 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslate or Simplify First: An Analysis of Cross-lingual Text Simplification in English and French
Apr 26, 2026Cross-Lingual Text Simplification (CLTS) aims to make content more accessible across languages by simultaneously addressing both linguistic complexity and translation. This study investigates the effectiveness of different prompting strategies for CLTS between English and French using large language models (LLMs). We examine five distinct prompting systems: a direct prompt instructing the LLM to perform both translation and simplification simultaneously, two Composition approaches that either translate-then-simplify or simplify-then-translate within a single prompt, and two decomposition approaches that perform the same operations in separate, consecutive prompts. These systems are evaluated across a diverse set of five corpora of different genres (Wikipedia and medical texts) using seven state-of-the-art LLMs. Output quality is assessed through a multi-faceted evaluation framework comprising automatic metrics, comprehensive linguistic feature analysis, and human evaluation of simplicity and meaning preservation. Our findings reveal that while direct prompting consistently achieves the highest BLEU scores, indicating meaning fidelity, Translate-then-Simplify approaches demonstrate the highest simplicity, as measured by the linguistic features.
Not Your Typical Sycophant: The Elusive Nature of Sycophancy in Large Language Models
Jan 26, 2026We propose a novel way to evaluate sycophancy of LLMs in a direct and neutral way, mitigating various forms of uncontrolled bias, noise, or manipulative language, deliberately injected to prompts in prior works. A key novelty in our approach is the use of LLM-as-a-judge, evaluation of sycophancy as a zero-sum game in a bet setting. Under this framework, sycophancy serves one individual (the user) while explicitly incurring cost on another. Comparing four leading models - Gemini 2.5 Pro, ChatGpt 4o, Mistral-Large-Instruct-2411, and Claude Sonnet 3.7 - we find that while all models exhibit sycophantic tendencies in the common setting, in which sycophancy is self-serving to the user and incurs no cost on others, Claude and Mistral exhibit "moral remorse" and over-compensate for their sycophancy in case it explicitly harms a third party. Additionally, we observed that all models are biased toward the answer proposed last. Crucially, we find that these two phenomena are not independent; sycophancy and recency bias interact to produce `constructive interference' effect, where the tendency to agree with the user is exacerbated when the user's opinion is presented last.
Social Hatred: Efficient Multimodal Detection of Hatemongers
Jun 24, 2025Automatic detection of online hate speech serves as a crucial step in the detoxification of the online discourse. Moreover, accurate classification can promote a better understanding of the proliferation of hate as a social phenomenon. While most prior work focus on the detection of hateful utterances, we argue that focusing on the user level is as important, albeit challenging. In this paper we consider a multimodal aggregative approach for the detection of hate-mongers, taking into account the potentially hateful texts, user activity, and the user network. Evaluating our method on three unique datasets X (Twitter), Gab, and Parler we show that processing a user's texts in her social context significantly improves the detection of hate mongers, compared to previously used text and graph-based methods. We offer comprehensive set of results obtained in different experimental settings as well as qualitative analysis of illustrative cases. Our method can be used to improve the classification of coded messages, dog-whistling, and racial gas-lighting, as well as to inform intervention measures. Moreover, we demonstrate that our multimodal approach performs well across very different content platforms and over large datasets and networks.
The Value of Nothing: Multimodal Extraction of Human Values Expressed by TikTok Influencers
Jan 20, 2025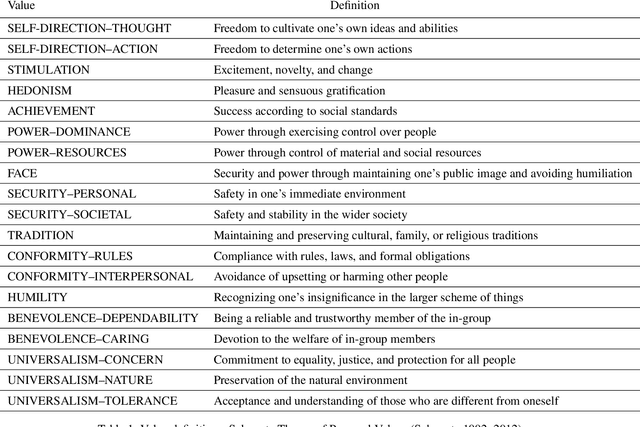
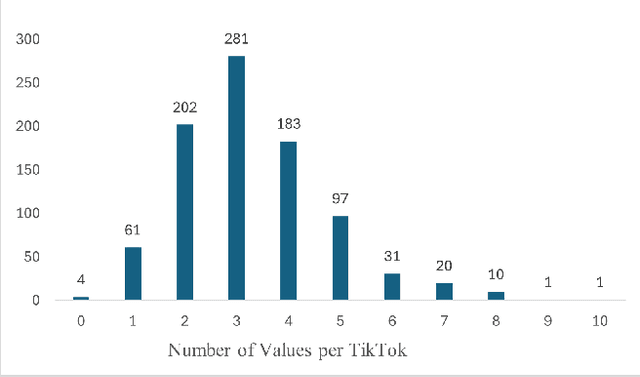
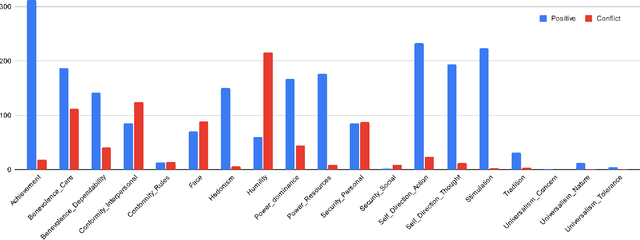

Societal and personal values are transmitted to younger generations through interaction and exposure. Traditionally, children and adolescents learned values from parents, educators, or peers. Nowadays, social platforms serve as a significant channel through which youth (and adults) consume information, as the main medium of entertainment, and possibly the medium through which they learn different values. In this paper we extract implicit values from TikTok movies uploaded by online influencers targeting children and adolescents. We curated a dataset of hundreds of TikTok movies and annotated them according to the Schwartz Theory of Personal Values. We then experimented with an array of Masked and Large language model, exploring how values can be detected. Specifically, we considered two pipelines -- direct extraction of values from video and a 2-step approach in which videos are first converted to elaborated scripts and then values are extracted. Achieving state-of-the-art results, we find that the 2-step approach performs significantly better than the direct approach and that using a trainable Masked Language Model as a second step significantly outperforms a few-shot application of a number of Large Language Models. We further discuss the impact of fine-tuning and compare the performance of the different models on identification of values present or contradicted in the TikTok. Finally, we share the first values-annotated dataset of TikTok videos. Our results pave the way to further research on influence and value transmission in video-based social platforms.
Acquired TASTE: Multimodal Stance Detection with Textual and Structural Embeddings
Dec 04, 2024Stance detection plays a pivotal role in enabling an extensive range of downstream applications, from discourse parsing to tracing the spread of fake news and the denial of scientific facts. While most stance classification models rely on textual representation of the utterance in question, prior work has demonstrated the importance of the conversational context in stance detection. In this work we introduce TASTE -- a multimodal architecture for stance detection that harmoniously fuses Transformer-based content embedding with unsupervised structural embedding. Through the fine-tuning of a pretrained transformer and the amalgamation with social embedding via a Gated Residual Network (GRN) layer, our model adeptly captures the complex interplay between content and conversational structure in determining stance. TASTE achieves state-of-the-art results on common benchmarks, significantly outperforming an array of strong baselines. Comparative evaluations underscore the benefits of social grounding -- emphasizing the criticality of concurrently harnessing both content and structure for enhanced stance detection.
AggregHate: An Efficient Aggregative Approach for the Detection of Hatemongers on Social Platforms
Sep 22, 2024Automatic detection of online hate speech serves as a crucial step in the detoxification of the online discourse. Moreover, accurate classification can promote a better understanding of the proliferation of hate as a social phenomenon. While most prior work focus on the detection of hateful utterances, we argue that focusing on the user level is as important, albeit challenging. In this paper we consider a multimodal aggregative approach for the detection of hate-mongers, taking into account the potentially hateful texts, user activity, and the user network. We evaluate our methods on three unique datasets X (Twitter), Gab, and Parler showing that a processing a user's texts in her social context significantly improves the detection of hate mongers, compared to previously used text and graph-based methods. Our method can be then used to improve the classification of coded messages, dog-whistling, and racial gas-lighting, as well as inform intervention measures. Moreover, our approach is highly efficient even for very large datasets and networks.
With Flying Colors: Predicting Community Success in Large-scale Collaborative Campaigns
Jul 18, 2023

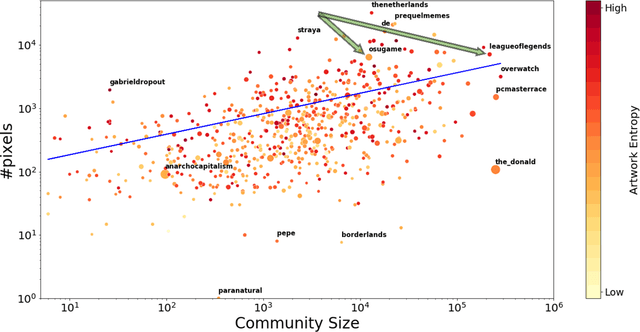

Online communities develop unique characteristics, establish social norms, and exhibit distinct dynamics among their members. Activity in online communities often results in concrete ``off-line'' actions with a broad societal impact (e.g., political street protests and norms related to sexual misconduct). While community dynamics, information diffusion, and online collaborations have been widely studied in the past two decades, quantitative studies that measure the effectiveness of online communities in promoting their agenda are scarce. In this work, we study the correspondence between the effectiveness of a community, measured by its success level in a competitive online campaign, and the underlying dynamics between its members. To this end, we define a novel task: predicting the success level of online communities in Reddit's r/place - a large-scale distributed experiment that required collaboration between community members. We consider an array of definitions for success level; each is geared toward different aspects of collaborative achievement. We experiment with several hybrid models, combining various types of features. Our models significantly outperform all baseline models over all definitions of `success level'. Analysis of the results and the factors that contribute to the success of coordinated campaigns can provide a better understanding of the resilience or the vulnerability of communities to online social threats such as election interference or anti-science trends. We make all data used for this study publicly available for further research.
A Deeper Approach to Non-Convergent Discourse Parsing
May 21, 2023Online social platforms provide a bustling arena for information-sharing and for multi-party discussions. Various frameworks for dialogic discourse parsing were developed and used for the processing of discussions and for predicting the productivity of a dialogue. However, most of these frameworks are not suitable for the analysis of contentious discussions that are commonplace in many online platforms. A novel multi-label scheme for contentious dialog parsing was recently introduced by Zakharov et al. (2021). While the schema is well developed, the computational approach they provide is both naive and inefficient, as a different model (architecture) using a different representation of the input, is trained for each of the 31 tags in the annotation scheme. Moreover, all their models assume full knowledge of label collocations and context, which is unlikely in any realistic setting. In this work, we present a unified model for Non-Convergent Discourse Parsing that does not require any additional input other than the previous dialog utterances. We fine-tuned a RoBERTa backbone, combining embeddings of the utterance, the context and the labels through GRN layers and an asymmetric loss function. Overall, our model achieves results comparable with SOTA, without using label collocation and without training a unique architecture/model for each label.
Detecting Suicide Risk in Online Counseling Services: A Study in a Low-Resource Language
Sep 11, 2022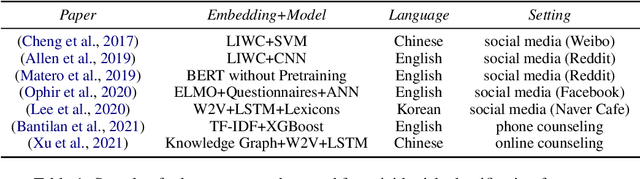
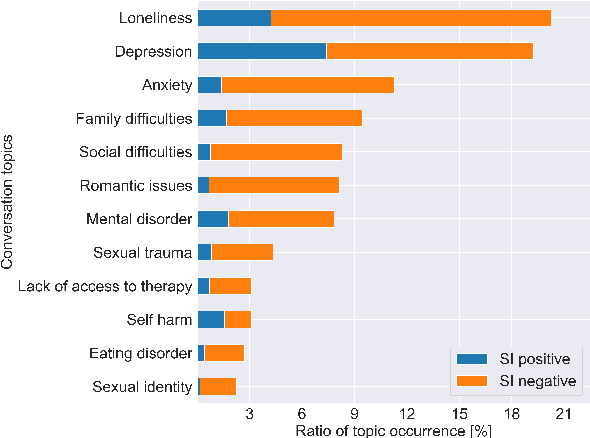

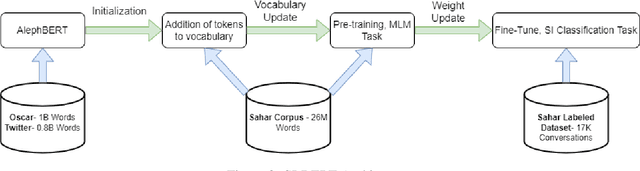
With the increased awareness of situations of mental crisis and their societal impact, online services providing emergency support are becoming commonplace in many countries. Computational models, trained on discussions between help-seekers and providers, can support suicide prevention by identifying at-risk individuals. However, the lack of domain-specific models, especially in low-resource languages, poses a significant challenge for the automatic detection of suicide risk. We propose a model that combines pre-trained language models (PLM) with a fixed set of manually crafted (and clinically approved) set of suicidal cues, followed by a two-stage fine-tuning process. Our model achieves 0.91 ROC-AUC and an F2-score of 0.55, significantly outperforming an array of strong baselines even early on in the conversation, which is critical for real-time detection in the field. Moreover, the model performs well across genders and age groups.
This Must Be the Place: Predicting Engagement of Online Communities in a Large-scale Distributed Campaign
Feb 06, 2022
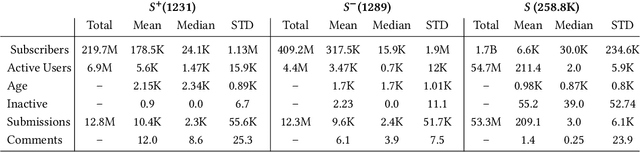
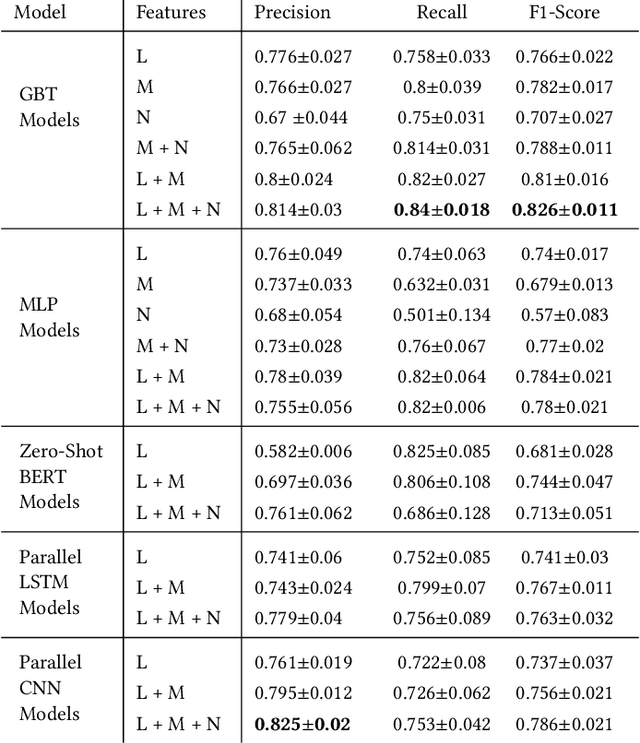
Understanding collective decision making at a large-scale, and elucidating how community organization and community dynamics shape collective behavior are at the heart of social science research. In this work we study the behavior of thousands of communities with millions of active members. We define a novel task: predicting which community will undertake an unexpected, large-scale, distributed campaign. To this end, we develop a hybrid model, combining textual cues, community meta-data, and structural properties. We show how this multi-faceted model can accurately predict large-scale collective decision-making in a distributed environment. We demonstrate the applicability of our model through Reddit's r/place - a large-scale online experiment in which millions of users, self-organized in thousands of communities, clashed and collaborated in an effort to realize their agenda. Our hybrid model achieves a high F1 prediction score of 0.826. We find that coarse meta-features are as important for prediction accuracy as fine-grained textual cues, while explicit structural features play a smaller role. Interpreting our model, we provide and support various social insights about the unique characteristics of the communities that participated in the \r/place experiment. Our results and analysis shed light on the complex social dynamics that drive collective behavior, and on the factors that propel user coordination. The scale and the unique conditions of the \rp~experiment suggest that our findings may apply in broader contexts, such as online activism, (countering) the spread of hate speech and reducing political polarization. The broader applicability of the model is demonstrated through an extensive analysis of the WallStreetBets community, their role in r/place and four years later, in the GameStop short squeeze campaign of 2021.