 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeqAttCNN - Self Attention Mechanism for Video QoE Prediction in Encrypted Traffic
Jan 11, 2026The rapid growth of multimedia consumption, driven by major advances in mobile devices since the mid-2000s, has led to widespread use of video conferencing applications (VCAs) such as Zoom and Google Meet, as well as instant messaging applications (IMAs) like WhatsApp and Telegram, which increasingly support video conferencing as a core feature. Many of these systems rely on the Web Real-Time Communication (WebRTC) protocol, enabling direct peer-to-peer media streaming without requiring a third-party server to relay data, reducing the latency and facilitating a real-time communication. Despite WebRTC's potential, adverse network conditions can degrade streaming quality and consequently reduce users' Quality of Experience (QoE). Maintaining high QoE therefore requires continuous monitoring and timely intervention when QoE begins to deteriorate. While content providers can often estimate QoE by directly comparing transmitted and received media, this task is significantly more challenging for internet service providers (ISPs). End-to-end encryption, commonly used by modern VCAs and IMAs, prevent ISPs from accessing the original media stream, leaving only Quality of Service (QoS) and routing information available. To address this limitation, we propose the QoE Attention Convolutional Neural Network (qAttCNN), a model that leverages packet size parameter of the traffic to infer two no-reference QoE metrics viz. BRISQUE and frames per second (FPS). We evaluate qAttCNN on a custom dataset collected from WhatsApp video calls and compare it against existing QoE models. Using mean absolute error percentage (MAEP), our approach achieves 2.14% error for BRISQUE and 7.39% for FPS prediction.
CrossVideoMAE: Self-Supervised Image-Video Representation Learning with Masked Autoencoders
Feb 08, 2025Current video-based Masked Autoencoders (MAEs) primarily focus on learning effective spatiotemporal representations from a visual perspective, which may lead the model to prioritize general spatial-temporal patterns but often overlook nuanced semantic attributes like specific interactions or sequences that define actions - such as action-specific features that align more closely with human cognition for space-time correspondence. This can limit the model's ability to capture the essence of certain actions that are contextually rich and continuous. Humans are capable of mapping visual concepts, object view invariance, and semantic attributes available in static instances to comprehend natural dynamic scenes or videos. Existing MAEs for videos and static images rely on separate datasets for videos and images, which may lack the rich semantic attributes necessary for fully understanding the learned concepts, especially when compared to using video and corresponding sampled frame images together. To this end, we propose CrossVideoMAE an end-to-end self-supervised cross-modal contrastive learning MAE that effectively learns both video-level and frame-level rich spatiotemporal representations and semantic attributes. Our method integrates mutual spatiotemporal information from videos with spatial information from sampled frames within a feature-invariant space, while encouraging invariance to augmentations within the video domain. This objective is achieved through jointly embedding features of visible tokens and combining feature correspondence within and across modalities, which is critical for acquiring rich, label-free guiding signals from both video and frame image modalities in a self-supervised manner. Extensive experiments demonstrate that our approach surpasses previous state-of-the-art methods and ablation studies validate the effectiveness of our approach.
Revisiting Information Cascades in Online Social Networks
Aug 01, 2022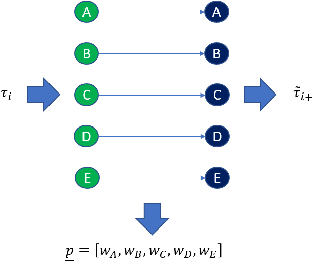


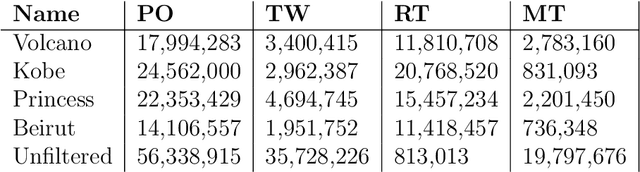
It's by now folklore that to understand the activity pattern of a user in an online social network (OSN) platform, one needs to look at his friends or the ones he follows. The common perception is that these friends exert influence on the user, effecting his decision whether to re-share content or not. Hinging upon this intuition, a variety of models were developed to predict how information propagates in OSN, similar to the way infection spreads in the population. In this paper, we revisit this world view and arrive at new conclusions. Given a set of users $V$, we study the task of predicting whether a user $u \in V$ will re-share content by some $v \in V$ at the following time window given the activity of all the users in $V$ in the previous time window. We design several algorithms for this task, ranging from a simple greedy algorithm that only learns $u$'s conditional probability distribution, ignoring the rest of $V$, to a convolutional neural network-based algorithm that receives the activity of all of $V$, but does not receive explicitly the social link structure. We tested our algorithms on four datasets that we collected from Twitter, each revolving around a different popular topic in 2020. The best performance, average F1-score of 0.86 over the four datasets, was achieved by the convolutional neural network. The simple, social-link ignorant, algorithm achieved an average F1-score of 0.78.