 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery and usage of joint attention in images
Paper and Code
Apr 10, 2018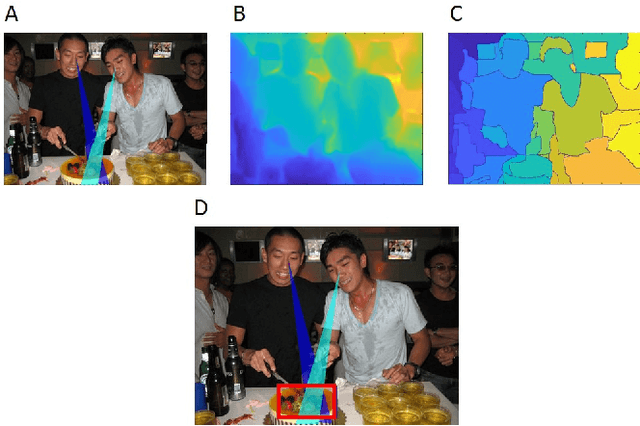


Joint visual attention is characterized by two or more individuals looking at a common target at the same time. The ability to identify joint attention in scenes, the people involved, and their common target, is fundamental to the understanding of social interactions, including others' intentions and goals. In this work we deal with the extraction of joint attention events, and the use of such events for image descriptions. The work makes two novel contributions. First, our extraction algorithm is the first which identifies joint visual attention in single static images. It computes 3D gaze direction, identifies the gaze target by combining gaze direction with a 3D depth map computed for the image, and identifies the common gaze target. Second, we use a human study to demonstrate the sensitivity of humans to joint attention, suggesting that the detection of such a configuration in an image can be useful for understanding the image, including the goals of the agents and their joint activity, and therefore can contribute to image captioning and related tasks.