 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Struggling Student Programmers using Proficiency Taxonomies
Aug 24, 2025Early detection of struggling student programmers is crucial for providing them with personalized support. While multiple AI-based approaches have been proposed for this problem, they do not explicitly reason about students' programming skills in the model. This study addresses this gap by developing in collaboration with educators a taxonomy of proficiencies that categorizes how students solve coding tasks and is embedded in the detection model. Our model, termed the Proficiency Taxonomy Model (PTM), simultaneously learns the student's coding skills based on their coding history and predicts whether they will struggle on a new task. We extensively evaluated the effectiveness of the PTM model on two separate datasets from introductory Java and Python courses for beginner programmers. Experimental results demonstrate that PTM outperforms state-of-the-art models in predicting struggling students. The paper showcases the potential of combining structured insights from teachers for early identification of those needing assistance in learning to code.
Learning Aggregation Rules in Participatory Budgeting: A Data-Driven Approach
Dec 01, 2024


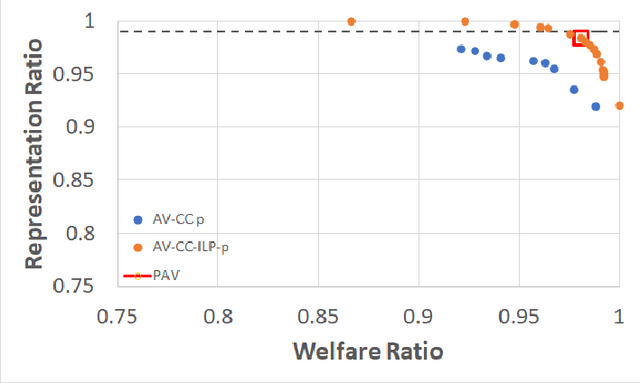
Participatory Budgeting (PB) offers a democratic process for communities to allocate public funds across various projects through voting. In practice, PB organizers face challenges in selecting aggregation rules either because they are not familiar with the literature and the exact details of every existing rule or because no existing rule echoes their expectations. This paper presents a novel data-driven approach utilizing machine learning to address this challenge. By training neural networks on PB instances, our approach learns aggregation rules that balance social welfare, representation, and other societal beneficial goals. It is able to generalize from small-scale synthetic PB examples to large, real-world PB instances. It is able to learn existing aggregation rules but also generate new rules that adapt to diverse objectives, providing a more nuanced, compromise-driven solution for PB processes. The effectiveness of our approach is demonstrated through extensive experiments with synthetic and real-world PB data, and can expand the use and deployment of PB solutions.
Automatic Creativity Measurement in Scratch Programs Across Modalities
Nov 07, 2022Promoting creativity is considered an important goal of education, but creativity is notoriously hard to measure.In this paper, we make the journey fromdefining a formal measure of creativity that is efficientlycomputable to applying the measure in a practical domain. The measure is general and relies on coretheoretical concepts in creativity theory, namely fluency, flexibility, and originality, integratingwith prior cognitive science literature. We adapted the general measure for projects in the popular visual programming language Scratch.We designed a machine learning model for predicting the creativity of Scratch projects, trained and evaluated on human expert creativity assessments in an extensive user study. Our results show that opinions about creativity in Scratch varied widely across experts. The automatic creativity assessment aligned with the assessment of the human experts more than the experts agreed with each other. This is a first step in providing computational models for measuring creativity that can be applied to educational technologies, and to scale up the benefit of creativity education in schools.
Detecting Suicide Risk in Online Counseling Services: A Study in a Low-Resource Language
Sep 11, 2022
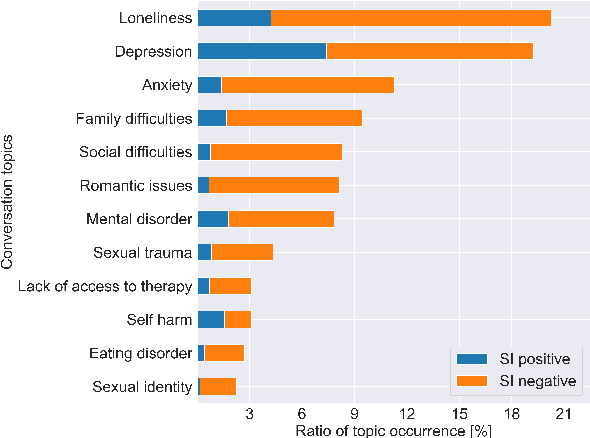

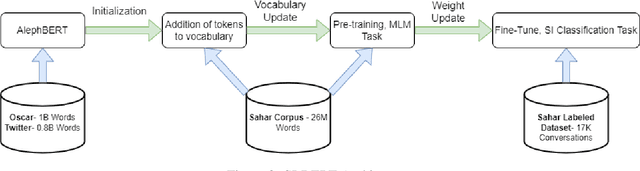
With the increased awareness of situations of mental crisis and their societal impact, online services providing emergency support are becoming commonplace in many countries. Computational models, trained on discussions between help-seekers and providers, can support suicide prevention by identifying at-risk individuals. However, the lack of domain-specific models, especially in low-resource languages, poses a significant challenge for the automatic detection of suicide risk. We propose a model that combines pre-trained language models (PLM) with a fixed set of manually crafted (and clinically approved) set of suicidal cues, followed by a two-stage fine-tuning process. Our model achieves 0.91 ROC-AUC and an F2-score of 0.55, significantly outperforming an array of strong baselines even early on in the conversation, which is critical for real-time detection in the field. Moreover, the model performs well across genders and age groups.
MultiplexNet: Towards Fully Satisfied Logical Constraints in Neural Networks
Nov 02, 2021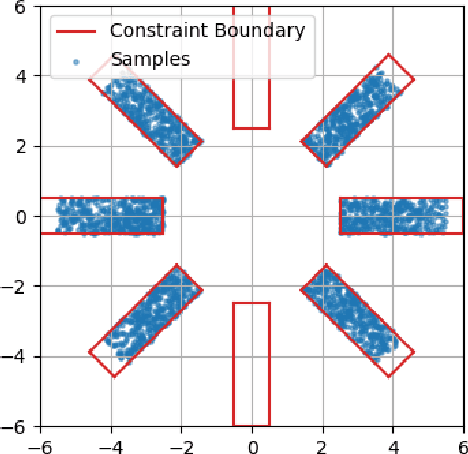
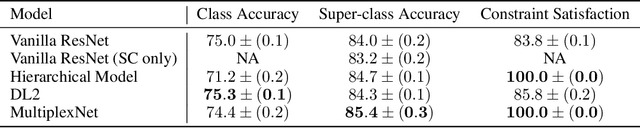
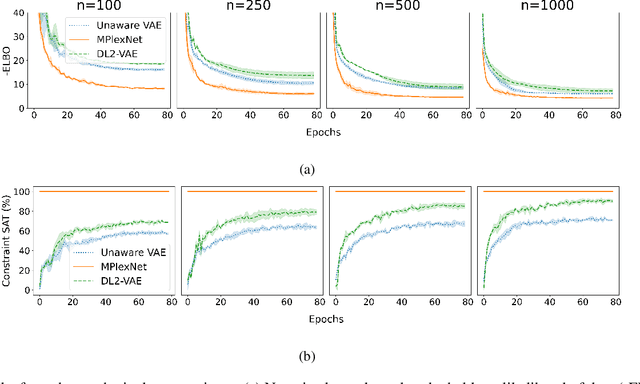

We propose a novel way to incorporate expert knowledge into the training of deep neural networks. Many approaches encode domain constraints directly into the network architecture, requiring non-trivial or domain-specific engineering. In contrast, our approach, called MultiplexNet, represents domain knowledge as a logical formula in disjunctive normal form (DNF) which is easy to encode and to elicit from human experts. It introduces a Categorical latent variable that learns to choose which constraint term optimizes the error function of the network and it compiles the constraints directly into the output of existing learning algorithms. We demonstrate the efficacy of this approach empirically on several classical deep learning tasks, such as density estimation and classification in both supervised and unsupervised settings where prior knowledge about the domains was expressed as logical constraints. Our results show that the MultiplexNet approach learned to approximate unknown distributions well, often requiring fewer data samples than the alternative approaches. In some cases, MultiplexNet finds better solutions than the baselines; or solutions that could not be achieved with the alternative approaches. Our contribution is in encoding domain knowledge in a way that facilitates inference that is shown to be both efficient and general; and critically, our approach guarantees 100% constraint satisfaction in a network's output.
Revisiting Citizen Science Through the Lens of Hybrid Intelligence
Apr 30, 2021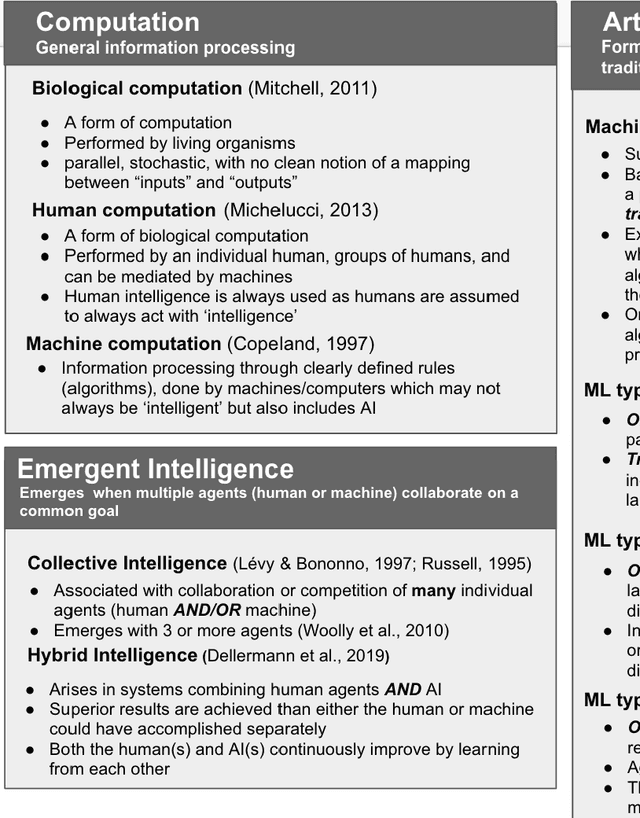
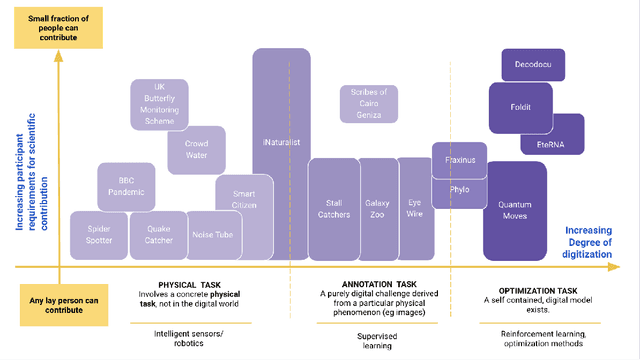
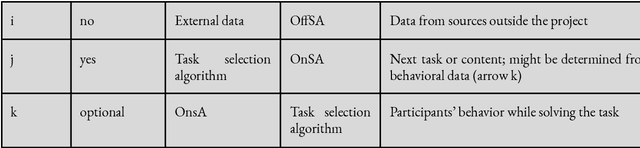
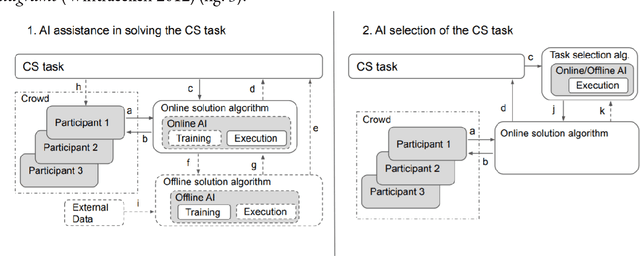
Artificial Intelligence (AI) can augment and sometimes even replace human cognition. Inspired by efforts to value human agency alongside productivity, we discuss the benefits of solving Citizen Science (CS) tasks with Hybrid Intelligence (HI), a synergetic mixture of human and artificial intelligence. Currently there is no clear framework or methodology on how to create such an effective mixture. Due to the unique participant-centered set of values and the abundance of tasks drawing upon both human common sense and complex 21st century skills, we believe that the field of CS offers an invaluable testbed for the development of HI and human-centered AI of the 21st century, while benefiting CS as well. In order to investigate this potential, we first relate CS to adjacent computational disciplines. Then, we demonstrate that CS projects can be grouped according to their potential for HI-enhancement by examining two key dimensions: the level of digitization and the amount of knowledge or experience required for participation. Finally, we propose a framework for types of human-AI interaction in CS based on established criteria of HI. This "HI lens" provides the CS community with an overview of several ways to utilize the combination of AI and human intelligence in their projects. It also allows the AI community to gain ideas on how developing AI in CS projects can further their own field.
Personalization in Human-AI Teams: Improving the Compatibility-Accuracy Tradeoff
Apr 05, 2020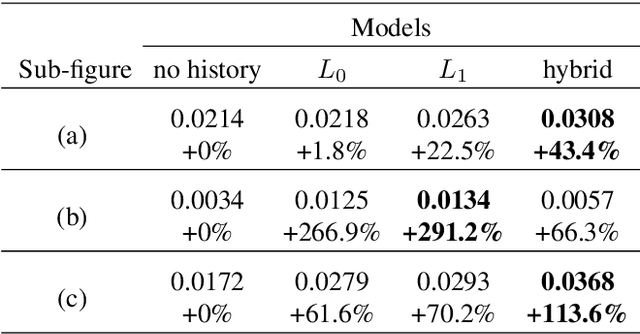
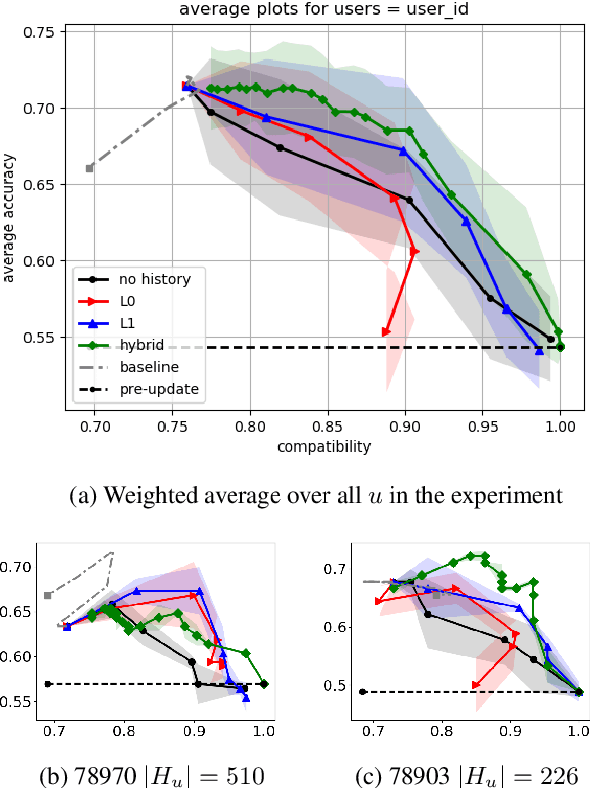
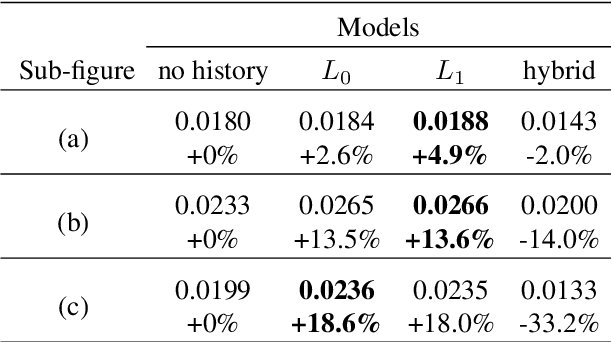
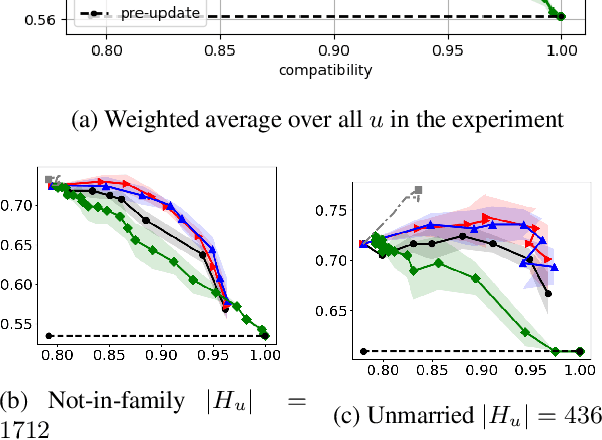
AI systems that model and interact with users can update their models over time to reflect new information and changes in the environment. Although these updates can improve the performance of the AI system, they may actually hurt the performance for individual users. Prior work has studied the trade-off between improving the system accuracy following an update and the compatibility of the update with prior user experience. The more the model is forced to be compatible with prior updates, the higher loss in accuracy it will incur. In this paper, we show that in some cases it is possible to improve this compatibility-accuracy trade-off relative to a specific user by employing new error functions for the AI updates that personalize the weight updates to be compatible with the user's history of interaction with the system and present experimental results indicating that this approach provides major improvements to certain users.
Best Practices for Transparency in Machine Generated Personalization
Apr 02, 2020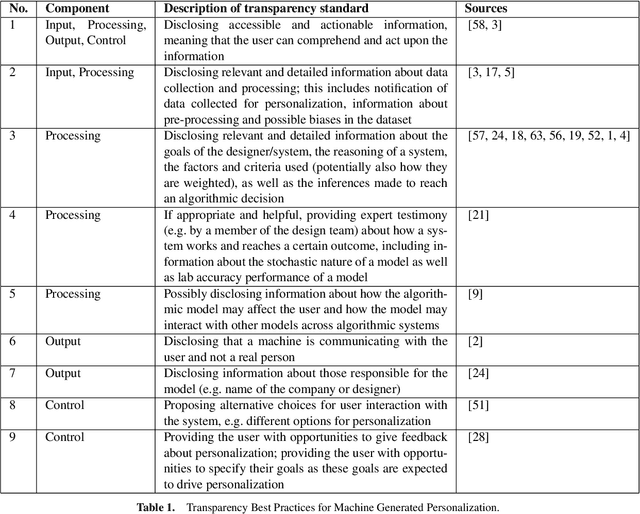
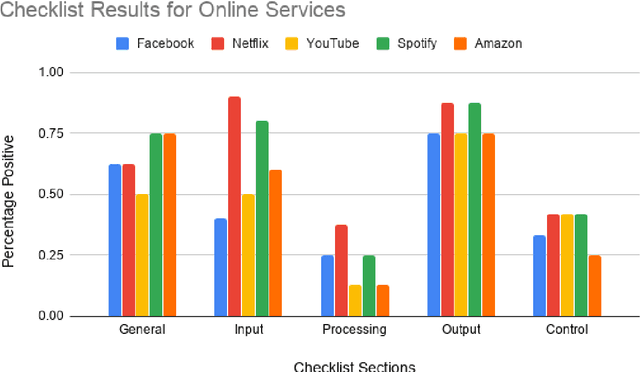
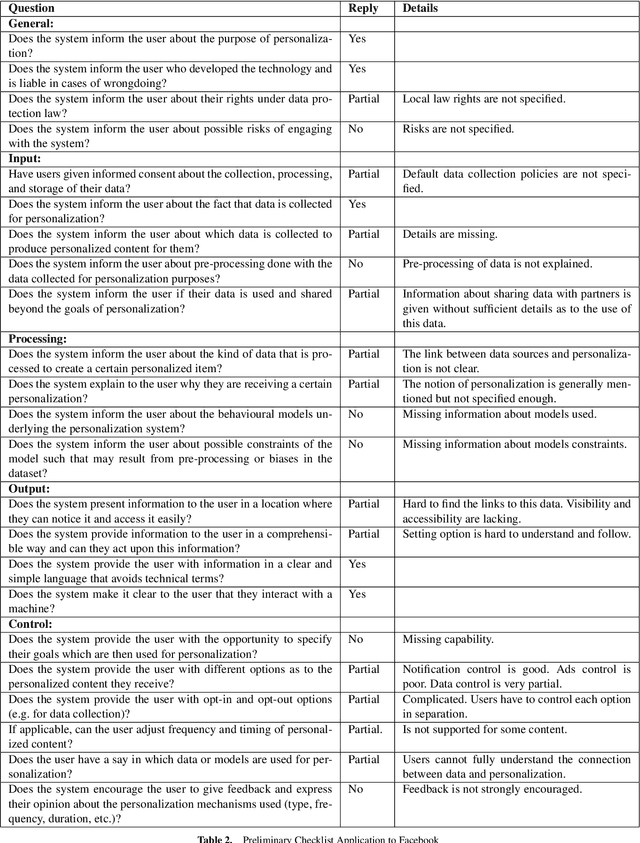
Machine generated personalization is increasingly used in online systems. Personalization is intended to provide users with relevant content, products, and solutions that address their respective needs and preferences. However, users are becoming increasingly vulnerable to online manipulation due to algorithmic advancements and lack of transparency. Such manipulation decreases users' levels of trust, autonomy, and satisfaction concerning the systems with which they interact. Increasing transparency is an important goal for personalization based systems. Unfortunately, system designers lack guidance in assessing and implementing transparency in their developed systems. In this work we combine insights from technology ethics and computer science to generate a list of transparency best practices for machine generated personalization. Based on these best practices, we develop a checklist to be used by designers wishing to evaluate and increase the transparency of their algorithmic systems. Adopting a designer perspective, we apply the checklist to prominent online services and discuss its advantages and shortcomings. We encourage researchers to adopt the checklist in various environments and to work towards a consensus-based tool for measuring transparency in the personalization community.
The Goal-Gradient Hypothesis in Stack Overflow
Feb 14, 2020
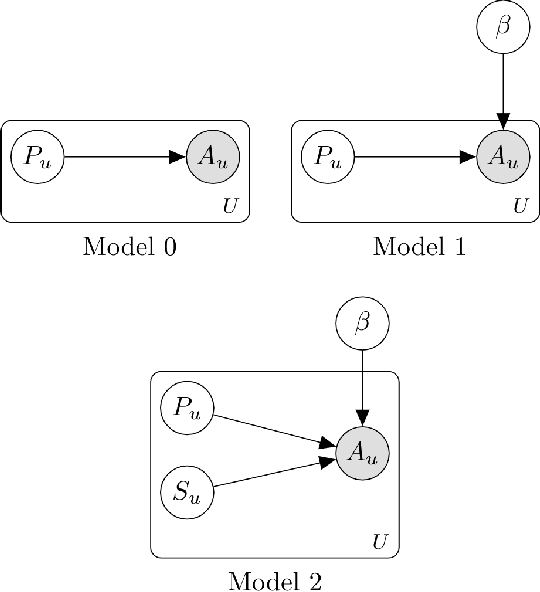

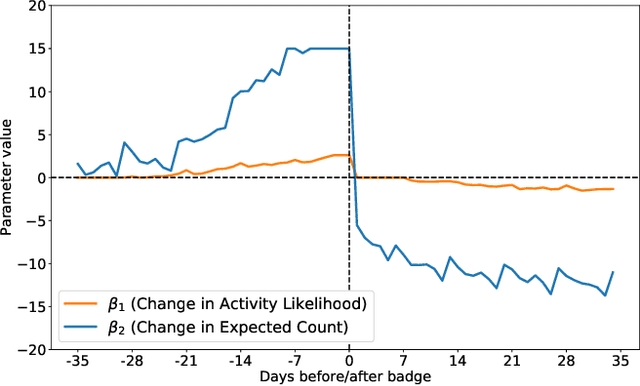
According to the goal-gradient hypothesis, people increase their efforts toward a reward as they close in on the reward. This hypothesis has recently been used to explain users' behavior in online communities that use badges as rewards for completing specific activities. In such settings, users exhibit a "steering effect," a dramatic increase in activity as the users approach a badge threshold, thereby following the predictions made by the goal-gradient hypothesis. This paper provides a new probabilistic model of users' behavior, which captures users who exhibit different levels of steering. We apply this model to data from the popular Q&A site, Stack Overflow, and study users who achieve one of the badges available on this platform. Our results show that only a fraction (20%) of all users strongly experience steering, whereas the activity of more than 40% of badge achievers appears not to be affected by the badge. In particular, we find that for some of the population, an increased activity in and around the badge acquisition date may reflect a statistical artifact rather than steering, as was previously thought in prior work. These results are important for system designers who hope to motivate and guide their users towards certain actions. We have highlighted the need for further studies which investigate what motivations drive the non-steered users to contribute to online communities.
EduBERT: Pretrained Deep Language Models for Learning Analytics
Dec 02, 2019

The use of large pretrained neural networks to create contextualized word embeddings has drastically improved performance on several natural language processing (NLP) tasks. These computationally expensive models have begun to be applied to domain-specific NLP tasks such as re-hospitalization prediction from clinical notes. This paper demonstrates that using large pretrained models produces excellent results on common learning analytics tasks. Pre-training deep language models using student forum data from a wide array of online courses improves performance beyond the state of the art on three text classification tasks. We also show that a smaller, distilled version of our model produces the best results on two of the three tasks while limiting computational cost. We make both models available to the research community at large.