 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Like Coarse Object Representations in Vision Models
Feb 12, 2026Humans appear to represent objects for intuitive physics with coarse, volumetric bodies'' that smooth concavities - trading fine visual details for efficient physical predictions - yet their internal structure is largely unknown. Segmentation models, in contrast, optimize pixel-accurate masks that may misalign with such bodies. We ask whether and when these models nonetheless acquire human-like bodies. Using a time-to-collision (TTC) behavioral paradigm, we introduce a comparison pipeline and alignment metric, then vary model training time, size, and effective capacity via pruning. Across all manipulations, alignment with human behavior follows an inverse U-shaped curve: small/briefly trained/pruned models under-segment into blobs; large/fully trained models over-segment with boundary wiggles; and an intermediate ideal body granularity'' best matches humans. This suggests human-like coarse bodies emerge from resource constraints rather than bespoke biases, and points to simple knobs - early checkpoints, modest architectures, light pruning - for eliciting physics-efficient representations. We situate these results within resource-rational accounts balancing recognition detail against physical affordances.
CrossVideoMAE: Self-Supervised Image-Video Representation Learning with Masked Autoencoders
Feb 08, 2025Current video-based Masked Autoencoders (MAEs) primarily focus on learning effective spatiotemporal representations from a visual perspective, which may lead the model to prioritize general spatial-temporal patterns but often overlook nuanced semantic attributes like specific interactions or sequences that define actions - such as action-specific features that align more closely with human cognition for space-time correspondence. This can limit the model's ability to capture the essence of certain actions that are contextually rich and continuous. Humans are capable of mapping visual concepts, object view invariance, and semantic attributes available in static instances to comprehend natural dynamic scenes or videos. Existing MAEs for videos and static images rely on separate datasets for videos and images, which may lack the rich semantic attributes necessary for fully understanding the learned concepts, especially when compared to using video and corresponding sampled frame images together. To this end, we propose CrossVideoMAE an end-to-end self-supervised cross-modal contrastive learning MAE that effectively learns both video-level and frame-level rich spatiotemporal representations and semantic attributes. Our method integrates mutual spatiotemporal information from videos with spatial information from sampled frames within a feature-invariant space, while encouraging invariance to augmentations within the video domain. This objective is achieved through jointly embedding features of visible tokens and combining feature correspondence within and across modalities, which is critical for acquiring rich, label-free guiding signals from both video and frame image modalities in a self-supervised manner. Extensive experiments demonstrate that our approach surpasses previous state-of-the-art methods and ablation studies validate the effectiveness of our approach.
How Effective are Self-Supervised Models for Contact Identification in Videos
Aug 01, 2024



The exploration of video content via Self-Supervised Learning (SSL) models has unveiled a dynamic field of study, emphasizing both the complex challenges and unique opportunities inherent in this area. Despite the growing body of research, the ability of SSL models to detect physical contacts in videos remains largely unexplored, particularly the effectiveness of methods such as downstream supervision with linear probing or full fine-tuning. This work aims to bridge this gap by employing eight different convolutional neural networks (CNNs) based video SSL models to identify instances of physical contact within video sequences specifically. The Something-Something v2 (SSv2) and Epic-Kitchen (EK-100) datasets were chosen for evaluating these approaches due to the promising results on UCF101 and HMDB51, coupled with their limited prior assessment on SSv2 and EK-100. Additionally, these datasets feature diverse environments and scenarios, essential for testing the robustness and accuracy of video-based models. This approach not only examines the effectiveness of each model in recognizing physical contacts but also explores the performance in the action recognition downstream task. By doing so, valuable insights into the adaptability of SSL models in interpreting complex, dynamic visual information are contributed.
Why Not Use Your Textbook? Knowledge-Enhanced Procedure Planning of Instructional Videos
Mar 05, 2024



In this paper, we explore the capability of an agent to construct a logical sequence of action steps, thereby assembling a strategic procedural plan. This plan is crucial for navigating from an initial visual observation to a target visual outcome, as depicted in real-life instructional videos. Existing works have attained partial success by extensively leveraging various sources of information available in the datasets, such as heavy intermediate visual observations, procedural names, or natural language step-by-step instructions, for features or supervision signals. However, the task remains formidable due to the implicit causal constraints in the sequencing of steps and the variability inherent in multiple feasible plans. To tackle these intricacies that previous efforts have overlooked, we propose to enhance the capabilities of the agent by infusing it with procedural knowledge. This knowledge, sourced from training procedure plans and structured as a directed weighted graph, equips the agent to better navigate the complexities of step sequencing and its potential variations. We coin our approach KEPP, a novel Knowledge-Enhanced Procedure Planning system, which harnesses a probabilistic procedural knowledge graph extracted from training data, effectively acting as a comprehensive textbook for the training domain. Experimental evaluations across three widely-used datasets under settings of varying complexity reveal that KEPP attains superior, state-of-the-art results while requiring only minimal supervision.
A model for full local image interpretation
Oct 17, 2021



We describe a computational model of humans' ability to provide a detailed interpretation of components in a scene. Humans can identify in an image meaningful components almost everywhere, and identifying these components is an essential part of the visual process, and of understanding the surrounding scene and its potential meaning to the viewer. Detailed interpretation is beyond the scope of current models of visual recognition. Our model suggests that this is a fundamental limitation, related to the fact that existing models rely on feed-forward but limited top-down processing. In our model, a first recognition stage leads to the initial activation of class candidates, which is incomplete and with limited accuracy. This stage then triggers the application of class-specific interpretation and validation processes, which recover richer and more accurate interpretation of the visible scene. We discuss implications of the model for visual interpretation by humans and by computer vision models.
* Published in the Proceedings of the 37th Annual Meeting of the Cognitive Science Society (CogSci), 2015
To Which Out-Of-Distribution Object Orientations Are DNNs Capable of Generalizing?
Sep 28, 2021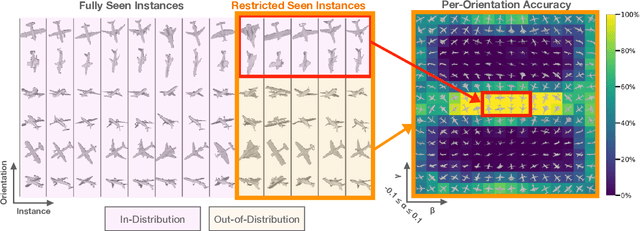
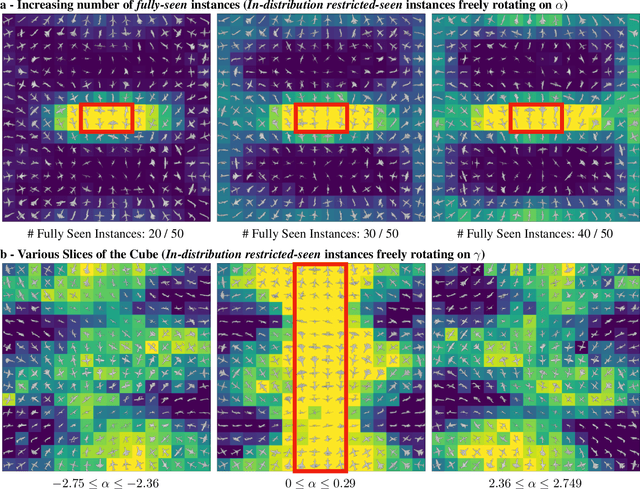

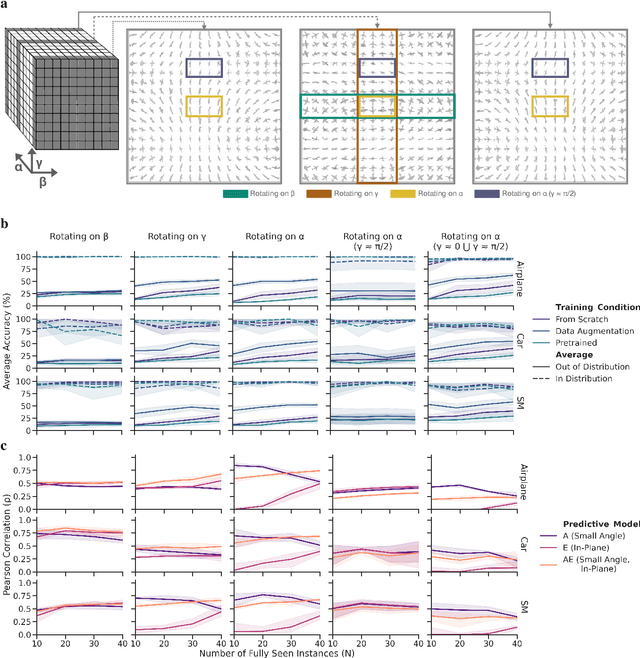
The capability of Deep Neural Networks (DNNs) to recognize objects in orientations outside the distribution of the training data, ie. out-of-distribution (OoD) orientations, is not well understood. For humans, behavioral studies showed that recognition accuracy varies across OoD orientations, where generalization is much better for some orientations than for others. In contrast, for DNNs, it remains unknown how generalization abilities are distributed among OoD orientations. In this paper, we investigate the limitations of DNNs' generalization capacities by systematically inspecting patterns of success and failure of DNNs across OoD orientations. We use an intuitive and controlled, yet challenging learning paradigm, in which some instances of an object category are seen at only a few geometrically restricted orientations, while other instances are seen at all orientations. The effect of data diversity is also investigated by increasing the number of instances seen at all orientations in the training set. We present a comprehensive analysis of DNNs' generalization abilities and limitations for representative architectures (ResNet, Inception, DenseNet and CORnet). Our results reveal an intriguing pattern -- DNNs are only capable of generalizing to instances of objects that appear like 2D, ie. in-plane, rotations of in-distribution orientations.
What takes the brain so long: Object recognition at the level of minimal images develops for up to seconds of presentation time
Jun 09, 2020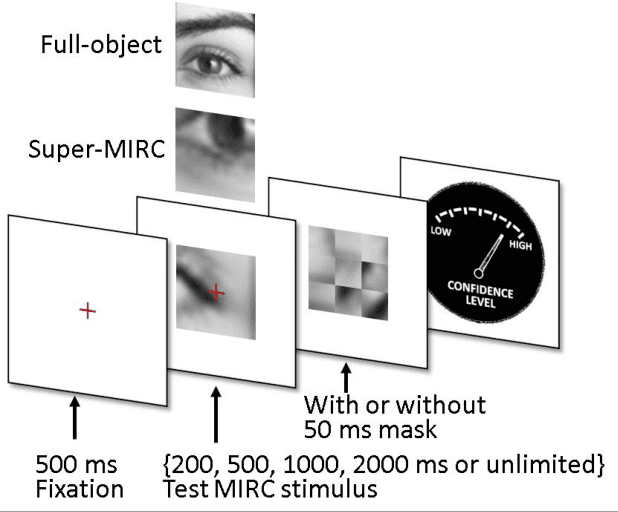
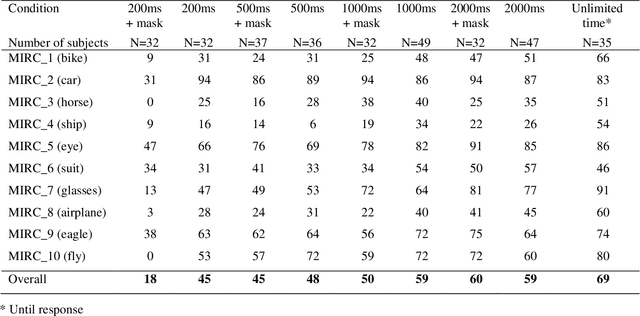
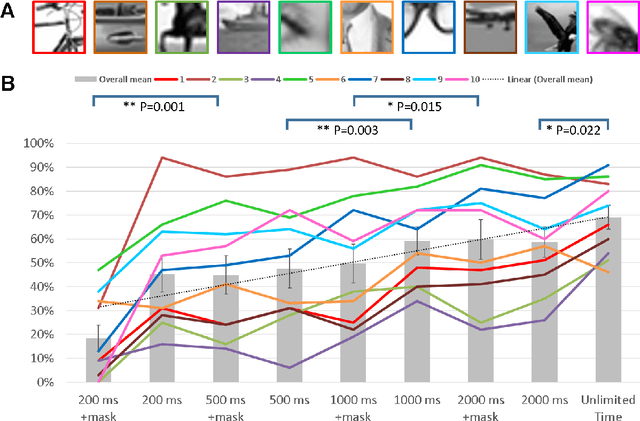
Rich empirical evidence has shown that visual object recognition in the brain is fast and effortless, with relevant brain signals reported to start as early as 80 ms. Here we study the time trajectory of the recognition process at the level of minimal recognizable images (termed MIRC). These are images that can be recognized reliably, but in which a minute change of the image (reduction by either size or resolution) has a drastic effect on recognition. Subjects were assigned to one of nine exposure conditions: 200, 500, 1000, 2000 ms with or without masking, as well as unlimited time. The subjects were not limited in time to respond after presentation. The results show that in the masked conditions, recognition rates develop gradually over an extended period, e.g. average of 18% for 200 ms exposure and 45% for 500 ms, increasing significantly with longer exposure even above 2 secs. When presented for unlimited time (until response), MIRC recognition rates were equivalent to the rates of full-object images presented for 50 ms followed by masking. What takes the brain so long to recognize such images? We discuss why processes involving eye-movements, perceptual decision-making and pattern completion are unlikely explanations. Alternatively, we hypothesize that MIRC recognition requires an extended top-down process complementing the feed-forward phase.
Using Motion and Internal Supervision in Object Recognition
Dec 13, 2018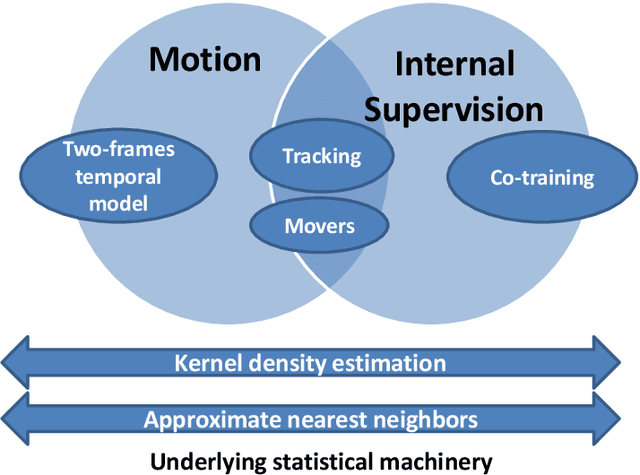
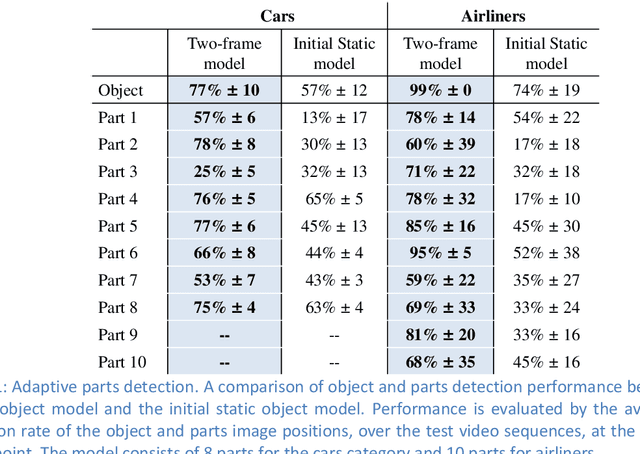
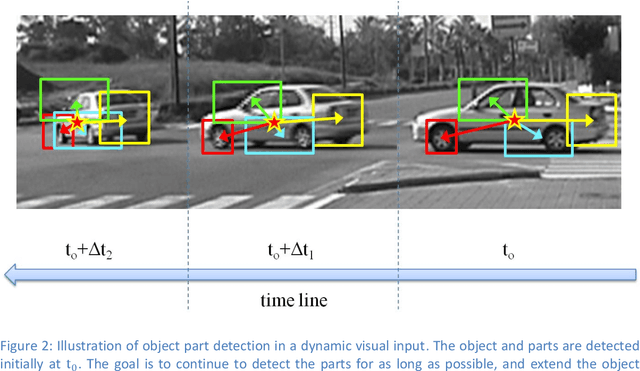
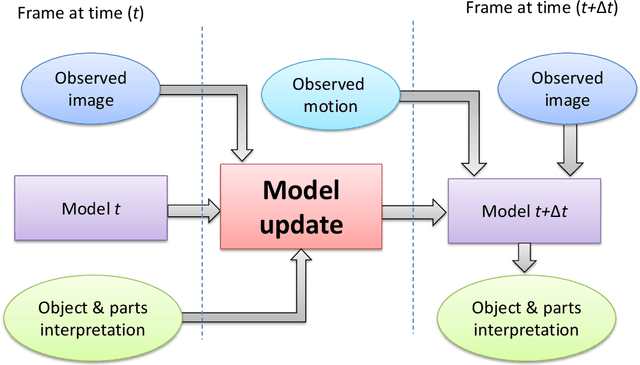
In this thesis we address two related aspects of visual object recognition: the use of motion information, and the use of internal supervision, to help unsupervised learning. These two aspects are inter-related in the current study, since image motion is used for internal supervision, via the detection of spatiotemporal events of active-motion and the use of tracking. Most current work in object recognition deals with static images during both learning and recognition. In contrast, we are interested in a dynamic scene where visual processes, such as detecting motion events and tracking, contribute spatiotemporal information, which is useful for object attention, motion segmentation, 3-D understanding and object interactions. We explore the use of these sources of information in both learning and recognition processes. In the first part of the work, we demonstrate how motion can be used for adaptive detection of object-parts in dynamic environments, while automatically learning new object appearances and poses. In the second and main part of the study we develop methods for using specific types of visual motion to solve two difficult problems in unsupervised visual learning: learning to recognize hands by their appearance and by context, and learning to extract direction of gaze. We use our conclusions in this part to propose a model for several aspects of learning by human infants from their visual environment.
Large Field and High Resolution: Detecting Needle in Haystack
Apr 10, 2018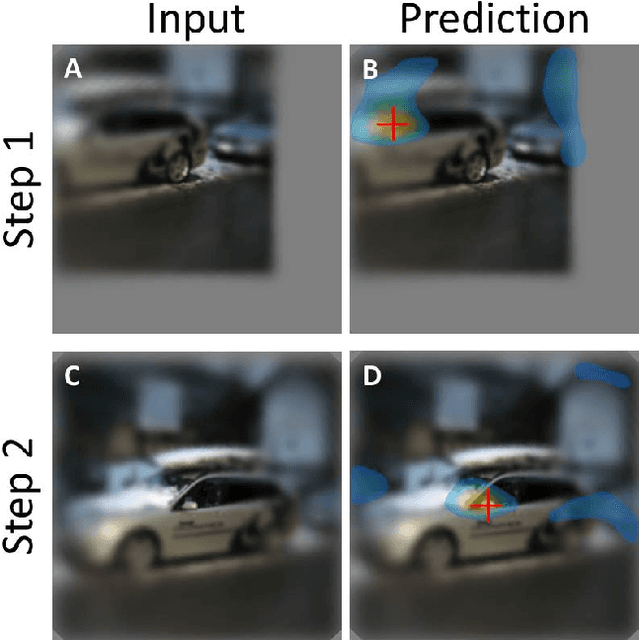

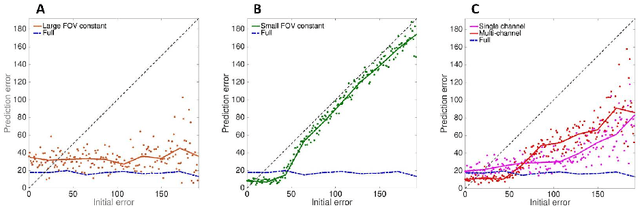
The growing use of convolutional neural networks (CNN) for a broad range of visual tasks, including tasks involving fine details, raises the problem of applying such networks to a large field of view, since the amount of computations increases significantly with the number of pixels. To deal effectively with this difficulty, we develop and compare methods of using CNNs for the task of small target localization in natural images, given a limited "budget" of samples to form an image. Inspired in part by human vision, we develop and compare variable sampling schemes, with peak resolution at the center and decreasing resolution with eccentricity, applied iteratively by re-centering the image at the previous predicted target location. The results indicate that variable resolution models significantly outperform constant resolution models. Surprisingly, variable resolution models and in particular multi-channel models, outperform the optimal, "budget-free" full-resolution model, using only 5\% of the samples.
Discovery and usage of joint attention in images
Apr 10, 2018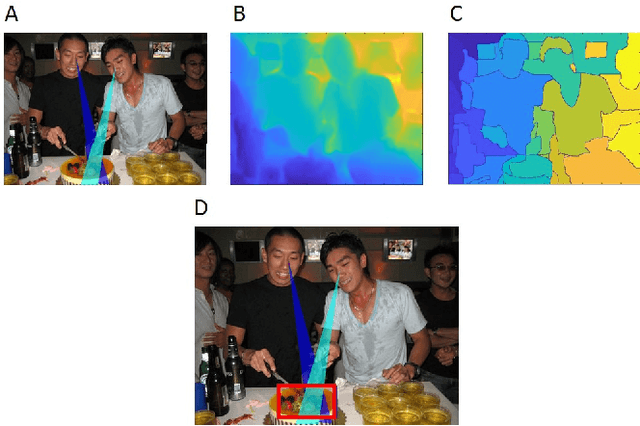


Joint visual attention is characterized by two or more individuals looking at a common target at the same time. The ability to identify joint attention in scenes, the people involved, and their common target, is fundamental to the understanding of social interactions, including others' intentions and goals. In this work we deal with the extraction of joint attention events, and the use of such events for image descriptions. The work makes two novel contributions. First, our extraction algorithm is the first which identifies joint visual attention in single static images. It computes 3D gaze direction, identifies the gaze target by combining gaze direction with a 3D depth map computed for the image, and identifies the common gaze target. Second, we use a human study to demonstrate the sensitivity of humans to joint attention, suggesting that the detection of such a configuration in an image can be useful for understanding the image, including the goals of the agents and their joint activity, and therefore can contribute to image captioning and related tasks.