 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Learning in the Wild: Towards Algorithmic Understanding of Neural Networks
Dec 15, 2024Explainable AI (XAI) methods typically focus on identifying essential input features or more abstract concepts for tasks like image or text classification. However, for algorithmic tasks like combinatorial optimization, these concepts may depend not only on the input but also on the current state of the network, like in the graph neural networks (GNN) case. This work studies concept learning for an existing GNN model trained to solve Boolean satisfiability (SAT). \textcolor{black}{Our analysis reveals that the model learns key concepts matching those guiding human-designed SAT heuristics, particularly the notion of 'support.' We demonstrate that these concepts are encoded in the top principal components (PCs) of the embedding's covariance matrix, allowing for unsupervised discovery. Using sparse PCA, we establish the minimality of these concepts and show their teachability through a simplified GNN. Two direct applications of our framework are (a) We improve the convergence time of the classical WalkSAT algorithm and (b) We use the discovered concepts to "reverse-engineer" the black-box GNN and rewrite it as a white-box textbook algorithm. Our results highlight the potential of concept learning in understanding and enhancing algorithmic neural networks for combinatorial optimization tasks.
Learning Aggregation Rules in Participatory Budgeting: A Data-Driven Approach
Dec 01, 2024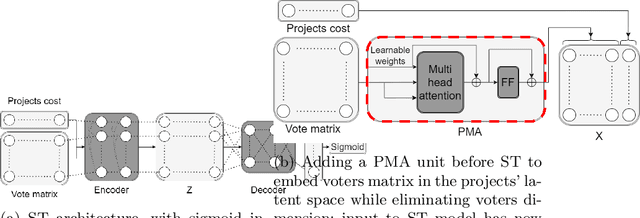


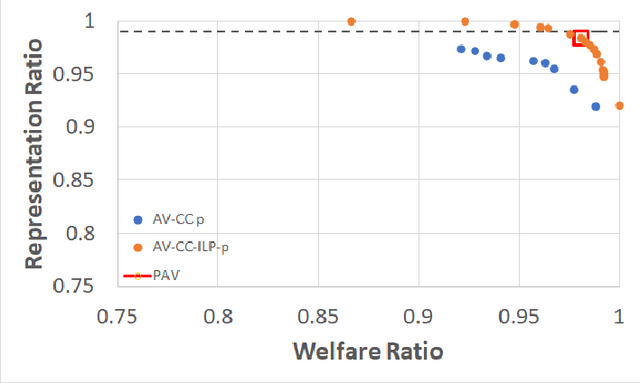
Participatory Budgeting (PB) offers a democratic process for communities to allocate public funds across various projects through voting. In practice, PB organizers face challenges in selecting aggregation rules either because they are not familiar with the literature and the exact details of every existing rule or because no existing rule echoes their expectations. This paper presents a novel data-driven approach utilizing machine learning to address this challenge. By training neural networks on PB instances, our approach learns aggregation rules that balance social welfare, representation, and other societal beneficial goals. It is able to generalize from small-scale synthetic PB examples to large, real-world PB instances. It is able to learn existing aggregation rules but also generate new rules that adapt to diverse objectives, providing a more nuanced, compromise-driven solution for PB processes. The effectiveness of our approach is demonstrated through extensive experiments with synthetic and real-world PB data, and can expand the use and deployment of PB solutions.
Data Augmentation for Modeling Human Personality: The Dexter Machine
Jan 20, 2023Modeling human personality is important for several AI challenges, from the engineering of artificial psychotherapists to the design of persona bots. However, the field of computational personality analysis heavily relies on labeled data, which may be expensive, difficult or impossible to get. This problem is amplified when dealing with rare personality types or disorders (e.g., the anti-social psychopathic personality disorder). In this context, we developed a text-based data augmentation approach for human personality (PEDANT). PEDANT doesn't rely on the common type of labeled data but on the generative pre-trained model (GPT) combined with domain expertise. Testing the methodology on three different datasets, provides results that support the quality of the generated data.
Revisiting Information Cascades in Online Social Networks
Aug 01, 2022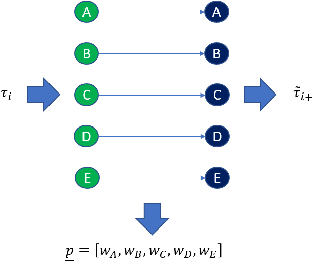


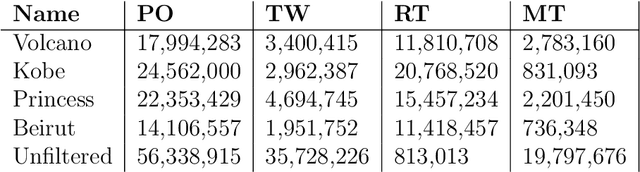
It's by now folklore that to understand the activity pattern of a user in an online social network (OSN) platform, one needs to look at his friends or the ones he follows. The common perception is that these friends exert influence on the user, effecting his decision whether to re-share content or not. Hinging upon this intuition, a variety of models were developed to predict how information propagates in OSN, similar to the way infection spreads in the population. In this paper, we revisit this world view and arrive at new conclusions. Given a set of users $V$, we study the task of predicting whether a user $u \in V$ will re-share content by some $v \in V$ at the following time window given the activity of all the users in $V$ in the previous time window. We design several algorithms for this task, ranging from a simple greedy algorithm that only learns $u$'s conditional probability distribution, ignoring the rest of $V$, to a convolutional neural network-based algorithm that receives the activity of all of $V$, but does not receive explicitly the social link structure. We tested our algorithms on four datasets that we collected from Twitter, each revolving around a different popular topic in 2020. The best performance, average F1-score of 0.86 over the four datasets, was achieved by the convolutional neural network. The simple, social-link ignorant, algorithm achieved an average F1-score of 0.78.
Opinion Spam Detection: A New Approach Using Machine Learning and Network-Based Algorithms
May 26, 2022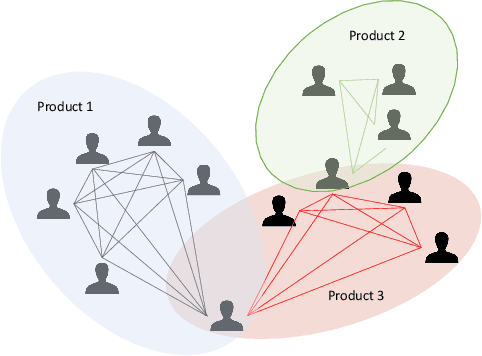
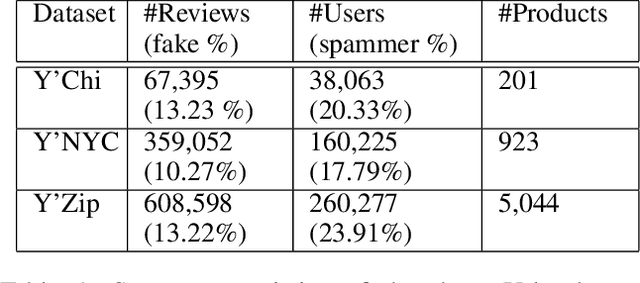
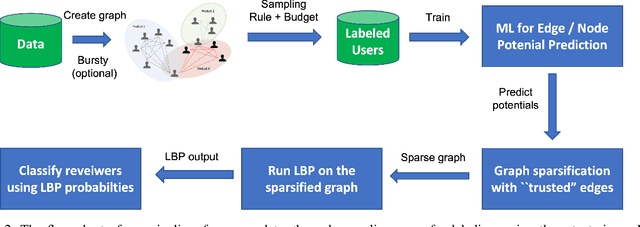
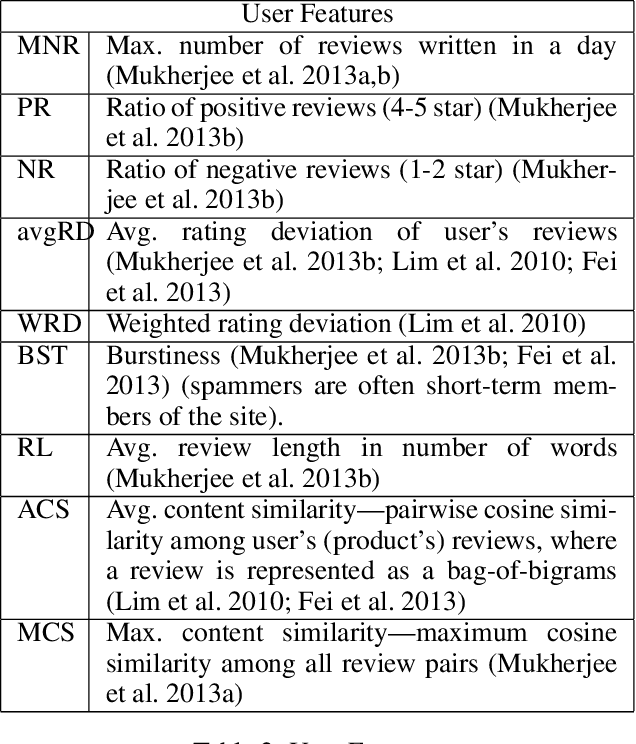
E-commerce is the fastest-growing segment of the economy. Online reviews play a crucial role in helping consumers evaluate and compare products and services. As a result, fake reviews (opinion spam) are becoming more prevalent and negatively impacting customers and service providers. There are many reasons why it is hard to identify opinion spammers automatically, including the absence of reliable labeled data. This limitation precludes an off-the-shelf application of a machine learning pipeline. We propose a new method for classifying reviewers as spammers or benign, combining machine learning with a message-passing algorithm that capitalizes on the users' graph structure to compensate for the possible scarcity of labeled data. We devise a new way of sampling the labels for the training step (active learning), replacing the typical uniform sampling. Experiments on three large real-world datasets from Yelp.com show that our method outperforms state-of-the-art active learning approaches and also machine learning methods that use a much larger set of labeled data for training.
STEM: Unsupervised STructural EMbedding for Stance Detection
Dec 20, 2021
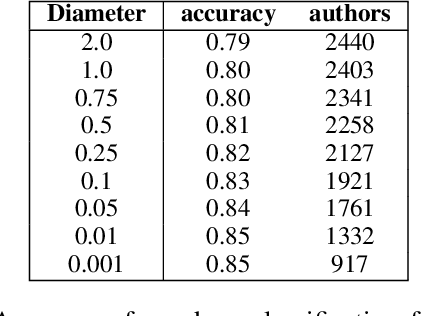
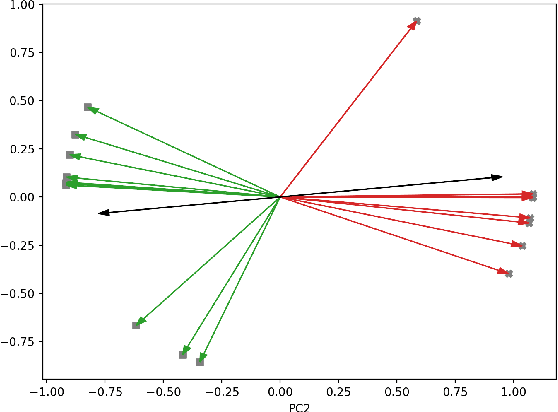
Stance detection is an important task, supporting many downstream tasks such as discourse parsing and modeling the propagation of fake news, rumors, and science denial. In this paper, we propose a novel framework for stance detection. Our framework is unsupervised and domain-independent. Given a claim and a multi-participant discussion - we construct the interaction network from which we derive topological embedding for each speaker. These speaker embedding enjoy the following property: speakers with the same stance tend to be represented by similar vectors, while antipodal vectors represent speakers with opposing stances. These embedding are then used to divide the speakers into stance-partitions. We evaluate our method on three different datasets from different platforms. Our method outperforms or is comparable with supervised models while providing confidence levels for its output. Furthermore, we demonstrate how the structural embedding relate to the valence expressed by the speakers. Finally, we discuss some limitations inherent to the framework.
A greedy anytime algorithm for sparse PCA
Nov 10, 2019
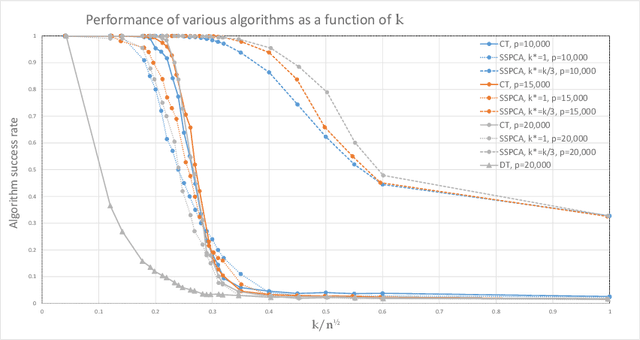
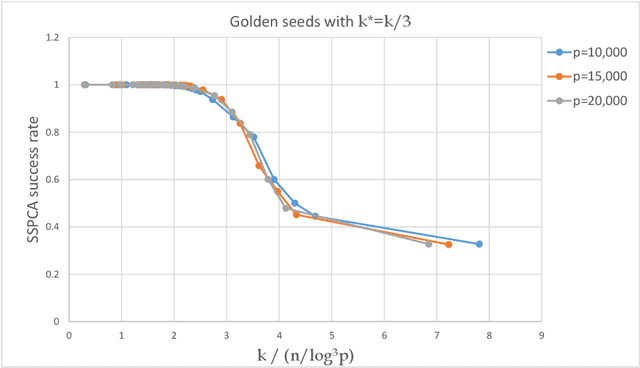
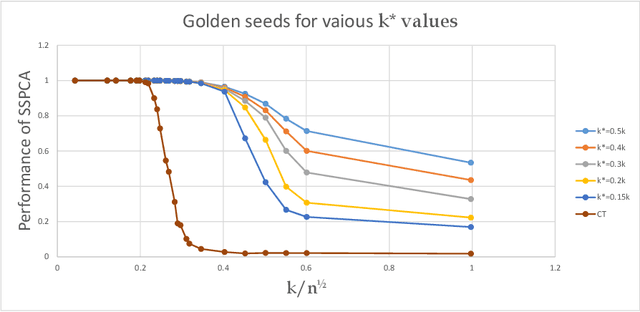
The taxing computational effort that is involved in solving some high-dimensional statistical problems, in particular problems involving non-convex optimization, has popularized the development and analysis of algorithms that run efficiently (polynomial-time) but with no general guarantee on statistical consistency. In light of the ever-increasing compute power and decreasing costs, perhaps a more useful characterization of algorithms is by their ability to calibrate the invested computational effort with the statistical features of the input at hand. For example, design an algorithm that always guarantees consistency by increasing the run-time as the SNR weakens. We exemplify this principle in the $\ell_0$-sparse PCA problem. We propose a new greedy algorithm to solve sparse PCA that supports such a calibration. We analyze it in the well-known spiked-covariance model for various SNR regimes. In particular, our findings suggest that our algorithm recovers the spike in SNR regimes where all polynomial-time algorithms fail, while running much faster than the naive exhaustive search.
Do semidefinite relaxations solve sparse PCA up to the information limit?
Jun 03, 2015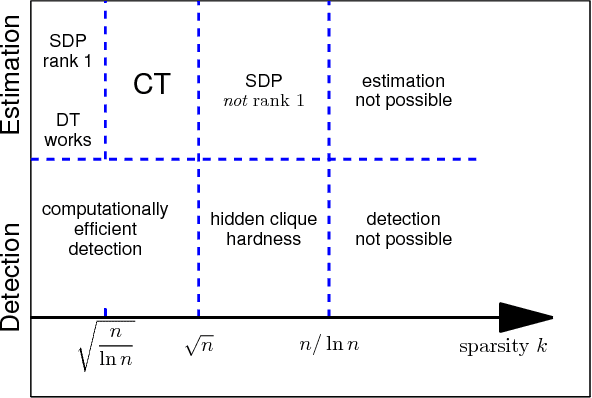
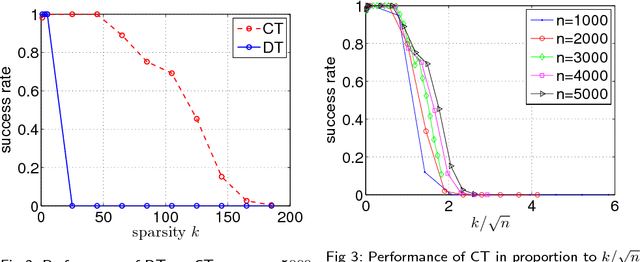
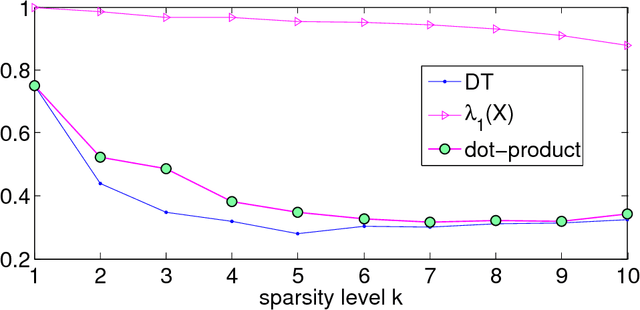
Estimating the leading principal components of data, assuming they are sparse, is a central task in modern high-dimensional statistics. Many algorithms were developed for this sparse PCA problem, from simple diagonal thresholding to sophisticated semidefinite programming (SDP) methods. A key theoretical question is under what conditions can such algorithms recover the sparse principal components? We study this question for a single-spike model with an $\ell_0$-sparse eigenvector, in the asymptotic regime as dimension $p$ and sample size $n$ both tend to infinity. Amini and Wainwright [Ann. Statist. 37 (2009) 2877-2921] proved that for sparsity levels $k\geq\Omega(n/\log p)$, no algorithm, efficient or not, can reliably recover the sparse eigenvector. In contrast, for $k\leq O(\sqrt{n/\log p})$, diagonal thresholding is consistent. It was further conjectured that an SDP approach may close this gap between computational and information limits. We prove that when $k\geq\Omega(\sqrt{n})$, the proposed SDP approach, at least in its standard usage, cannot recover the sparse spike. In fact, we conjecture that in the single-spike model, no computationally-efficient algorithm can recover a spike of $\ell_0$-sparsity $k\geq\Omega(\sqrt{n})$. Finally, we present empirical results suggesting that up to sparsity levels $k=O(\sqrt{n})$, recovery is possible by a simple covariance thresholding algorithm.
* Published at http://dx.doi.org/10.1214/15-AOS1310 in the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
A Spectral Approach to Analyzing Belief Propagation for 3-Coloring
Dec 02, 2007
Contributing to the rigorous understanding of BP, in this paper we relate the convergence of BP to spectral properties of the graph. This encompasses a result for random graphs with a ``planted'' solution; thus, we obtain the first rigorous result on BP for graph coloring in the case of a complex graphical structure (as opposed to trees). In particular, the analysis shows how Belief Propagation breaks the symmetry between the $3!$ possible permutations of the color classes.