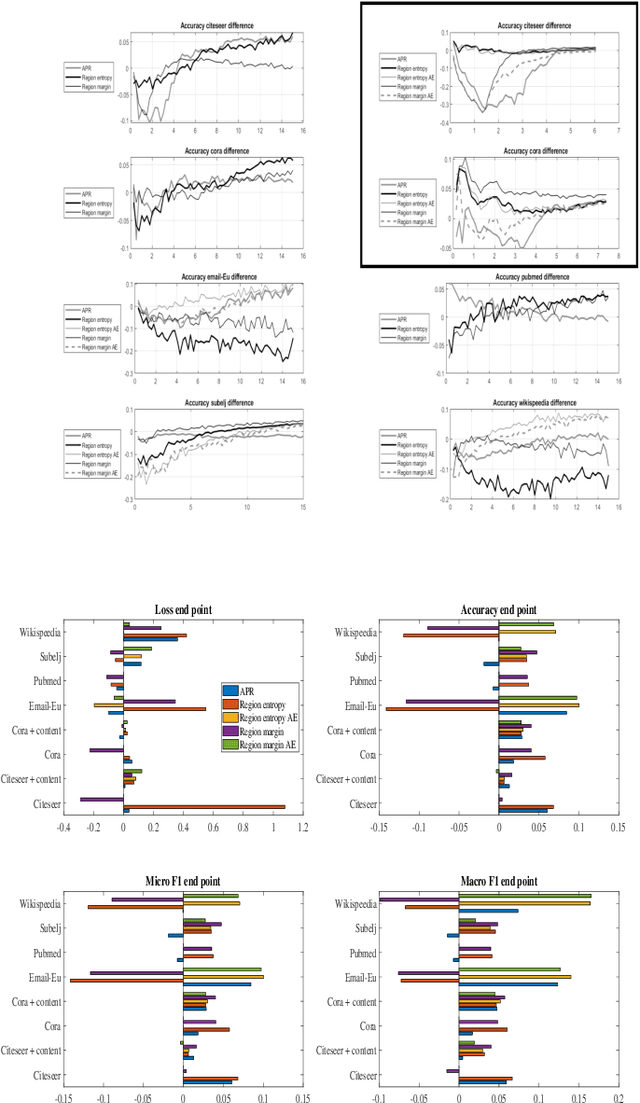
Graph convolution networks (GCN) have emerged as the leading method to classify node classes in networks, and have reached the highest accuracy in multiple node classification tasks. In the absence of available tagged samples, active learning methods have been developed to obtain the highest accuracy using the minimal number of queries to an oracle. The current best active learning methods use the sample class uncertainty as selection criteria. However, in graph based classification, the class of each node is often related to the class of its neighbors. As such, the uncertainty in the class of a node's neighbor may be a more appropriate selection criterion. We here propose two such criteria, one extending the classical uncertainty measure, and the other extending the page-rank algorithm. We show that the latter is optimal when the fraction of tagged nodes is low, and when this fraction grows to one over the average degree, the regional uncertainty performs better than all existing methods. While we have tested this methods on graphs, such methods can be extended to any classification problem, where a distance metrics can be defined between the input samples. All the code used can be accessed at : https://github.com/louzounlab/graph-al All the datasets used can be accessed at : https://github.com/louzounlab/DataSets